난이도 ⭐️⭐️
작성 날짜 2025.08.09
고민 내용

말모는 OpenAI API를 이용한 AI 챗봇 기능을 제공한다.
사용자 채팅에 대한 응답 외애도 채팅 요약, 메타데이터 생성 등 다양한 기능에서 외부 API를 사용하는데,
생성형 AI를 API로 사용할 때의 문제가 바로 '나의 예상대로 응답하지 않을 수 있다는 점'이다!
실제로 OpenAI의 서버가 죽거나,
AI의 응답이 서버가 기대하는 규격과 달라 감지되는 오류가 종종 있었다.
그럼 외부 API의 응답에 문제가 발생한 경우 어떻게 처리해야 할까?
- 요청하기, 실패하면 예외 터뜨리기 (현재 방식)
일단 API 요청을 하고, 실패하면 내부 예외를 터뜨리는 방식이다.
그러나 이 방식이 경험해본 결과 어색한 흐름을 가져온다는 것을 알게 되었다.
채팅 자동 요약이나 대화의 경우에는 비동기로 처리되지만,
채팅 종료 프로세스의 경우 요약 생성을 동기로 처리한다.
동기 처리 과정에서 오류가 발생한 경우, 사용자는 의도하지 않은 오류 화면을 만날 수 있다.
예를 들어 채팅 종료 버튼을 눌러 채팅의 종료를 기대했는데, 요약이 생성되지 않는다는 이유로 에러 화면을 만나는 것이다.
비동기 처리 과정에서 오류가 발생한 경우, 서버에 오류 로그가 남는다.
그리고 의도된 동작은 처리되지 않는다.
요약이 생성되어야 하는데...
오류로 인하여 생성되지 않았고 결국 생성 전 상태로 남아있는, 이 상태처럼 말이다.
- 그럼 될 때까지 무한 요청하자
이건 현실적으로 불가능하다.
의도된 답변이 아니라는 이유로 API를 무한 요청하면, 의도하지 않은 무한 토큰 비용까지 발생할 수 있다...
서버의 관점에서도 재시도 횟수와 시간을 예상할 수 없기 때문에, 장시간 스레드를 점유하는 문제가 발생할 수 있다.
- API 요청 처리 실패 시 재시도, 일정 재시도 횟수를 초과하면 따로 분류
앞선 두 방식의 절충안이다.
계속 재시도할 수는 없으니, 우리가 재시도 횟수를 예측할 수 있도록 임계값을 정해두고, 이 값을 초과하면 따로 분류하여 기록해두는 방식이다.
오류 기록은 운영 상 쉽게 확인할 수 있어야 하며, 일괄 재처리 될 수 있도록 해야 한다.
🤔 재시도, 조금 똑똑하게 할 수는 없을까?
찾아보기
try-catch
재시도 처리는 어떻게 해야 할까?
물론 try-catch를 통해서도 가능하다.
무적의 반복문으로 이를 처리해 줄 수 있지만, 여기서 또 하나의 문제를 생각해볼 수 있다.
재시도 처리 도중 서버가 죽는다면?
try-catch는 자바 코드 위에서 실행되는 내용이기 때문에,
서버가 재부팅됐을 때 '요기부터 다시해야지~'라며 시도하지 않는다.
메모리 위에 작성된 재시도 횟수는 말 그대로 증발하는 셈이다.
이 문제를 해결하려면 외부 인프라를 활용해야 한다.
다시 요구사항을 정리해보면,
1. 재시도를 할 수 있어야 한다.
2. 일정 재시도 횟수를 초과한 경우, 따로 분류한다.
3. 외부 인프라를 사용해야 한다.
Redis pub/sub을 생각해보았지만, 서버 재부팅 상황에서 마찬가지로 휘발성을 갖기 때문에 오류 상황을 핸들링해야 하는 현재의 문제 상황에서 적합하지 않다.
또한, 이벤트의 순서에 대해서도 보장하지 않기 때문에, 채팅 시스템에서 적절하지 않았다.
그래서 고려하게 된 것이 메시지 큐
생산자-소비자 패턴 (Producer-Consumer Pattern)
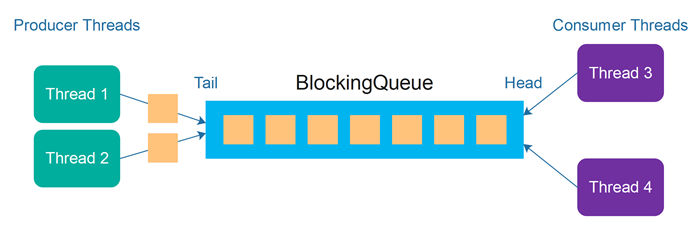
Producer에 의해 발행된 메시지가 순차적으로 큐에 도착하면, Consumer가 이를 소비하여 정해진 작업을 처리하는 구조이다.
