Section 1
현대 인터넷 기업의 로그 데이터는 단순 분석용을 넘어 실시간 서비스의 핵심 요소가 되었다.
- 로그인, 페이지뷰, 클릭 등 user action
- call stack, latency, cpu 등 system metric
위와 같은 로그 데이터는 검색, 광고, 추천, 보안, 뉴스피드 등의 실시간 서비스에 활용된다.
그러나 모든 real-time 로그를 전부 사용하는 것은 "실제"(유의미한) 데이터보다 엄청나게 많기 때문에 문제를 야기한다.
(ex. 광고, 추천, 검색 등은 세분화된 클릭률 계산을 위해 "클릭" 로그뿐 아닌 클릭되지 않은 수십개의 항목에 대한 로그도 생성한다.)
초기에는 이런 데이터 분석을 위해 프로덕션 서버에 로그 파일을 떨구고, 스크래핑 하는 방식에 의존했다. (Facebook의 Scribe, Yahoo의 Data Highway, Cloudera의 Flume...)
그러나 이런 시스템은 로그 데이터를 수집해 데이터 웨어하우스 또는 하둡에 로드하여 사용하도록 설계되어있다. (오프라인 분석용)
하지만 링크드인은 이러한 로그 수집 및 처리가 실시간으로 이루어져야한다고 생각했고, 기존 로그 애그리게이터와 메시징 시스템의 장점을 결합한 새로운 로그 처리용 메시징 시스템인 Kafka를 구축햇다.
Section 2 traditional messaging systems and log aggregators
- 기존 메세지 시스템은 다양한 전송 보장에 중점을 두는 등 로그 프로세싱에는 오버스펙인 경우가 많았다.
- ex. IBM Websphere MQ wsAtomicTransaction, JMS..
- 위같은 불필요 기능들때문에 api 와 구현의 복잡도가 올라갔다.
- 대부분의 서비스에서 처리량은 주요 설계 제약 조건이 아니었다.
- JMS 는 명시적으로는 하나의 요청을 통한 멀티 메세지 컨슈밍을 지원하지 않음
- 분산 지원이 취약하다.(여러 시스템에 파티션을 분산해 저장하는 방법이 없음)
- 거의 즉각적 소비를 가정한다
- 데이터 웨어하우징같이 배치로 큰 소비를 하는 케이스는 메세지가 누적되어 성능이 저하됨
기존의 메세지 시스템들은 아래와 같이 동작
1. 클라이언트가 로그데이터(이벤트)를 시스템으로 전송
2. 롤아웃된 파일을 주기적으로 HDFS (혹은 NFS) 장치에 덤프
위같은 방식의 문제:
- 대부분 오프라인에서 로그데이터 소비를 가정하고 구축되어 실시간과는 맞지 않다
- 세부 정보(롤아웃된 파일 등)을 불필요하게 소비자에게 노출시킨다
- 대부분 push 방식 사용하나 링크드인은 pull 방식이 적합하다고 생각했다
- 소비자의 처리량을 초과하여 푸시되는 경우를 예방 가능
- 소비자가 재처리하기 용이
이후 야후 리서치에서 HedWig라는 새로운 분산형 펍/섭 시스템을 개발했고, 확장성과 가용성이 뛰어나며 강력한 내구성을 한다.
그러나 주로 데이터 저장소의 커밋 로그를 저장하기 위함이다.
Section 3 architecture and key design principles of Kafka
위같은 기존 시스템의 한계로 새로운 메시징기반 로그 수집기인 카프카 개발하게 되었다.
기본적으로 메시징은 개념적으로 단순하며, 이를 반영하기 위해 Kafka API도 단순하게 구성되었다.
