
Apache Kafka 란?
"분산 스트리밍 플랫폼"
대량의 데이터를 처리, 실시간으로 전송한다.
등장 배경
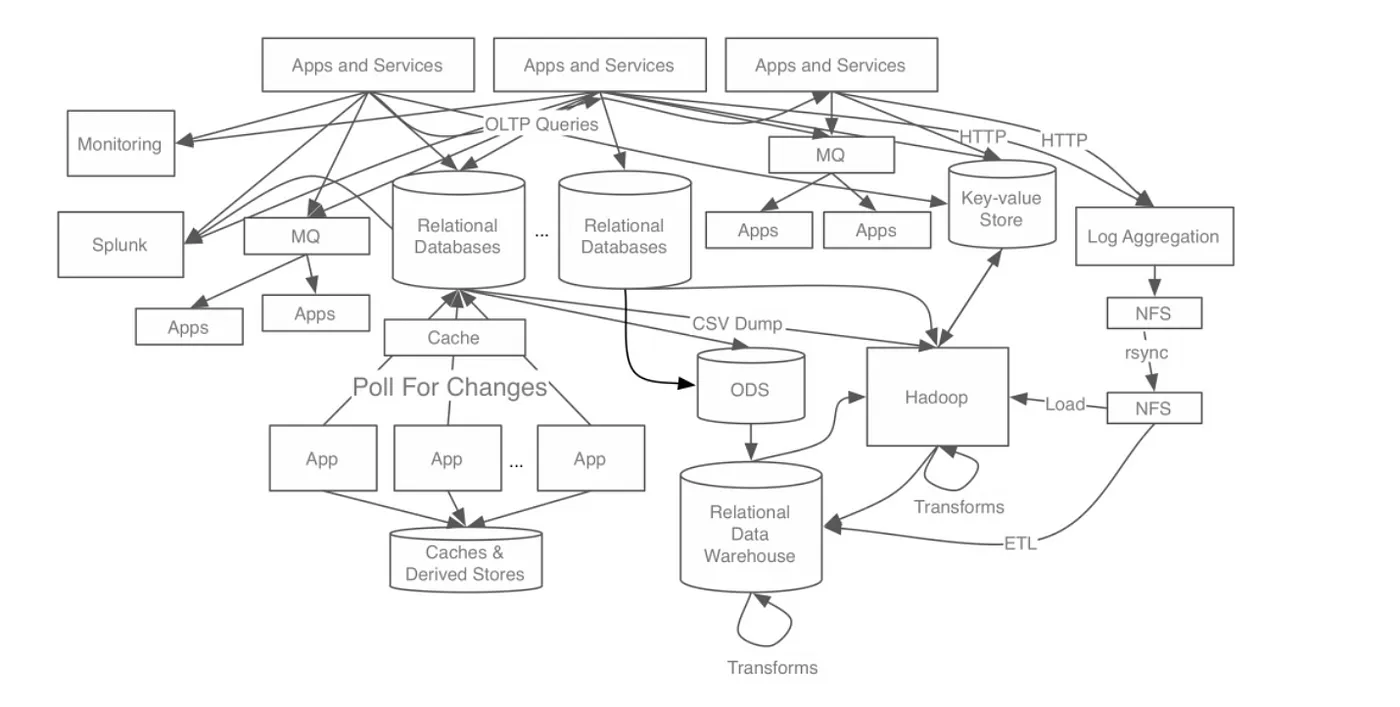
- 문제: 링크드인에서 수많은 데이터를 실시간으로 전송하고 수신하는 과정에서 다수의 프로듀서와 컨슈머가 필요에 따라 개별적인 연결을 가져가는 구조였고, 그 때문에 하나의 시스템만 추가되어도 통신 구조가 기하급수적으로 복잡해졌다. (M * N)
- 해결: 메시지와 데이터의 흐름을 중앙에서 관리하는 구조를 만들자! => 카프카
