
0. Why?
회사에서 graphQL을 사용함에 따라 간간히 공식문서와 니콜라스의 영상을 보며 개발을 하고있던 중
동료 개발자들과의 수다에서 이런 의문이 나왔다.
"우리가 과연 graphQL을 사용한다고 말할 수 있을까요?"
우리는 모두 아니라고 대답했고 제대로 사용하고 있는 것 같지도 않다고 대답했다.
그냥 요청을 보내면 응답을 보내주는 수준이라고 말해 개발팀 모두가 빵터진적도 있었다.
적어도 일주일에 블로그 하나씩 작성하자는 다짐은 밀리고 밀리는 task들에 밀려 지켜지지 못했고
graphQL을 정리해보자라는 생각을 가진지 한달이 지나서야 겨우 글을 끄적이게 되었다.
사실 지금도 일정에 맞춰 개발하기 위해 개발을 해야하지만
그간 graphQL과 Apollo를 겉핧기식으로 알고 사용하면서 한 이슈에 대해서 3시간 혹은 반나절의 시간을 낭비(?)하는 일들도 있었으니
나중을 위한 투자가 되지 않을까 라는 변명으로 잠시 개발을 쉬고 정리를 해보려한다.
GraphQL을 사용해보니 정말 좋은점은, 프론트엔드로서, 너무 편하다. 스키마에 정의된 타입들을 잘 정리해서 정의해주고
원할 떄 쿼리와 뮤테이션을 사용하여 서버와 통신을 하면 끝이다.
(반대로 백엔드에서 정말 과하다 싶을정도로 모든 로직 등등을 다 처리해준다.)
또한 cache 기능, 사용자가 우리 서비스를 사용하는 과정에 있어서 받아와서 사용하는 데이터들 중 그 특정 과정 떄문에 발생하는
데이터의 null 값, 빈값 혹은 undefined 등등의 데이터 값을 처리하는 과정에 있어서 너무나도 편리하게 처리가 가능했다.
REST와 비교하면 정말 편리하다. (페이스북 팀이 Native Mobile App에 사용하기 위해 사용했다는 이유가 너무나도 납득이 된다.)
또한 같이 사용하는 Apollo 라는 상태관리 라이브러리와도 궁합이 너무 좋은데
Apollo client에서 제공해주는 client/cache를 이용하면 사실상 global statemanagement도 가능하다.
거기에 React를 사용하는 개발자로서 hook이 제공된다는 점이 너무나도 좋다.(매일매일 apollo를 향해 절하고 싶은 마음이 들정도로)
이렇게 사용하기 편한만큼 GraphQl 공식문서만 봐도 너무나도 쉽게 사용이 가능하다.
먼저 GraphQL에 대해서 알아보자.
1. GraphQL
GraphQL 은 API를 위한 쿼리 언어이며 타입 시스템을 사용하여 쿼리를 실행하는 서버사이드 런타임입니다.
출처: https://graphql-kr.github.io/learn/
이렇게 공식문서에서 설명해주고 있다. 쉽게 말하자면 언어이자 문법이라고 생각하면 된다.
REST와 가장 큰 차이점은 GraphQL은 단 하나의 endpoint만 가지고 있다는 것이다.
말로 하니 어렵다. 코드로 살펴보자
{
"user" : {
"name" : "Lee",
"age" : 30,
"phoneType": "IPhone"
}
}위와 같은 데이터를 서버로부터 받는다고 가정해보자.
REST API는 아래와 같이 요청할 것이다.
// REST API
fetch('http://example.com/user.json')
.then(response => response.json())
.then(data => console.log(data));GrapQL은 아래와 같이 요청하면 된다.
query {
user {
name
age
phoneType
}
}여기서 큰 차이점이 하나 더 존재한다.
만약 해당 API를 통해서 우리가 필요한 데이터가 name뿐이라고 치자.
그럼 우리는 쓸데없는 age와 phoneType의 데이터도 받아와야한다.
하지만 GraphQL은 name만 뽑아서 받아올 수 있다.