- 특정 유형의 메시지 스트림은 토픽으로 정의
- 프로듀서는 토픽에 메세지를 발행
- 발행된 메세지는 브로커라고 하는 서버 집합에 저장
- 소비자는 브로커에서 하나 이상의 토픽을 구독하고, 메세지를 소비
// Sample producer code:
producer = new Producer(…);
// 메세지는 바이트 단위의 페이로드만 포함
message = new Message(“test message str”.getBytes());
// MessageSet 을 통해 한번의 요청으로 효율적으로 발행 가능
set = new MessageSet(message)
// Sample consumer code:
// 토픽에 대한 메세지 스트림 생성
streams[] = Consumer.createMessageStreams(“topic1”, 1)
// iterator 을 통해 메세지 처리
for (message : streams[0]) {
bytes = message.payload();
// do something with the bytes
}
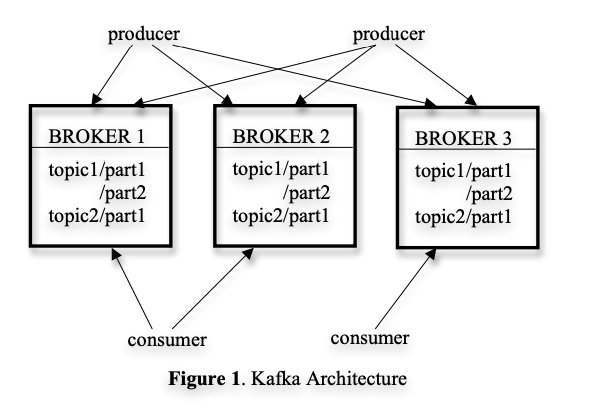
// 소비할 메세지가 더이상 없는 경우 새 메세지가 토픽에 게시될 때까지 차단Kafka는 본질적으로 분산되어 있기 때문에, Kafka 클러스터는 여러 개의 브로커로 구성되고 토픽은 여러 파티션으로 나뉘며 각 브로커는 하나 이상의 파티션 저장된다.
3.1 Efficiency on a Single Partition
브로커에서 단일 파티션의 레이아웃과 파티션에 효율적으로 액세스하기 위한 디자인을 채택했다.
Simple Storage
- 토픽의 각 파티션은 논리적 로그에 해당한다.
- 물리적으로 로그는 거의 동일한 크기(예: 1GB)의 세그먼트 파일 집합으로 구현된다.
- 프로듀서가 파티션에 메시지를 발행할 때마다 브로커는 마지막 세그먼트 파일에 메시지를 추가하기만 하면 된다.
- 성능을 위해 min size 나 batch time 후에만 세그먼트 파일을 디스크에 플러시한다.
- 메시지는 플러시된 후에만 소비자에게 노출된다.
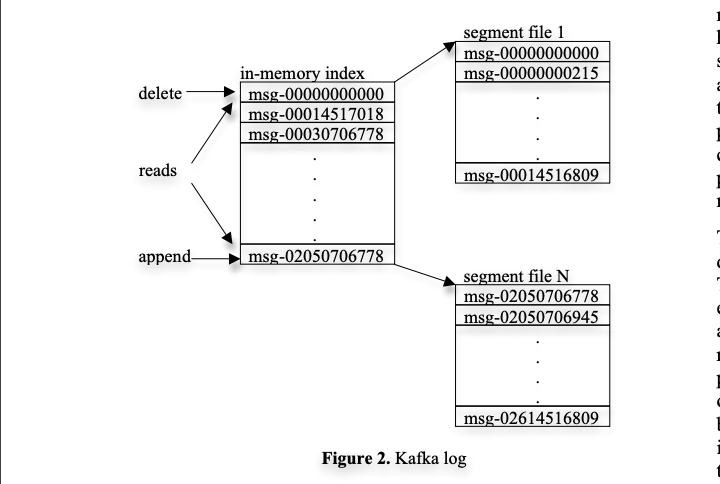
Kafka는 메시지 식별을 위해 로그의 논리적 오프셋을 사용하여 복잡한 인덱싱 구조를 제거했다.
카프카의 메세지에는 명시적인 id 가 없는 대신 오프셋 주소가 지정된다.
때문에 메세지 id 를 실제 위치에 매핑하는 탐색-intensive 한 랜덤 엑세스 인덱스 구조를 유지하는 오버헤드를 피할 수 있다.