이 패턴을 사용하면, 정의한 문제를 해결할 수 있을 것이라고 생각했다.
생산자가 'API 호출을 해주세요'라는 메시지를 받으면, 소비자가 이를 처리하고, 실패 시 다시 큐에 넣는다.
그럼 다시 소비자가 이를 소비하여 재시도한다.
이때 소비자는 메시지의 재시도 횟수를 판단하여 이를 처리할지, 분류할지를 결정한다.
이런 방식으로 진행하면, 자연스럽게 비동기 처리도 가능하며, 하나의 기능이 항상 똑같은 행동을 하도록 보장할 수 있다.
메시지 브로커
이때 생산자가 발행한 메시지의 순서를 보장하면서, 소비자 그룹이 적어도 한 번, 또는 전체에서 한 번 소비할 수 있도록 큐를 관리해주는 도구가 바로 메시지 브로커다.
메시지 브로커로 세 가지를 고려해 보았다.
- 아파치 카프카 (Apache Kafka)
장점
Exactly-once (정확히 한 번 전달)까지 보장할 수 있다.
가장 많은 데이터를 빠르게 처리할 수 있는 메시지 브로커이다.
단점
Kafka 아키텍처 자체가 비용 구조를 높인다.
Kafka는 분산 로그 시스템을 전제로 설계되었기 때문에,
브로커(Broker): 메시지를 저장하고 제공
주키퍼(Zookeeper): 클러스터 메타데이터 관리
토픽/파티션: 데이터를 여러 노드에 나누어 저장
즉, Kafka는 고가용성, 내구성, 확장성을 위해 여러 서버와 디스크, 메모리를 요구하기 때문에 단일 인스턴스 구조에서 좋은 선택은 아닌 것 같다.
- RabbitMQ
장점
설치 간단, 관리 UI 제공 → 운영 편리
다양한 라우팅 패턴 지원 (fanout, direct, topic, delayed queue 등)
단점
고성능 처리량은 제한적
클러스터 확장은 Kafka보다 약하다.
- Redis Stream
장점
Redis 하나로 캐시 + 세션 + 메시징 큐까지 해결 가능
Consumer Group 지원 → 메시지 재처리 가능
AOF/RDB를 사용하면 재시작 시에도 유실 방지가 가능하다.
단점
Kafka만큼의 로그 영속성/처리량은 기대 어려움
메시지 라우팅 기능은 RabbitMQ보다 단순
Kafka의 기능은 너무 훌륭하지만,
단일 인스턴스를 벗어날 수 없는 현재 프로젝트의 규모를 고려했을 때
Kafka는 선택에서 배제하였다.
RabbitMQ와 Redis Stream을 비교했을 때는 비슷한 것 같다.
고민 끝에 Redis Stream을 선택하였다!
- RabbitMQ는 사용해본 적이 없기 때문에 러닝 커브의 문제
- 앞으로 Redis를 이용한 캐싱을 적용할 부분이 있기 때문에 확장성을 고려
- 분산 시스템 환경에서 다른 서버로 메시지를 전달하는 용도가 아니라 하나의 서버에서 API 안정성을 위해 사용하기 때문에, 메시지 라우팅 기능을 크게 사용하지 않을 예정
요런 이유로 Redis Stream을 적용해보기로 하였다.
적용해보기
Redis Config
@Bean
public RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory connectionFactory) {
RedisTemplate<String, Object> template = new RedisTemplate<>();
template.setConnectionFactory(connectionFactory);
// 직렬화 설정
template.setKeySerializer(new StringRedisSerializer());
template.setValueSerializer(new StringRedisSerializer());
template.setHashKeySerializer(new StringRedisSerializer());
template.setHashValueSerializer(new StringRedisSerializer());
template.afterPropertiesSet();
return template;
}Redis에 데이터를 보낼 때, 받을 때 직렬화 및 역직렬화 방법을 설정한다.
직렬화와 역직렬화 방법을 통일시켜서 소통의 오류가 없도록 설정한다.