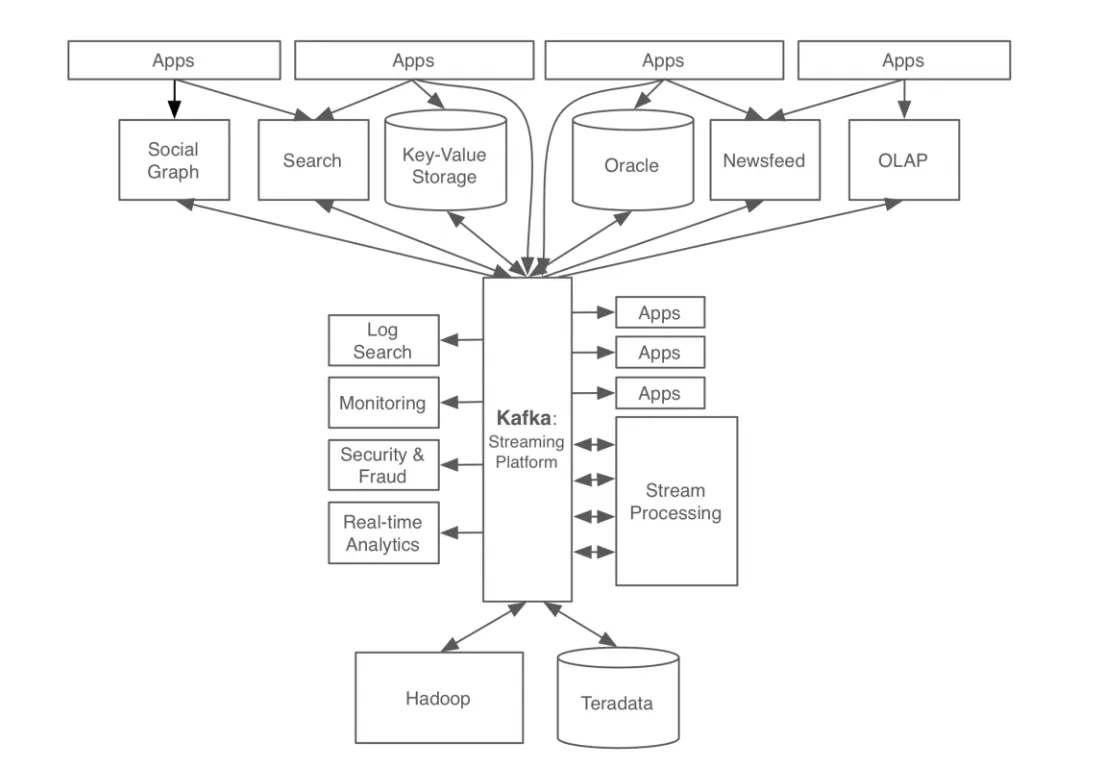
메세지큐(RabbitMQ..)와의 차이점
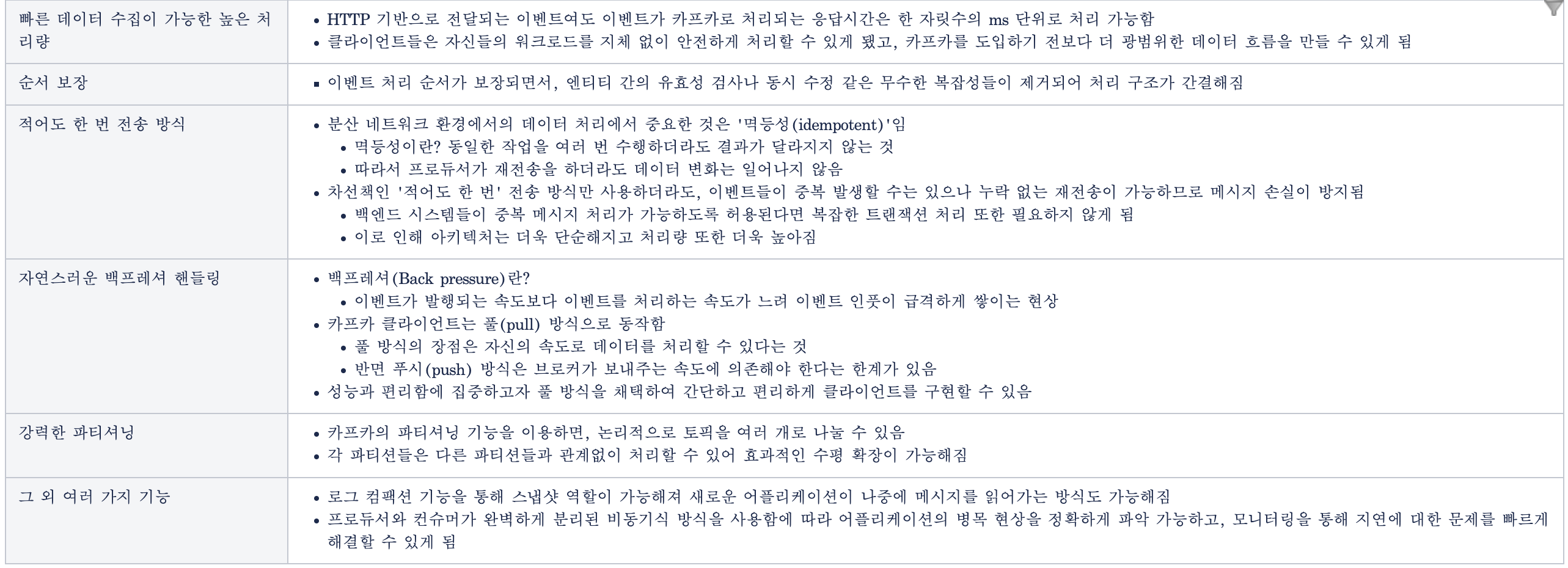
- 높은 처리량
- 많은 양의 데이터를 묶음 단위로 처리하는 배치 처리가 가능하다.
- 파티션 단위를 통해 동일 목적의 데이터를 여러 파티션에 분배하고 데이터를 병렬 처리할 수 있다.
- 확정성
- 수십개의 메세지큐를 제각각 운용하는게 아닌, 카프카 클러스터의 브로커 개수를 자연스럽게 스케일 아웃할 수 있다.
- 다운타임 없이 확장 가능하다 (때문에 데이터의 양을 예측하기 어려울 때 사용 하기 좋다)
- 영속성
- 데이터를 메모리가 아닌 파일 시스템에 저장한다.
- 페이지 캐시 메모리 영역을 사용한다. 한 번 읽은 파일 내용을 OS가 사용하는 메모리에 저장하기 때문에 파일시스템을 사용하더라도 처리량이 높다.
- 고가용성
- 3개 이상의 서버로 클러스터를 구성하여 특정 서버에 장애가 발생하더라도 클라이언트 요청을 처리할 수 있다.
하둡에 많은 영향을 받았지만 하둡은 "빅데이터"에, 카프카는 "real-time" 에 집중했다.