메세지 Id 는 sequencial하게 증가하지만 하지만 연속적이지는 않다.(다음 메세지의 ID = 현재 메세지 ID + 현재 메세지 Length)
소비자가 특정 메세지 오프셋을 처리하면 해당 파티션에 해당 오프셋 이전의 모든 메세지를 수신했음을 의미.
효율적인 데이터 전송 전략
- 일괄 처리
- 프로듀서의 단일 요청으로 다수 메시지(message set) 전송 가능
- 소비자의 한 번의 pull 요청으로 수백 KB 메시지 검색할 수 있다.
- 캐시 최적화: Kafka 레이어 메모리에 캐싱 대신 파일 시스템 페이지 캐시 활용
- 이중 버퍼링 방지
- 브로커 재시작되어도 캐시 유지
- 프로세스에서 전혀 메시지를 캐싱하지 않기 때문에 낮은 GC 오버헤드
- 컨슈머가 프로듀서보다 조금 늦게 세그먼트에 접근함으로써 OS 캐싱 휴리스틱이 효과적으로 작동
- 네트워크 최적화: sendfile API 활용
- 하나의 메시지가 여러 번 소비되는 다중 구독자 시스템
- 일반적인 파일-소켓 전송은 4번의 데이터 복사와 2번의 시스템 콜 필요
- sendfile API는 2번의 데이터 복사와 1회의 시스템 콜 필요 (파일 채널에서 소켓 채널로 바이트를 직접 전송, 일반의 1, 4번만 실행)
- 테라바이트 규모에서도 데이터 크기에 비례하는 일관된 성능 유지
로컬 파일에서 원격 소켓으로 바이트를 전송하는 일반적인 방법(4번의 데이터 복사와 2번의 시스템 콜)
- (1) 저장 매체에서 OS 페이지 캐시로 데이터를 읽습니다.
- (2) 페이지 캐시의 데이터를 애플리케이션 버퍼로 복사합니다.
- (3) 애플리케이션 버퍼를 다른 커널 버퍼로 복사합니다.
- (4) 커널 버퍼를 소켓으로 전송합니다.
브로커의 무상태성
- 각 컨슈머가 얼마나 소비했는지에 대한 정보가 브로커가 아닌 컨슈머 자체에 의해 유지
- 브로커의 복잡성과 오버헤드 감소하나 어디까지 소비되었는지 알 수 없어 메세지 삭제가 까다로워짐
- 메시지 삭제 정책: 시간 기반 SLA 적용 (일반적으로 7일 뒤 삭제)
- 소비자가 의도적으로 이전 오프셋으로 돌아가 데이터를 재소비할 수 있다
- 일반적인 Queue와의 차이
- 컨슈머 로직 수정 후 메시지 재처리 가능(하둡 등 ETL 데이터 로드에 중요)
- 주기적으로만 영구 저장소(ES 등)에 데이터를 기록하는 경우 장애 발생 시 데이터유실 대신 마지막 오프셋부터 재처리 가능
3.2 Distributed Coordination
분산 환경에서 프로듀서와 컨슈머의 동작
각 프로듀서는 랜덤한 파티션 혹은 파티션 키와 함수로 지정된 파티션에 메세지를 발행한다.(파티셔너)
카프카에는 컨슈머그룹이라는 개념이 있다.
컨슈머 그룹은 구독한 토픽을 공동으로 소비하고, 각 메세지는 그룹 내 하나의 컨슈머에만 전달된다.
컨슈머 그룹들은 각각 독립적으로 토픽에 대한 메세지를 소비한다. (그룹별 오프셋 관리)
그룹 내의 컨슈머들은 다른 프로세스 혹은 장비에 있을 수 있다.
카프카의 목표는 브로커에 저장된 메세지를 "오버헤드 없이" "균등하게" 나누는 것이다.