@Bean
public StreamMessageListenerContainer<String, MapRecord<String, String, String>> streamContainer(
RedisConnectionFactory connectionFactory,
RedisStreamConsumer consumer
) {
StreamMessageListenerContainer.StreamMessageListenerContainerOptions<String, MapRecord<String, String, String>> options =
StreamMessageListenerContainer.StreamMessageListenerContainerOptions.builder()
.pollTimeout(Duration.ofSeconds(2))
.executor(Executors.newFixedThreadPool(8))
.build();
StreamMessageListenerContainer<String, MapRecord<String, String, String>> container =
StreamMessageListenerContainer.create(connectionFactory, options);
// Consumer 그룹 내 여러 Consumer를 등록 → 병렬 처리
for (int i = 0; i < 4; i++) {
container.receive(
Consumer.from(consumerGroup, "malmo-consumer-" + i),
StreamOffset.create(streamKey, ReadOffset.lastConsumed()),
consumer::onMessage
);
}
container.start();
return container;
}컨슈머를 실행하기 위한 코드이다.
pollTimeout
Redis Stream에서 새 메시지를 가져오기 위해 블로킹 폴링할 때 최대 대기 시간이다.
2초 동안 새 메시지가 안 오면 타임아웃 → 다시 요청 (롱폴링 방식)
executor
메시지를 처리할 스레드 풀.
여기서는 8개 스레드로 동시에 메시지를 처리 가능
Consumer.from(consumerGroup, "malmo-consumer-" + i)
Redis Stream의 Consumer Group 기반으로 Consumer 등록한다.
Consumer Group을 쓰면 같은 그룹 내 여러 Consumer가 있을 때 메시지가 분산 처리
여기서는 "malmo-consumer-0" ~ "malmo-consumer-3" 까지 총 4개의 Consumer를 등록했다.
StreamOffset.create(streamKey, ReadOffset.lastConsumed())
읽어올 Stream을 지정한다.
lastConsumed → 이전에 처리하지 않은 메시지부터 이어서 읽기
consumer::onMessage
메시지가 들어왔을 때 실행할 콜백
RedisStreamConsumer 클래스의 onMessage 메서드가 호출되도록 설정했다.
container.start()
start() 호출 시 컨테이너가 백그라운드에서 동작 시작
이후 Redis에 새 메시지가 오면 Consumer들이 알아서 가져가서 처리한다.
컨슈머는 어떻게 새로운 메시지의 도착을 감지하는가?
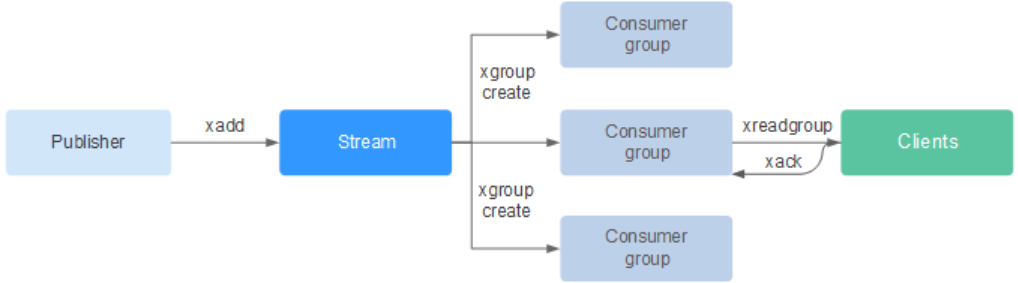
StreamMessageListenerContainer가 빈으로 등록되면서 일어나는 일들을 정리해보자.
위의 코드를 기준으로, 4개의 리스너 스레드가 백그라운드에서 동작한다.
여기서 사용되는 스레드는 Executor의 스레드 풀이 아닌 스프링 프레임워크에서 관리하는 스레드 풀에서 가져온다.
실행된 리스너 스레드에서 레디스의 XREADGROUP 명령어를 BLOCK 옵션과 함께 실행하면서 메시지를 계속 기다린다.
BLOCK 옵션 덕분에 메시지가 없을 때는 불필요한 네트워크 트래픽 없이 효율적으로 대기 (pollTimeout 설정 시간만큼 대기)
리스너 스레드 자체는 블로킹되지만, 대기 상태이기 때문에 CPU에 크게 영향을 주지 않는다.
레디스 입장에서는 XREADGROUP을 외친 컨슈머를 순차적으로 대기열에 넣어 관리한다.
Producer가 메시지를 추가(XADD)하면,
대기열 처음에 있는 컨슈머부터 차례로 할당한다.
