SQL 기초와 데이터 분석
1. 여러 테이블 결합하여 사용하기
1-1 다양한 JOINS
1. JOIN : 두 개 이상의 테이블을 특정 key를 기준으로 결합하는 것
- INNER JOIN : 두 테이블을 조인할 때, 두 테이블에 모두 지정한 열의 데이터가 있어야 한다.
SELECT <열 목록>
FROM <첫 번째 테이블>
INNER JOIN <두 번째 테이블>
ON <조인 조건>
[WHERE 검색 조건]
#INNER JOIN을 JOIN이라고만 써도 INNER JOIN으로 인식합니다.2. OUTER JOIN
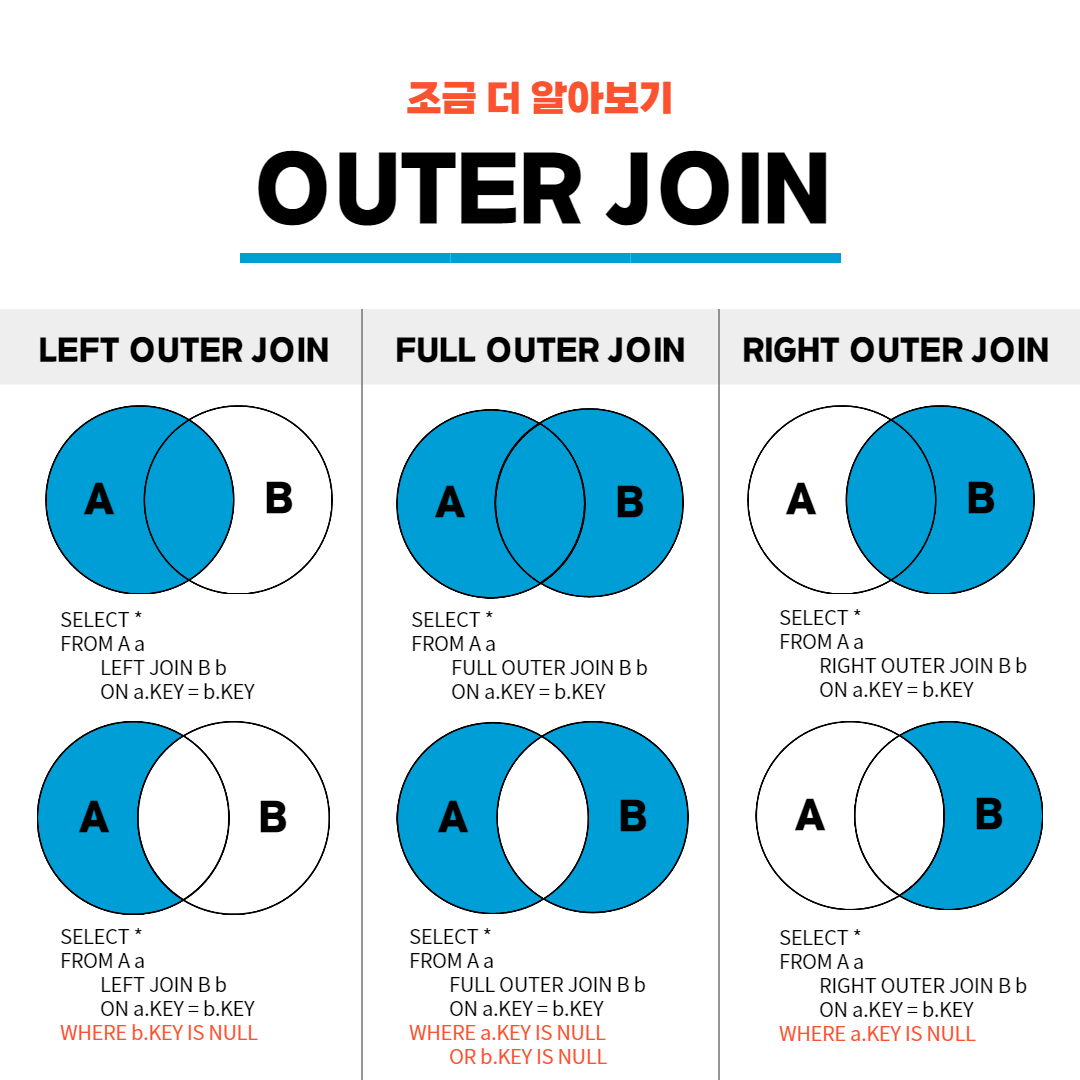
- LEFT JOIN