- 토픽의 파티션을 병렬 처리의 가장 작은 단위로 지정
즉 파티션과 컨슈머를 1:1로 할당하므로써 여러 소비자가 하나의 파티션에 대해 누가 어떤 메세지를 소비할 지 조정하기 위한 잠금 및 상태 유지 관리 오버헤드를 없앴다.(하지만 컨슈머 그룹은 부하 재조정을 위해 간혹 리밸런싱이 필요하다.)
토픽의 오버 파티셔닝을 통해 소비자보다 파티션이 많게 하여 로드밸런싱을 달성했다.
- 중앙 마스터 노드 대신 컨슈머들이 분산된 방식으로 협력하도록 함
마스터 노드를 두게 되면 마스터 장애에 대한 처리로 시스템이 복잡해질 수 있다.
때문에 고가용성 합의 서비스인 Zookeeper 을 사용
- 주키퍼는 API 같은 간단한 파일시스템을 가지고 있다
- path 등록/값 설정/읽기/삭제/하위 path 조회 등
- path에 watcher 을 등록해 변경 추적, 인스턴스 path 생성(클라이언트 삭제 시 자동 제거), replication 등의 기능 지원
카프카는 다음과 같은 작업에 주키퍼를 사용한다
- 브로커와 컨슈머 추가 및 제거 감지
- 위와 같은 변경 발생 시 컨슈머 리밸런싱 프로세스 트리거
- 컨슈머 상태 체크와 각 파티션의 오프셋 추적 등
- 브로커/컨슈머 시작(등록)하면 카프카 레지스트리에 정보 저장
- Brocker registry: host name, port, 브로커에 저장된 topic&partition
- Consumer registry: Consumer Group 정보, 해당 그룹이 구독하는 topic 목록
- 각 컨슈머그룹은 Zookeeper 소유권 레지스트리 & 오프셋 레지스트리에 연결
- 소유권 레지스트리에는 소유권을 가진 컨슈머 ID 경로에 구독하는 파티션이 있음.
- 오프셋 레지스트리는 각 파티션에 대해 파티션에서 마지막으로 소비된 메세지의 오프셋을 저장
브로커, 컨슈머, 소유권 레지스트리는 임시 경로이고, 오프셋 레지스트리는 영구 경로이다.
브로커에 오류가 발생하면 브로커에 있는 모든 파티션이 브로커 레지스트리에서 제거된다.
컨슈머에 오류가 발생하면 컨슈머 레지스트리에 등록된 항목을 제거하고 소유하는 모든 파티션을 소유권 레지스트리에서 제거한다.
컨슈머가 시작되거나 브로커/컨슈머의 변경을 감지하면 컨슈머는 리밸런싱 프로세스를 시작해 담당 파티션을 재분배한다.
리밸런싱 알고리즘
1. Zookeeper 에서 브로커와 소비자 레지스트리를 읽어 각 구독 토픽(T)에 대해 사용 가능한 파티션 집합(PT)과 T를 구독하는 컨슈머 집합(CT)을 계산
2. PT를 |CT| 청크로 범위 분할하고 각각 소유할 청크 하나를 선택
3. 컨슈머가 선택한 각 파티션에 대해 소유권 레지스트리에 해당 파티션의 새 소유자로 기록
4. 컨슈머는 오프셋 레지스트리에 지정된 오프셋을 읽어 해당 지점부터 소비 재개
5. 파티션에서 메세지를 소비하면 오프셋 레지스트리에 가장 최근에 소비된 오프셋을 주기적으로 기록

컨슈머 그룹 내의 컨슈머들은 변경에 대한 알림을 받는 시점이 조금씩 다를 수 있다.
때문에 컨슈머1이 컨슈머2가 아직 소유하고있는 파티션을 소유하려할 수 있다.
이 경우 컨슈머1은 현재 소유중인 파티션을 모두 해제하고 잠시 대기했다가 리밸런싱 프로세스를 다시 시도
실제로 리밸런싱 프로세스는 몇 번의 재시도 후에 안정화된다.
새 컨슈머그룹이 생성되면 오프셋 레지스트리에는 사용할 수 있는 오프셋이 없다.