카프카 구성요소
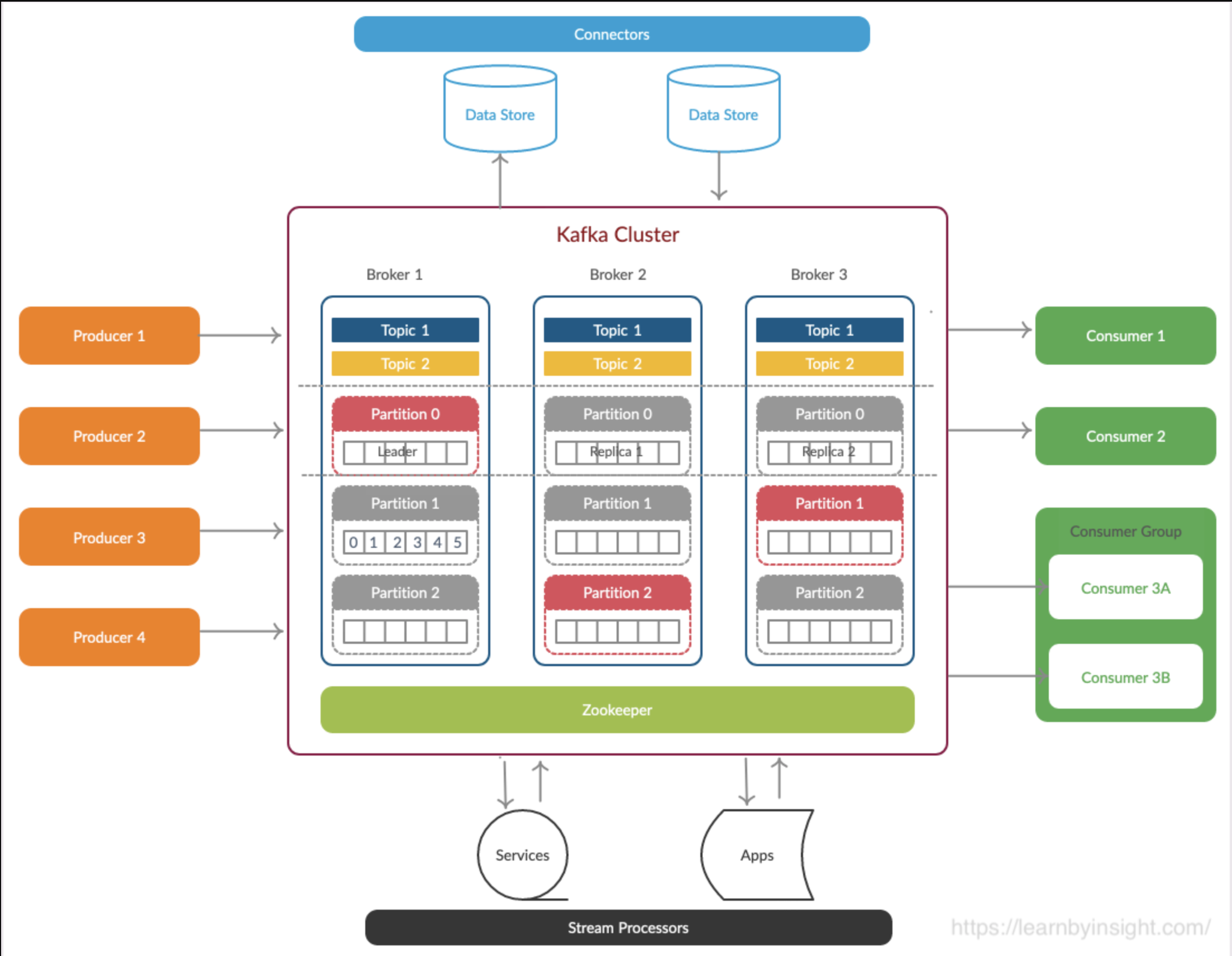
프로듀서
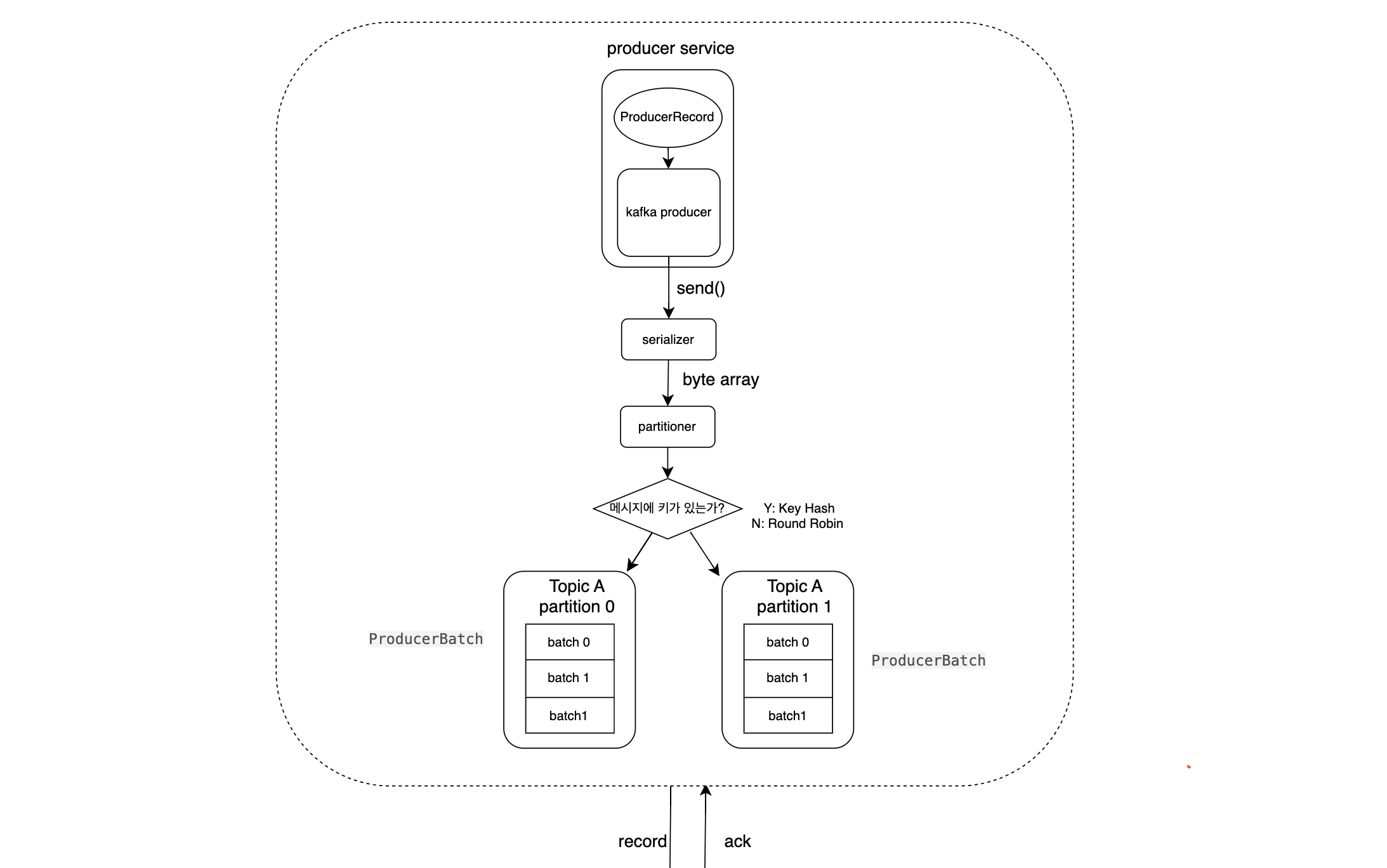
메세지를 특정 토픽에 발행하는 클라이언트이다.
파티셔너를 통해 어떤 파티션에 발행할지 지정한다.
- 메세지 키가 있을 경우 : 해시값을 통해 동일 파티션에서 처리되도록함
- 메세지 키가 없을 경우 : Round Robin(default)
프로듀서에서 send() 이후 파티셔너를 거친 레코드들은 배치 처리를 위해 프로듀서의 버퍼 메모리 영역에 대기한 후 설정에 정의된 값에 따라 브로커에 전송된다.
때문에 배치의 최소 레코드 수를 만족하지 못하면 linger ms만큼 프로듀서 내에서 대기하게 된다.
이같이 Round Robin으로 인한 불필요한 대기를 개선하기 위해 Sticky Partitioner(하나의 파티션에 레코드를 우선적으로 채워서 카프카로 배치전송) 등을 사용한다.
자세한 내용은 이후 포스트에서 다룬다.
브로커
카프카의 실질적인 서버이다.
- 프로듀서로부터 메세지를 수신
- 오프셋 지정
- 메세지를 디스크에 저장
- 컨슈머의 읽기 요청에 디스크에 수록된 메세지 전송
여러 개의 브로커를 묶어 카프카 클러스터를 구성한다.
클러스터 브로커 중 하나는 클러스터의 컨트롤러가 되어 각 브로커에게 파티션 리더를 분배한다. 컨트롤러는 선착순으로 선출된다.