레디스 내부적으로는 각 컨슈머 당 하나의 PEL(Pending Entries List)을 갖는다.
PEL은 누가 어떤 메시지를 가져갔는데, 처리 중(Pending)임을 기록하는 리스트이다.
컨슈머에 메시지를 할당하면, PEL에 메시지를 추가한다.
리스너 스레드가 Redis Stream에 추가된 메시지를 감지하면,
ExecutorService의 작업 큐에 작업을 제출한다.
Executor 스레드 풀은 Executors.newFixedThreadPool(8)로 설정된 스레드 풀이다.
이 스레드 중, 작업이 할당되지 않은 스레드가 이를 가져가서 consumer::onMessage로 등록된 메서드를 실행한다.
서버에서 ACK 처리를 하면, 레디스에서는 해당 컨슈머의 PEL에서 제거한다.
+) 그럼 그냥 연결해둔 채로 계속 메시지 받으면 될텐데, pollTimeout이 필요한 이유는 뭘까?
Redis와 서버 간 네트워크가 몰래 끊겼을 경우를 대비한다.
이렇게 하면 끊겼거나 안 끊겼거나, 타임아웃을 통해 재연결을 보장할 수 있다.
+) 컨슈머는 왜 1개일 때보다 N개일 때 병목을 줄일 수 있을까?
리스너 스레드가 메시지를 감지하면, Redis Stream에서 메시지를 가져온다.
그리고 그 메시지를 ExecutorService의 작업 큐에 할당한다.
만약 컨슈머가 1개이면,
메시지를 가져오고, 작업 큐에 할당하는 과정 중에는 다른 메시지를 가져올 수 없기 때문에 병목이 발생할 수 있다.
또한 컨슈머(리스너 스레드)에서 장애가 발생하면, 1개의 컨슈머인 경우 모든 메시지를 처리할 수 없기 때문에, N개의 컨슈머를 설정하면 장애의 전파를 줄일 수 있다는 장점도 있다.
Producer
@Slf4j
@Service
@RequiredArgsConstructor
public class RedisStreamAdapter implements PublishStreamMessagePort {
@Value("${spring.data.redis.stream-key}")
private String streamKey;
private final StringRedisTemplate redisTemplate;
private final ObjectMapper objectMapper;
public void publish(StreamMessageType type, StreamMessage payload) {
TransactionSynchronizationManager.registerSynchronization(
new TransactionSynchronization() {
@Override
public void afterCommit() {
try {
Map<String, String> map = new HashMap<>();
map.put("type", type.name());
map.put("payload", objectMapper.writeValueAsString(payload));
map.put("retry", "0");
StreamOperations<String, String, String> ops = redisTemplate.opsForStream();
RecordId id = ops.add(MapRecord.create(streamKey, map));
log.info("Published message to Redis Stream: type={}, payload={}, id={}", type, payload, id);
} catch (Exception e) {
throw new RuntimeException("Failed to serialize payload", e);
}
}
}
);
}
}Producer가 Redis에 메시지를 보낼 때 사용하는 코드이다.
보면 afterCommit 안에서 메시지를 추가(XADD)하는데, 그 이유는 조금 길어져서 아래의 트러블 슈팅에 정리해두었다.
Consumer
생성된 메시지를 처리해 줄 컨슈머의 메서드이다.
@PostConstruct
public void init() {
try {
// Consumer Group 생성 (이미 존재하면 무시)
try {
redisTemplate.opsForStream().createGroup(streamKey, ReadOffset.from("0"), consumerGroup);
log.info("Created consumer group: {}", consumerGroup);
} catch (Exception e) {
log.debug("Consumer group already exists or stream doesn't exist yet");
}
} catch (Exception e) {
log.error("Error creating consumer group", e);
}
}처음에 컴포넌트를 등록할 때 실행되는 메서드이다.
Redis의 XGROUP CREATE 명령어를 실행하여 특정 스트림(streamKey)에 새로운 컨슈머 그룹을 생성한다.
ReadOffset.from("0")
0은 스트림의 가장 처음부터 모든 메시지를 읽을 준비를 하라는 의미이다.
의도적으로 이전의 메시지를 무시하려는 경우, 변경 가능하지만 최초 생성의 상황이기 때문에 0으로 설정하였다.