이 경우 컨슈머는 브로커에서 제공하는 api 를 통해 구독된 각 파티션에서 사용가능한 min/max 오프셋으로 시작한다.
3.3 Delivery Guarantees
- 일반적으로 카프카는 at least once 를 보장하나, exactly once 보장을 위해서는 2 Phase Commit 이 필요하다
- 대부분의 메세지는 각 컨슈머그룹에 exactly once 로 전달되나, 컨슈머 리밸런싱 과정에서 오프셋이 커밋되기 전에 종료되면 중복 처리 될 수 있다.
- 중복 방지가 중요한 경우 컨슈머에 메세지키 혹은 오프셋을 통한 중복 처리 방지 로직을 추가해야한다. (2phase commit 보다 효율적이다.)
- 단일 파티션의 메세지는 순서를 보장하나 다른 파티션간의 순서는 보장하지 않는다.
- 로그 손상을 방지하기 위해 카프카는 로그에 각 메세지에 대한 CRC(cyclic redundancy check)를 저장한다.
- 브로커에 I/O 에러가 발생하면 카프카는 복구 프로세스를 실행해 일관되지 않은 CRC를 가진 메세지를 제거한다.
- 메세지에 대한 CRC를 체크하면 메세지의 생성/소비 이후에도 네트워크 오류를 확인할 수 있다.
- 브로커가 다운되면 소비되지 않은 메세지는 사용할 수 없게된다. 브로커의 저장 시스템이 영구적으로 손상되면 소비되지 않은 메세지는 영구 손실된다.
- 때문에 카프카의 replication 을 사용해야한다.
Section 4 deployment of Kafka at LinkedIn
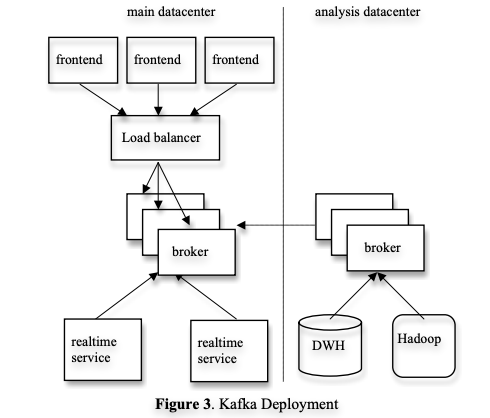
링크드인은 데이터 센터당 하나의 Kafka 클러스터가 있다.
- 프론트는 다양한 종류의 로그 데이터를 생성하고, 이를 배치와 LB를 통해 브로커 집합에 고르게 전송한다.
- Kafka의 온라인 컨슈머는 동일한 데이터 센터 내의 서비스에서 실행된다.
- 또한 오프라인 분석을 위해 별도의 데이터 센터에 Kafka 클러스터를 배포한다.
- 이 클러스터는 하둡 클러스터, 기타 데이터 웨어하우스 인프라에 지리적으로 가까이 있다.
- 실시간 데이터센터의 Kafka 인스턴스에서 데이터를 가져오기 위해 내장된 컨슈머 그룹을 실행한다.
- 하둡 혹은 DW에서 복제 Kafka 클러스터에서 데이터를 가져오기 위한 로드를 실행한다.
- 해당 데이터를 분석해 다양한 리포팅, 프로토타이핑 작업을 실행한다.
- 전체 파이프라인에서 데이터 손실이 없는지 확인하기 위한 감사(auditing) 시스템도 포함되어 있다.
- 각 메시지는 생성될 때 타임스탬프와 서버 이름을 포함한다.
- 각 프로듀서를 측정해 fixed time window 내에서 해당 프로튜서가 각 토픽에 게시한 메시지 수를 기록하는 모니터링 이벤트를 주기적으로 생성한다.
- 컨슈머는 특정 토픽에서 수신한 메시지 수를 계산하고, 모니터링 이벤트와 비교하여 데이터의 정확성을 확인한다.
Section 5 performance results of Kafka