- RIGHT JOIN
- FULL OUTER JOIN (MySQL지원X, MySQL에서 FULL OUTER JOIN하고 싶으면 LEFT JOIN과 RIGHT JOIN을 UNION해야함)
3. CROSS JOIN (= Cartesian product) : 한쪽 테이블의 모든 행과 다른 쪽 테이블의 모든 행을 조인하는 기능
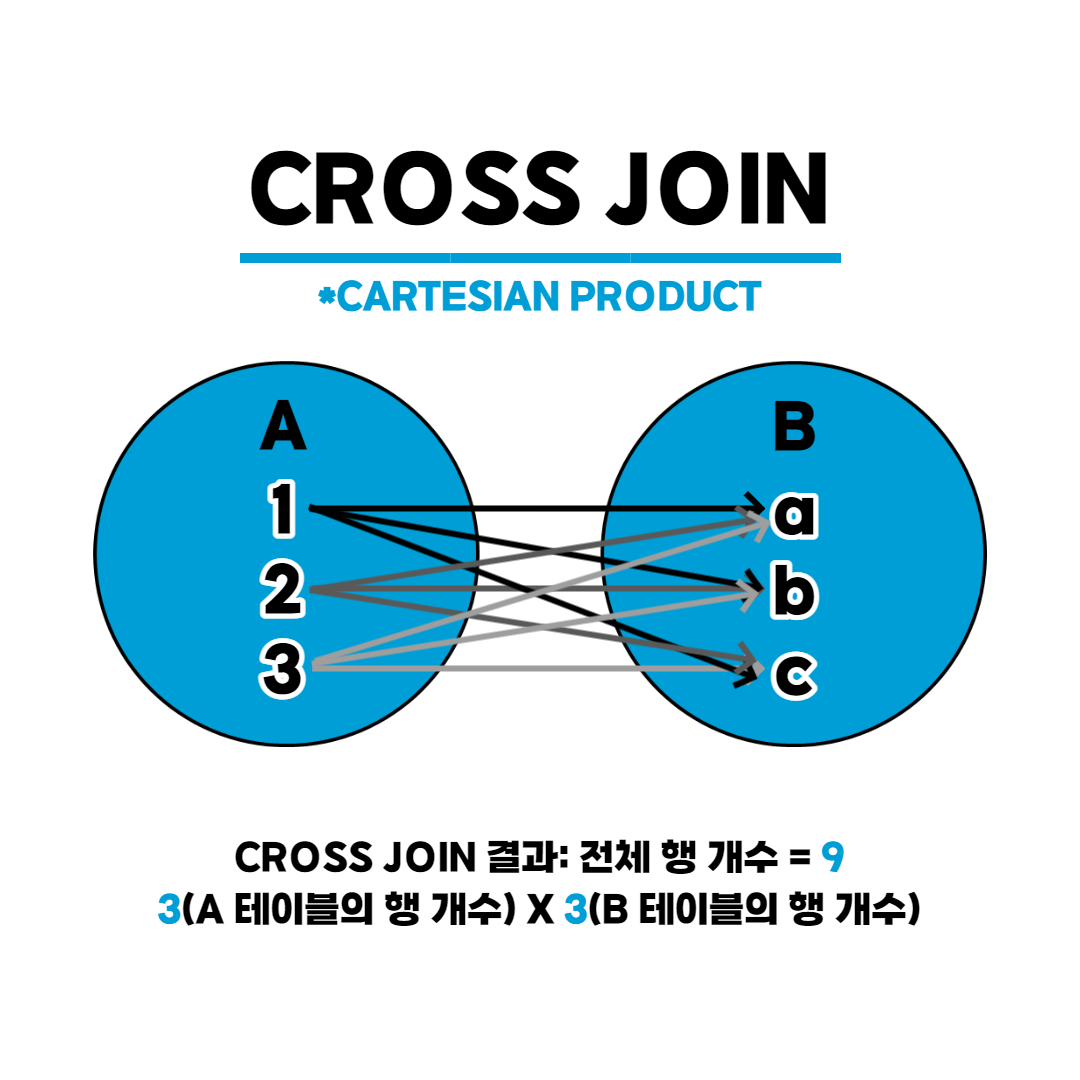
SELECT *
FROM <첫 번째 테이블>
CROSS JOIN <두 번째 테이블>4. SELF JOIN : 자신이 자신과 조인한다는 의미로, 1개의 테이블을 사용한다. Alias 필수로 사용해야 한다.

