
배경
현재의 서비스는 사용자의 활동 로그를 기반으로 개인화 추천을 제공하고 있습니다. 각 원천 서비스에서 발생하는 로그를 Hadoop으로 수집하고, 일일 배치를 통해 정제된 데이터를 서비스 DB에 적재하는 구조입니다. 해당 데이터는 정해진 정책만큼 유지되며, 이후의 데이터는 삭제됩니다.
어느 날 slow query로 인한 DB 부하 발생하여 응답 불가 상태가 되는 장애가 발생했습니다.
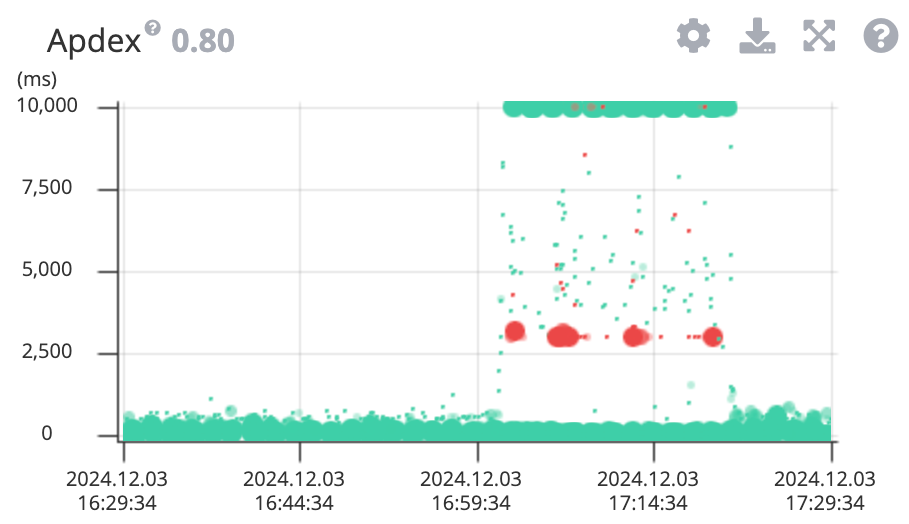
이 이슈의 원인을 크게 두가지로 파악했습니다.
- 데이터 적재량 증가: 활동 유저가 늘어나며 해당 날짜 범위 내 데이터 자체의 사이즈가 늘어남.
- 급격한 트래픽 증가: 근 시간 내에 연결된 유저의 세션을 전부 끊어내는 작업이 있었고, 그로 인해 재접속 동선에 있던 해당 서비스에도 부하가 생김
원인 파악
모니터링을 통해 분석한 결과, 다음과 같은 조회 쿼리가 문제였습니다.
SELECT u.base_dt, u.class_type, u.game_id, u.member_no
FROM user_log u
WHERE u.member_no=191198706
AND u.class_type='SEARCH'
AND u.base_dt BETWEEN '2024-11-26 00:00:00' AND '2024-12-03 23:59:59';이 쿼리의 실행 계획을 확인한 결과:
-> Filter: ((u.class_type = 'SEARCH') and (u.member_no = 196821557) and (u.base_dt between '2024-12-12 00:00:00' and '2024-12-19 23:59:59'))
(cost=60329.56 rows=3009)
(actual time=367.975..367.975 rows=0 loops=1)
-> Index range scan on muge1_0 using PRIMARY (cost=60329.56 rows=3009) (actual time=367.975..367.975 rows=0 loops=1) - type: range
- 예상 rows: 3009
- 실제 cost가 매우 높음 (60329.56)
- PRIMARY 키를 사용한 Index range scan 후 Filter 적용
예상보다 훨씬 높은 비용이 발생하고 있었습니다. 원인을 깊게 파고들어보니 다음과 같은 문제점을 발견했습니다:
- 데이터 타입 불일치: DB의 member_no 컬럼은 VARCHAR로 정의되어 있었지만, 애플리케이션에서는 Long 타입으로 처리
- collation 불일치로 인한 묵시적 형변환으로 인덱스 활용 실패
- fetch row 해가는 것으로 보아 cursor 기반 동작으로 예상되었고,여러 번의 비효율적인 스캔으로 커넥션을 오래 점유
해결
1. 긴급 조치
우선 즉각적인 서비스 안정화를 위해 DB 커넥션 풀을 5개에서 100개로 확장했습니다.