브로커 1 : 토픽 N 으로 구성할 수 있다.
토픽과 파티션, 새그먼트
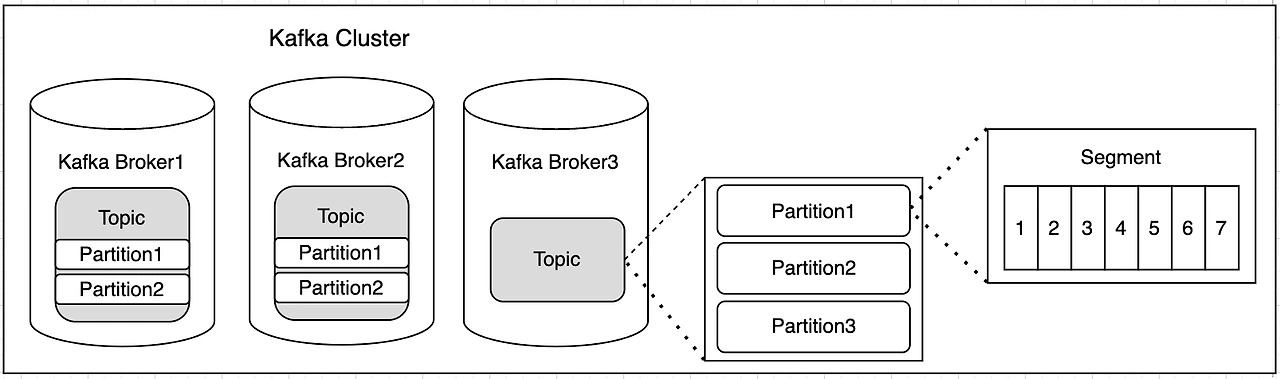
- 토픽은 메세지(이벤트)를 분류하는 단위이다.
- 토픽 1 : 파티션 N 으로 구성할 수 있다.
메세지의 처리는 추가 순이 아닌 파티션별로 관리되기 때문에, 하나의 토픽이 하나의 파티션만 갖는다면 순서가 보장되지만 여러개의 파티션을 갖는다면 순서가 보장되지 않을 수 있다. (같은 파티션 내에서는 순서가 보장된다) - 토픽으로 들어오는 메세지는
append only "file"이다.
컨슈머가 메세지를 소비하더라도 삭제되지 않고 남아있다가 config 에 따라 일정 시간 뒤에 삭제된다. - 각 파티션 내의 메시지는 세그먼트라는 단위로 관리되어, 세그먼트가 일정 크기에 도달하면 새로운 세그먼트가 생성된다.
- 데이터를 삭제하는 경우에도 세그먼트 단위로 이루어지기 때문에 특정 데이터 삭제는 불가능하다.
- 파티션의 개수를 잘 설정하는 것이 중요하다.
너무 적을 경우 처리량이 적어지고, 너무 많으면 장애 복구 시간이 늘어난다.
메세지
바이트 배열의 데이터(기본 데이터 단위)이다.
클러스터는 쓰여진 메시지를 보존기간동안 유지한다.
보존 기간 정책은 log.retention.hours 설정을 통해 가능하며, default는 7일이다.
데이터 크기에 상관없이 카프카의 성능은 일정하기 때문에 장기간 저장해도 문제는 없으므로, 보존기간을 짧게 잡을 필요는 없다.
컨슈머
하나 이상의 토픽을 구독하여 메세지를 소비하는 클라이언트이다.
생성된 순으로 메세지를 소비한다. (FIFO)
파티션 단위로 오프셋을 유지하여 위치를 기억한다.
- commit offset: 처리한 오프셋 위치
- current offset: 읽은 오프셋 위치
- 컨슈머가 읽기를 중단했다가 다시 시작해도 오프셋을 확인해 이어서 메세지 처리 가능하다.
여러 대의 컨슈머로 컨슈머 그룹을 형성할 수 있다.
- 하나의 토픽에 여러 컨슈머 그룹이 붙을 수 있다.(어플리케이션 단위로 생각하면 편하다.)