SELECT <열 목록>
FROM <테이블> 별칭A
INNER JOIN <테이블> 별칭B
[WHERE 검색 조건]필터링
- ON에 사용한 필터링 조건은 JOIN이 일어나기 전에 적용된다. 따라서 한 테이블에만 적용시키는 WHERE의 용도로 쓸 수 있다.
- WHERE은 두 테이블이 먼저 JOIN된 후에 결과 전체에 적용된다.
- 다만 WHERE을 이용하면 NULL값까지 필터링되므로 주의해야 한다.
Alias(=별칭)
- 테이블 Alias로 column을 단순, 명확히 할 수 있다.
- 현재 SELECT 문장에서만 유효
- 테이블 Alias는 길이가 30자까지 가능하나 짧을수록 더욱 좋다.
- 테이블 Alias는 의미가 있어야 한다.
- FROM절에 테이블 Alias 설정시 해당 테이블 Alias는 SELECT문장에서 테이블 이름 대신 사용한다.
- 출처 : http://www.gurubee.net/lecture/1018
1-2 UNION
UNION
- 여러 쿼리문들을 합쳐서 하나의 쿼리문으로 만들어주는 방법
- 중복된 값을 제거
- 중복된 값을 제거하는 연산이 추가로 수행되기 때문에 UNION ALL보다 속도 느림
UNION ALL
- 여러 쿼리문들을 합쳐서 하나의 쿼리문으로 만들어주는 방법
- 중복된 값 모두 보여줌
사용형태
- 컬럼명이 동일해야 한다. (같지 않을 경우 AS를 이용해서 동일하게 맞춰줘야 한다.)
- 컬럼별로 데이터 타입이 동일해야 한다.
- 출력할 컬럼의 개수가 동일해야 한다.
- 출력할 컬럼명을 차례로 적고, Alias를 통해 컬럼명을 동일하게 맞춰준다.
JOIN과 UNION의 차이점
- JOIN : 새로운 열을 결합 (수평결합)
- UNION : 새로운 행을 결합 (수직결합)
1-3 WITH
- CTE(Common Table Expression)라고도 부르며, MySQL 8.0 버전 이상에서 지원
- 임시 결과 집합을 생성하여 복잡한 쿼리를 쉽게 작성할 수 있도록 돕는 기능
- 복잡한 쿼리에서 하위 쿼리를 사용해 같은 결과를 여러번 계산해야 하는 경우를 줄여준다.
- CTE는 같은 쿼리 블록을 여러 번 사용할 수 있도록 함
- 쿼리 가독성을 높여 유지보수를 용이하게 한다.
- DB Optimizer는 CTE를 단순한 뷰나 서브쿼리보다 더 효율적으로 처리한다.
1-4 Subquery
- 다른 테이블의 값을 기준으로 한 테이블에서 데이터를 검색할 수 있도록 다른 쿼리 내부에 중첩된 쿼리
- 괄호 안에 포함되어 있으며 일반적으로 더 큰 쿼리의 일부로 사용
- 서브쿼리를 포함하고 있는 쿼리를 외부쿼리(outer query)라고 부름
- 서브쿼리는 내부쿼리(inner query)라고도 부름
- 외부 쿼리에 지정된 조건 또는 기준에 따라 하나 이상의 테이블에서 데이터를 검색
- 데이터 필터링, 정렬, 또는 그룹화와 같은 다양한 방법으로 사용
- 사용 이점
- 파생 테이블로 사용하여 더 큰 쿼리에서 다른 테이블과 조인
- 집계함수를 계산하거나 데이터의 하위 집합에 대한 다른 계산 수행
- 연관된 서브쿼리에서 서브쿼리를 사용하여 두 테이블의 데이터를 행렬로 비교
- 외부 쿼리에서 직접 엑세스 할 수 없는 테이블에서 데이터를 검색
- 특징
- 쿼리의 SELECT, FROM , WHERE, HAVING 및 JOIN절에서 사용
- 단일 값 또는 값 집합 반환
- =,<,>,IN,NOT IN, EXIST, NOT EXIST 등 다양한 비교 연산자와 함께 사용 가능
- 조인, 집계 함수 및 GROUP BY절을 포함한 모든 유효한 SELECT문을 사용하여 작성 가능
2. 다양한 SQL 함수 다루기
2-1 타임스탬프 함수
SQL에서 날짜와 시간 다루기
- 데이터타입
- STRING : 'yyyy-mm-dd','yyyy-mm-dd HH:MM:SS'
- DATE : yyyy-mm-dd
- DATETIME : YYYY-MM-DD HH:MM:SS
- TIMESTAMP : YYYY-MM-DD HH:MM:SS UTC
현재시간
- NOW() : UTC기준으로 현재 시간을 가져오는 함수
- CURRENT_TIMESTAMP()
- CURTIME() : 현재 시간 반환
- CURRENT_DATE() = CURDATE() : yyyy-mm-dd 형식으로 반환
- SYSDATE() : 함수가 호출된 시간을 반환