아래처럼
query {
user {
name
}
}Facebook이 gql을 사용하게 된 이유도
1. 커져만 가는 어플리케이션
2. 증가하는 서버로부터 받아오는 데이터의 양
3. 모바일로 서비스를 접속하고 이용하는 사용자가 증가
한다는 점에서 데이터 통신을 가볍게(?)하기 위해서라는 것이 이해가 가는 부분이다.
이렇게 gql 언어를 사용하면 REST와 동일하게 서버로부터 요청을 통해 응답으로 데이터를 받을 수 있다.
그럼 이 언어의 형태와 구성 그리고 문법에 대해서 알아보자.
2. Query & Mutation.
Query와 Mutation은 GraphQL 쿼리 언어로 실행할 수 있는 작업 유형들이다.
이들 외에도 Subscription이라는 작업 유형이 존재한다.
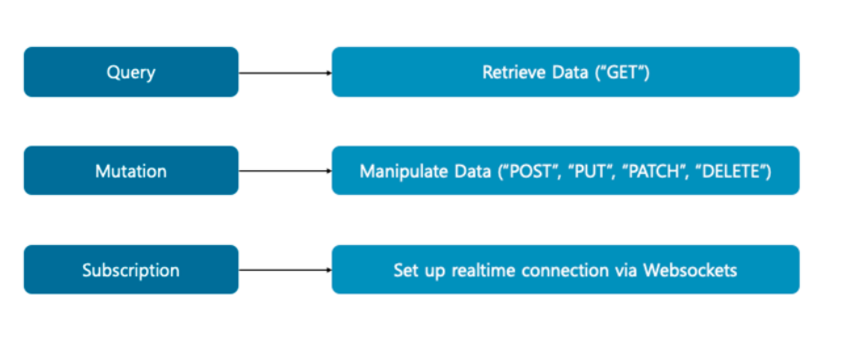
Subscription은 웹소켓을 통한 실시간 양방향 통신을 구현할 때 사용되는데 이는 나중에 웹소켓을 정리하며 같이 정리하도록 하고
Query와 Mutation은 기본 REST API에서 CRUD인 POST, GET, DELETE 등등을 담당한다고 보면된다.
그림에 나와있는 것처럼 Query는 GET, Mutation은 POST, PUT, DELETE 등의 행위를 하는 작업 유형이다.
이들은 Schema와 Docs에 명시된, 일종의 API 명세에 입각하여 작성하면 된다.
실제 Query와 Mutation의 실행에는 상태관리를 도와주는 Apollo Client 라이브러리를 주로 사용하는데
이에 대한 설명과 방법은 다음 블로그에서 하고 이번 블로그에서는 작성법에 초점을 맞춰서 정리해보자.
또한 Query와 Mutation 작업 유형의 실행을 "서버에 쿼리를 날린다" 혹은 "서버에 쿼리를 한다" 라고 통칭으로 사용한다.
따라서 이에 입각하여 쿼리하는 방법에 대해서 알아보자. 그리고 그 전에 Schema와 Docs에 대해서 간단하게 정리를 먼저 해보자.
3. Schema & Docs
Schema와 Docs는 API에 대한 명세라고 봐도 무방하다.
쿼리 요청을 작성함에 있어 형태와 필요 요소가 정리된 문서 라고 생각하면 쉽다.
그래도 말로만하니 뭔지 모르겠다.
예제를 살펴보자.