2. 1차 확인
처음에는 JPA Specification에서 타입 변환을 시도했습니다:
default Specification<UserLogEntity> equalMemberNo(Long memberNo) {
return (root, query, builder) -> builder.equal(root.get("id").get("memberNo"), memberNo.toString());
}해당 작업 배포 이후 쿼리를 모니터링하며 문자열로 조회 하는지 확인해봤지만 패치 내용이 반영되지 않은 것으로 확인되었습니다.
u.member_no=191198706 → u.member_no='191198706'남은 쿼리 생성에 관여하는 부분은 테이블 정의로 의심하고 공식 문서를 확인했습니다.
그 결과 엔티티의 필드/프로퍼티 타입을 기준으로 매핑이 이루어진다는 내용을 확인할 수 있었습니다.

즉 기존 쿼리의 toString()은 SQL 생성 이전 단계에서 실행되고, Hibernate는 최종적으로 파라미터 바인딩할 때 엔티티의 필드 타입(Long)을 기준으로 다시 Type Conversion을 수행하기 때문에 의도한대로 동작하지 않은 것입니다.
엔티티에 정의된 필드 타입을 수정하여 재확인한 결과, 인덱스를 제대로 사용하는 것을 볼 수 있었습니다.
@Column(name = "member_no", nullable = false, length = 30)
private String memberNo;수정 후 실행 계획:
-> Filter: ((muge1_0.class_type = 'SEARCH') and (muge1_0.member_no = '196821557') and (muge1_0.base_dt between '2024-12-12 00:00:00' and '2024-12-19 23:59:59'))
(cost=0.40 rows=0)
(actual time=0.049..0.049 rows=0 loops=1)
-> Index range scan on muge...analyze:
-> Index range scan on muge1_0 using ix_user_log_member_no_class_type_base_dt,
with index condition: ((muge1_0.class_type = 'SEARCH') and (muge1_0.member_no = '10044') and (muge1_0.base_dt between '2024-11-26 00:00:00' and '2024-12-03 23:59:59'))
(cost=4.76 rows=10)
(actual time=0.281..0.298 rows=10 loops=1)- Index range scan을 사용 (ix_user_log_member_no_class_type_base_dt 복합 인덱스)
- 예상 rows=10, 실제 rows=10
- 실행 시간: 0.281..0.298 밀리초
- 인덱스 조건으로 모든 WHERE절 조건을 사용
2.1 인덱스 관련
테이블에 인덱스는 아래 3가지가 있었습니다.
- PRIMARY (base_Dt, member_no, game_id, class_type)
- ix_member_no (member_no)
- ix_member_no_class_type_base_dt (base_Dt, member_no, class_type)
이번 이슈에서는 String 질의와 숫자형 질의 모두 ix_member_no는 사용하지 않았습니다. (base_dt가 선두인 나머지 두 인덱스가 날짜 범위 검색에 유리하기 때문에)
숫자형으로 질의한 경우 두 인덱스 모두 base_dt가 첫 컬럼이라 범위 검색에 유리하고, member_no도 둘 다 형변환이 발생해 효율적 활용이 어려우니 unique + 클러스터형 인덱스인 PRIMARY 를 채택한게 아닐까 싶습니다.
반대로 문자열로 질의한 경우는 쿼리의 조건절과 정확히 일치하는 인덱스 컬럼 구성을 가진 복합 인덱스를 채택했다고 생각합니다.
(RDB는 오랜만이라 틀린 부분이 있다면 지적부탁드립니다)
3. 재발 방지
재발 방지를 위해 hibernate 설정 추가로 애플리케이션 시작 시점에 Entity 클래스와 DB 스키마의 매핑을 검증하도록했습니다.
해당 옵션으로 설정하면, 타입 불일치가 발견되면 애플리케이션 시작이 실패하고 로그를 남기게됩니다.
허나 운영 환경에서는 비설정이 권장되기 때문에 Live 와 동일하게 설정되는 테스트 개발 환경 까지만 적용하여 검증하도록하였습니다.
spring:
jpa:
properties:
hibernate.hbm2ddl.auto: validateTODO
- 데이터베이스 컬럼 타입과 애플리케이션 코드 사이의 일관성을 검증하는 프로세스 구축
- 주요 쿼리들의 실행 계획을 정기적으로 리뷰하는 체계 도입
- 유사한 성능 이슈를 조기에 발견할 수 있는 모니터링 강화
Ref.
Hibernate ORM User Guide
JPA Specification에서의 Type 매핑
hibernate.hbm2ddl.auto 위험 헷지
jpa field access?