- YEAR() : 날짜에서 연도 추출 / MONTH() : 날짜에서 월 추출 / DAY() : 날짜에서 일 추출
- HOUR() / MINUTE() / SECOND()
- WEEKDAY()
- MONTHNAME() / DAYNAME()
날짜 형식화
- STR_TO_DATE : 문자열 타입을 날짜 타입으로 변경
- DATE_FORMAT : 지정된 형식으로 날짜 출력
- %Y : 연도(2023)
- %y : 연도(23)
- %m : 월(11)
- %d : 일(20)
- %H : 시(05), 24시간 형태
- %T : hh:mm:ss
- %s : 초
날짜 연산
- ADDDATE() : 특정 interval 만큼 시간을 더함
- DATE_ADD()
- SUBDATE() : 특정 interval 만큼 시간을 뻄
- DATE_SUB()
- CONVERT_TZ() : 타임존 변경하여 출력
- DATEDIFF() : 두 날짜 간의 차이를 반환
- TIMEDIFF() : 두 시간 간의 차이를 반환
- TIME_TO_SEC() : 시간을 초 단위로 반환
2-2 타입 변환
필요성
- 데이터 타입 불일치로 인한 연산/비교 오류를 피하기 위함
- 다양한 데이터 소스 간의 호환성을 유지하기 위함
- CAST
- CONVERT
2-3 조건문
IF
SELECT price,
IF(price >= 10000, "고가","저가") AS '가격구분'
FROM product➡️ product table에서 price 값이 10000 이상이면 고가, 미만이면 저가로 표시하며 그 값을 '가격구분'칼럼하여, price칼럼과 같이 출력
IFNULL
SELECT user_name, IFNULL(date,20231104) as date
FROM orders_v3➡️ date칼럼에서 null값인 데이터는 20231104로 해서 date칼럼으로, user_name칼럼과 같이 출력해라
CASE WHEN
SELECT price,
CASE WHEN price > 10000 THEH '고기'
WHEN (price <= 10000 AND price > 4000) THEN '중가'
ELSE '저가'
END AS price_class
FROM product_B➡️ price가 10000초과이면 '고가', 10000이하 4000초과이면 '중가', 그 외에는 '저가'로 출력하되 price_class칼럼으로 price와 같이 출력해라
SELECT date,
CASE date
WHEN '20231014' THEN '첫째날'
WHEN '20231015' THEN '둘째날'
ELSE '기타'
END AS date_group
FROM clicks➡️ date컬럼 값이 20231014이면 첫쨰날, 20231015이면 둘째날, 그 외에는 기타로 date_group컬럼으로 date와 같이 출력
2-4 그 외 유용한 함수
RANK() : 순위 함수
- rank() : 중복 순위 개수 만큼 다음 순위 값 증가시킴
- dense_rank() : 중복 순위가 존재해도 순차적으로 다음 순위 값을 표시
- ROW_NUMBER() : 중복 값들에 대해서도 순차적인 순위 표시
- percent_rank() : 인수로 지정한 값의 그룹 내의 위치를 나타내는 백분위 순위를 반환
- NTILE() : 괄호 안에 적는 숫자만큼 등분하는 함수
LEAD() : 기준 데이터의 다음 행위 값을 반환
LEAD(대상 컬럼명) OVER(ORDER BY 대상 컬럼명)LAG() : 기준 데이터의 이전행의 값을 반환
LAG(대상 컬럼명) OVER(ORDER BY 대상 컬럼명)위의 내용은 프로그래머스 데이터분석1기 하홍석 강사님의 강의 자료를 참고하였습니다.
참고 사이트
https://silverji.tistory.com/49
https://luvris2.tistory.com/514
https://dev.mysql.com/doc/refman/8.0/en/date-and-time-functions.html
https://smile-place.tistory.com/entry/ORACLE-LAG-%ED%95%A8%EC%88%98-LEAD-%ED%95%A8%EC%88%98
이미지 출처
https://hongong.hanbit.co.kr/sql-%EA%B8%B0%EB%B3%B8-%EB%AC%B8%EB%B2%95-joininner-outer-cross-self-join/