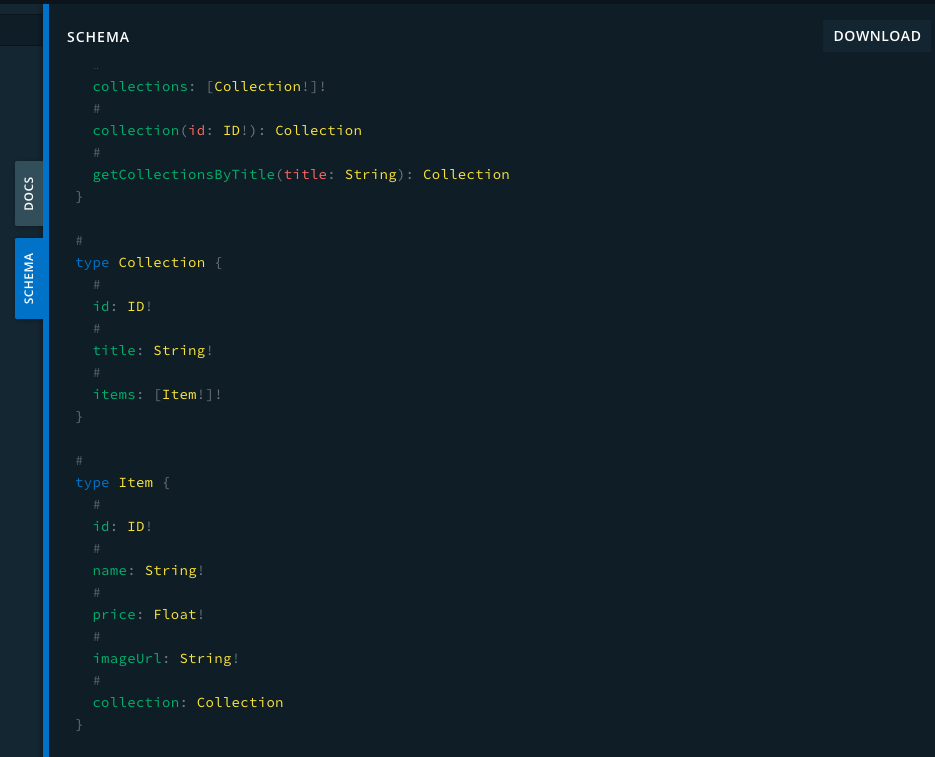
위와 같이 Docs에는 우리가 요청할 수 있는 Fields들의 목록이 나와있다.
그리고 Schema에는 Fields들의 목록과 함께 밑에 Type들이 명세되어 있는데 타입은 Fields들의 return의 형태,요소이자 모습이고
Fields는 우리가 받고자 하는 value의 key값들이라고 생각하면 쉽다.
4. Fields & Types
그래도 말로하니 어렵다. 위에 사용한 예제를 다시 가져와보자.
query {
user {
name
age
phoneType
}
}위와 같이 서버에 쿼리를 하면 다음과 같은 응답이 올 것이다.
{
"user" : {
"name" : "Lee",
"age" : 30,
"phoneType": "IPhone"
}
}위의 예제에서 Fields는 user, name, age 그리고 phoneType이다.
그리고 응답으로 온 Lee, 30, IPhone 그리고 그들을 포함하는 하나의 객체가 Types이다.
이래도 어렵다. 실제 docs와 schema를 살펴보자.
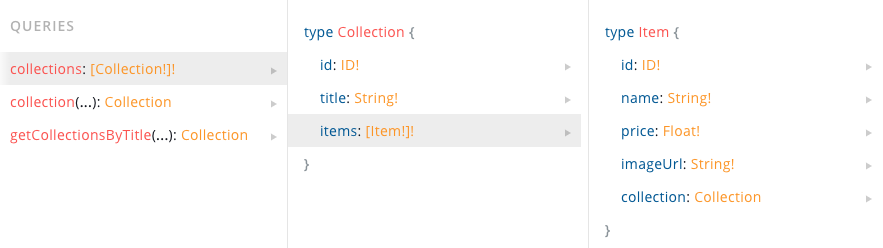
위의 사진에서 첫번째 칼럼에는 총 3개의 Fields가 존재한다. 이들 중 서버에 collections에 해당하는 데이터를 받아오자고 가정해보자.
앞으로 우리가 작성할 요청은 우리가 특정한 fields로 구성된 하나의 객체를 서버로 요청하여 받아오는 것이다.
그렇게 되면
1. collections는 해당 요청의 Field가 되고 이 field는 Collection이라는 GraphQL 객체타입들로 구성된 배열을 리턴한다.
2. 두번째 칼럼에는 Collection 객체타입에 대해 나와있다. 즉 이 객체타입은 필드가 있는 타입으로 스키마는 대부분 객체타입이다.
3. id, title 그리고 items는 Collection 타입의 필드들로서 GraphQL 쿼리의 Collection 타입 어디서든 사용이 가능한 필드다.