- 컨슈머 그룹 내의 컨슈머들은 한 토픽의 다른 파티션을 분담하여 읽는다.
- 하나의 파티션은 하나의 컨슈머만 처리 가능 (컨슈머가 해당 파티션에 "소유권"을 가진다고 표현한다.)
- 하나의 컨슈머는 어려 대의 파티션을 담당 가능
- 때문에 파티션보다 컨슈머가 많으면 컨슈머 stand-by 상태로 놀며 브로커의 TCP Connection 을 낭비하게 된다.
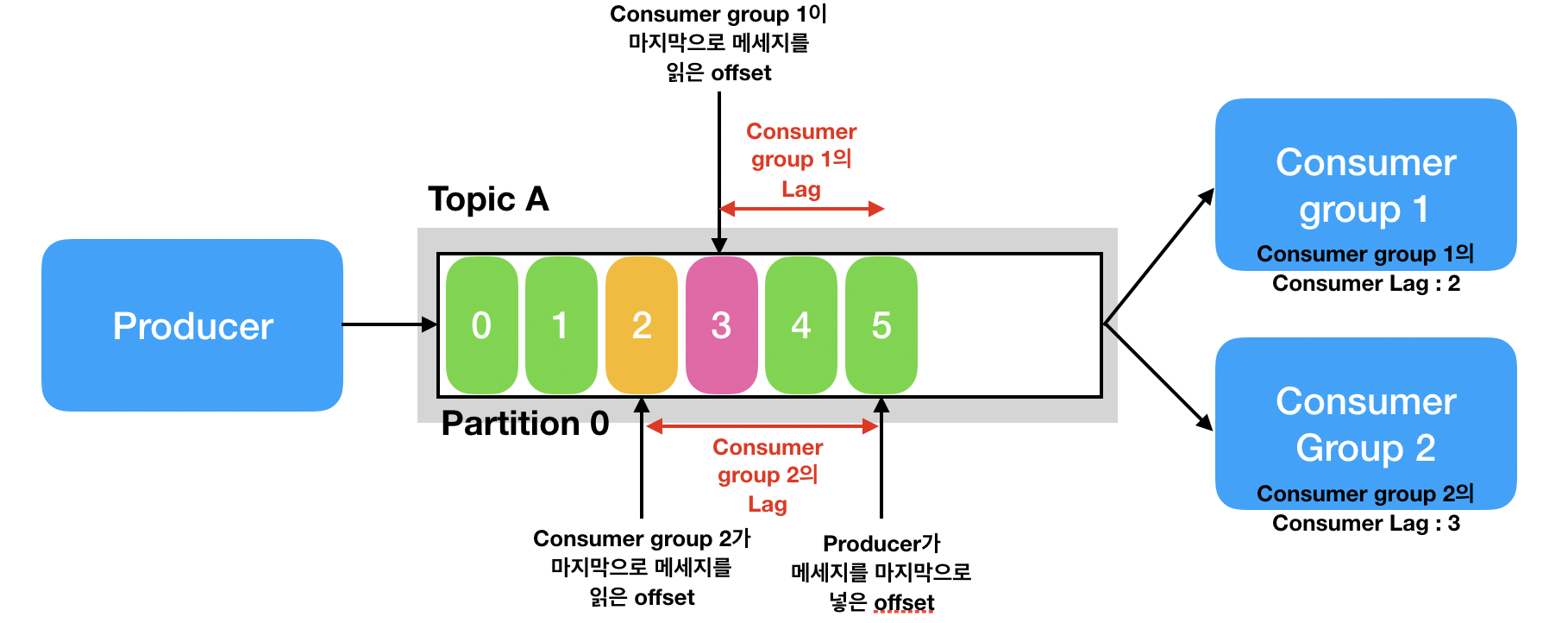
프로듀서가 마지막으로 추가한 오프셋(Log-end-offset) 과 컨슈머가 마지막으로 읽은 오프셋(current-offset) 의 차이를 컨슈머 랙(consumer LAG)이라고 하며, 모니터링에 중요한 지표가 된다.