4. id와 title 필드가 리턴하는 ID와 String 타입은 Scalar타입으로서 구체적인 데이터로 해석되는 쿼리의 끝이라고 보면 된다. 즉 Collection 타입이 collections필드의 하위 필드로서 존재하는것과 다르게 Scalar타입은 하위 필드가 존재하지 않는 데이터의 값 그 자체인 끝자락이라고 보면 된다. Scalar로서 존재할 수 있는 타입은 공식문서 스키마-스칼라타입에 잘 설명되어 있다.
5. 반면 items필드는 Item 객체의 배열을 나타내고 있다. 즉 하위 필드를 작성해주어야 한다는 뜻이다.
6. 세번째 칼럼을 보면 하위 필드로서 작성가능한 필드들이 명세되어있다. 여기서 데이터 타입뒤의 느낌표는 꼭 작성을 해줘야 하는 필드들이라고 보면 되고 느낌표가 없으면 필요에 의해서만 작성해주면 된다.
역시 말로하니 뭔말인지 모르겠다. 직접 코드를 처보자.
query {
id
title
items {
id
name
price
imageUrl
}
}위와 같이 Docs를 보며 작성하면 된다.
다시 말하지만 서버에 쿼리를 하는 것은 우리가 원하는 데이터들을 하나의 큰 객체안에 Fields로서 작성하여 요청하는 것이다.
위에 대한 응답은 아래와 같을 것이다.
{
"data": {
"collections": [
{
"id": "cjwuuj5bz000i0719rrtw5gqk",
"title": "Hats",
"items": [
{
"id": "cjwuuj5ip000j0719taw0mjdz",
"name": "Brown Brim",
"price": 25,
"imageUrl": "https://i.ibb.co/ZYW3VTp/brown-brim.png"
},
{
"id": "cjwuuj5j4000l0719l3ialwkj",
"name": "Blue Beanie",
"price": 18,
"imageUrl": "https://i.ibb.co/ypkgK0X/blue-beanie.png"
},
{
"id": "cjwuuj5je000n0719ch6nbhik",
"name": "Brown Cowboy",
"price": 35,
"imageUrl": "https://i.ibb.co/QdJwgmp/brown-cowboy.png"
},
{
"id": "cjwuuj5jh000p0719rtjatb2f",
"name": "Grey Brim",
"price": 25,
"imageUrl": "https://i.ibb.co/RjBLWxB/grey-brim.png"
},
...
]
}
]
}
}이게 기본적인 Query와 Mutation이다.
Query와 Mutation은 단지 실행하는 작업 유형이 다를뿐 문법이나 형태는 둘이 동일하다.
그렇다면 어느 정도 감이 잡혔으면 문뜩 의문이 생길 것이다.
만약 특정 id에 해당하는 데이터만 받아오고 싶으면 어떻게할 수 있을까?
5. Arguments
이는 우리가 함수에 인자를 넣어서 해당 인자에 대한 연산의 값이 return되듯이
똑같이 Query와 Mutation에도 적용된다.
위에 쿼리로 받아온 collection 객체의 배열중 첫번째 객체의 정보만 받아오고 싶으면 어떻게 해야할까?
이때 인자를 사용하면 된다.
XX 물론 인자를 사용하는 부분은 apollo client를 사용해서 cache 데이터를 client 부분으로 사용이 가능하지만 이는 나중의 이야기이고 순수하게 사용하려면 백엔드에서 서버가 해당 인자를 인식하여 연산이 되도록 개발이 되어있어야한다. 해당 예제는 인자를 사용하는 로직이 개발이 되었다는 가정하에 정리하는 것XX
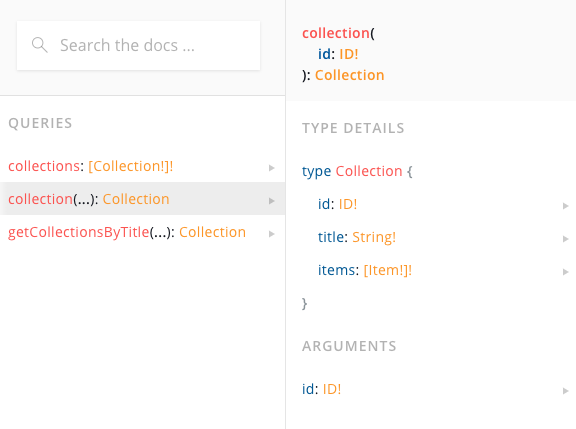
위와 같이 id를 받아 해당 id를 갖는 Collection타입의 필드들만 return 하는 API가 개발되어있다.
우리가 할 일은 저 docs를 보고 단순히 작성해주면 된다.
원하는 id값을 인자로 넣어주고 그 id에 해당하는 데이터 객체중 필요한 field를 작성해주면 된다.
query {
collection (id:"cjwuuprqs00240719lb9kvlqe") {
id
title
items {
id
name
price
imageUrl
}
}
}그러면 아래와 같은 응답이 올것이다.

만약 items 필드가 필요없다면 아래와 같이 요청하면 된다.
query {
collection (id:"cjwuuprqs00240719lb9kvlqe") {
id
title
}
}그러면 아래와 같이 응답이 올 것이다.
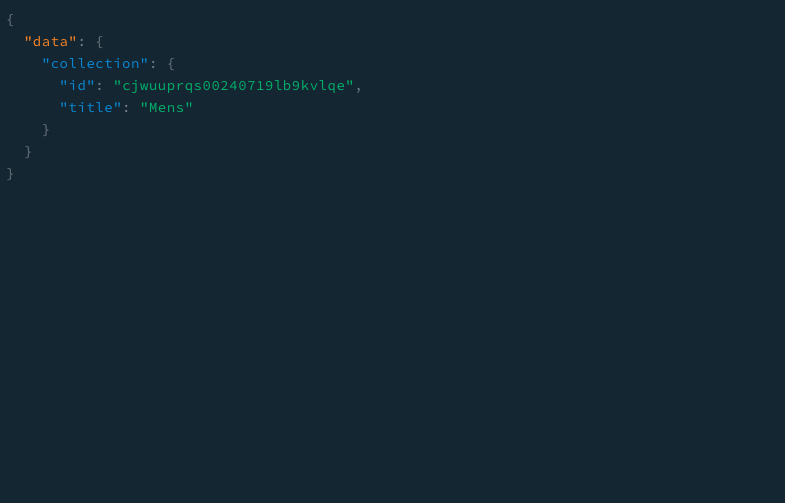
이처럼 인자를 이용해서 해당 id에 match되는 field 값들을 가져왔다.
또한 인자와는 관련없이 내가 필요한 filed만 작성하여 쿼리하는 것은 모든 쿼리에 해당한다.
이제 슬슬 감이 잡히는 것 같다. 그럼 만약 위의 예제에서 더 나아가 2개의 id값에 해당하는 field만 가져오려면 어떻게 해야할까 궁금증이 생긴다.
6. Aliases
일명 별칭으로 각 결과 객체 필드가 동일한 타입을 리턴할 때 구분을 지을 수 있게 도와준다.
만약 위의 예제에서 cjwuuprqs00240719lb9kvlqe와 cjwuuj5bz000i0719rrtw5gqk 두개의 아이디에 대한 데이터를 받아오려면 어떻게해야할까?
query {
collection (id:"cjwuuprqs00240719lb9kvlqe") {
id
title
}
collection (id:"cjwuuj5bz000i0719rrtw5gqk") {
id
title
}
}이렇게 쿼리를 하면 된다고 생각할 수 있지만 이렇게 하면
"Fields \"collection\" conflict because they have differing arguments. Use different aliases on the fields to fetch both if this was intentional."
이렇게 다른 aliases 즉 별칭을 사용하라는 에러 메시지가 나온다.
그럼 원하는대로 별칭을 사용해보자.
query {
firstUser: collection (id:"cjwuuprqs00240719lb9kvlqe") {
id
title
}
secondUser: collection (id:"cjwuuj5bz000i0719rrtw5gqk") {
id
title
}
}과연 요청에 대한 응답은 데이터일것인가 아니면 에러 메시지일것인가
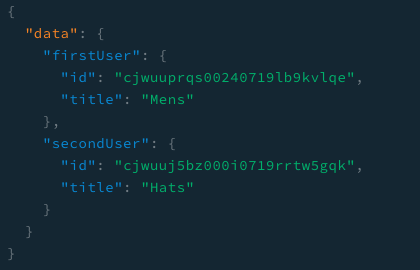
짜잔! 두개의 별칭으로 나뉘어져 값이 들어왔고 추후에도 우리는 각각의 별칭으로 response에 접근/할당 하여 사용할 수 있게 된다.
근데 찐 개발자는 반복되는 코드를 싫어해야한다고 들었다.
찐개발자 흉내를 내보려보니 id와 title 두개의 fields를 반복적으로 작성하는게 귀찮다. 방법이 없을까?
7. Fragment
반복적으로 사용되는 value 등을 변수에 담아 혹은 더 나아가 변수에 담아 여러곳에서 사용하듯이
쿼리에서도 사용해보자!
기본적인 Fragment의 형태는
fragment <FragmentName> on <Type Name> {
<fieldName>
<fieldName>
}이와 같다. 그럼 적용해보자!
query {
firstUser: collection (id:"cjwuuprqs00240719lb9kvlqe") {
...collectionFields
}
secondUser: collection (id:"cjwuuj5bz000i0719rrtw5gqk") {
...collectionFields
}
}
fragment collectionFields on Collection {
id
title
}응답은...
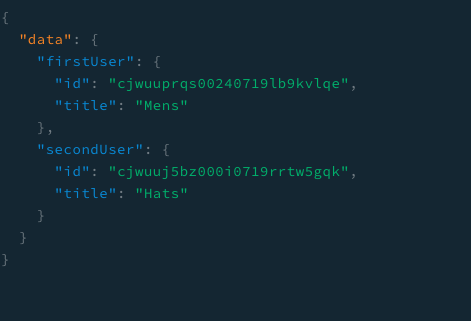
짜잔! 약간 개발자 스러운 코드가 되었다.
사실 좀 더 자세하게 사용하려면 자세한 예제가 필요하다. 지금은 기본적인 형태만 알아보고 apollo-client를 정리할 때 실제
적용한 코드를 예제 삼아 정리하도록 하자.
8. 마무리
GraphQL 언어의 기초적인 문법들에 대해서 정리해보았다.
사실상 gql로 개발을 하다보니 위 문법들을 이것저것 짬뽕하여 사용하게 되는 수준까지 왔다.
하지만 인터넷에는 정말 자료가 너무 부족하다 ㅠㅠ
꼭 내가 궁금한 부분은 질문이 하다도없어서 3시간 6시간 반나절을 보내기도 한다.
(다들 어떻게 그렇게 잘 개발하시는지 너무 부럽고 대단하다!)
이번 블로그에 정리된 기본 문법만 공부하고 실제로 바로 gql을 사용하여 개발을 시작했는데
역시는 역시나 적용하는 부분은 졸큼 달랐다.
그 부분을 다음 블로그에서 정리해보자 한다.
apollo-client 세팅과 적용 그리고 실제로 gql과 apollo를 활용한 서버와의 통신 적용
이 두 주제를 블로깅 할건데
어떤것을 먼저해야할지 아직은 모르겠다.
후자를 먼저하자니 apollo-client 세팅과 설정은 필수적이고
그렇다고 바로 apollo 정리를 하자니 아직 모르는것도 많고 gql을 보다가 너무 뜬금없어질 수 있기 때문이다.
아무튼 다음에 알아볼 apollo는 정말 React와 찰떡궁합 (일부러 react를 메인 타겟으로 하고 만들어졌기 때문이지만)이고
이 또한 자료가 부족하여 광광 울고 머리 쥐어뜯으면서 개발했지만
진짜 apollo없으면 gql 어떻게 적용했을까 싶을정도로 짱짱맨이다.
아무튼 그렇다 gql짱 apollo짱!

ㅋㅋㅋㅋㅋ 맛보기가 너무 과한데요..?! 제 포스팅이 민망해지네욬ㅋ큐ㅠㅠㅠ 저는 어디가서 맛보기라고 하면 안되겠어요 ㅠㅠ