XGROUP CREATE는 만약 그룹이 존재하는 경우 오류를 던지는데,
해당 오류는 운영 상 의미 없는 부분이므로 로그만 남기고 정상 흐름으로 바꾼다.
public void onMessage(MapRecord<String, String, String> record) {
try {
String type = record.getValue().get("type");
String payloadJson = record.getValue().get("payload");
JsonNode payloadNode = objectMapper.readTree(payloadJson);
log.info("Processing record type={}, id={}", type, record.getId());
CompletableFuture<Void> future;
switch (StreamMessageType.valueOf(type)) {
case REQUEST_CHAT_MESSAGE:
future = processChatMessage(payloadNode);
break;
case REQUEST_SUMMARY:
future = processSummary(payloadNode);
break;
case REQUEST_TOTAL_SUMMARY:
future = processTotalSummary(payloadNode);
break;
case REQUEST_EXTRACT_METADATA:
future = processMetadata(payloadNode);
break;
default:
log.warn("Unknown message type: {}", type);
// 알 수 없는 타입은 바로 ACK 처리
redisTemplate.opsForStream().acknowledge(streamKey, consumerGroup, record.getId());
return;
}
// 비동기 작업이 완료되었을 때의 처리
future.whenComplete((result, throwable) -> {
if (throwable != null) {
// 비동기 작업 중 예외 발생 시
log.error("Error processing record {} asynchronously", record.getId(), throwable);
handleFailedMessage(record); // 실패 처리 로직 (DLQ 등)
} else {
// 성공적으로 완료 시 ACK
redisTemplate.opsForStream().acknowledge(streamKey, consumerGroup, record.getId());
log.info("Successfully processed and acknowledged record id={}", record.getId());
}
});
} catch (Exception e) {
// onMessage 메서드 자체에서 동기적으로 에러 발생 시
log.error("Error processing record {}", record.getId(), e);
handleFailedMessage(record);
}
}RedisConfig에서 설정했던, 컨슈머가 직접적으로 실행하는 onMessage 메서드이다.
메시지를 받고, 메시지 타입에 따라 다른 메서드를 실행한다.
CompletableFuture를 이용해 실제 작업은 비동기 처리한다.
해당 작업을 실행하던 워커 스레드는 콜백을 등록하고, 바로 스레드풀에 복귀하기 때문에 Block되지 않는다.
그리고 해당 작업이 성공적으로 처리된 경우, 이 작업을 처리하던 스레드가 메시지를 ACK 처리한다.
이 방식을 사용하면 Executor 스레드 풀의 스레드는 API 요청과 같이 긴 시간을 필요로 하는 작업을 처리하지 않고, 스레드 풀로 복귀할 수 있기 때문에 더 많은 Redis 메시지를 처리할 수 있다.
비동기 작업에서 예외가 발생하거나, 전체 코드에서 예외가 발생한 경우, handleFailedMessage 메서드를 실행한다.
private void handleFailedMessage(MapRecord<String, String, String> record) {
try {
// 현재 retry 횟수 확인
Object retryCountObj = record.getValue().get("retry");
int retryCount = retryCountObj != null ? Integer.parseInt(String.valueOf(retryCountObj)) : 0;
// 최대 재시도 횟수 설정 (예: 3회)
int maxRetries = 3;
if (retryCount < maxRetries) {
// retry count 증가
retryCount++;
// 새로운 메시지 생성 (기존 데이터 + retry count 업데이트)
ObjectRecord<String, Map<String, String>> retryRecord = StreamRecords.objectBacked(record.getValue())
.withStreamKey(streamKey);
// retryCount 필드 추가/업데이트
retryRecord.getValue().put("type", record.getValue().get("type"));
retryRecord.getValue().put("payload", record.getValue().get("payload"));
retryRecord.getValue().put("retry", String.valueOf(retryCount));
retryRecord.getValue().put("originalId", record.getId().getValue());
// Stream에 다시 publish
redisTemplate.opsForStream().add(retryRecord);
log.info("Retry message published - originalId: {}, retryCount: {}",
record.getId(), retryCount);
} else {
log.error("Maximum retry count exceeded for message: {}", record.getId());
// DLQ에 실패한 메시지 추가
String dlqKey = streamKey + ":dlq";
ObjectRecord<String, Map<String, String>> dlqRecord = StreamRecords.objectBacked(record.getValue())
.withStreamKey(dlqKey);
dlqRecord.getValue().put("failedAt", String.valueOf(System.currentTimeMillis()));
dlqRecord.getValue().put("originalId", record.getId().getValue());
redisTemplate.opsForStream().add(dlqRecord);
}
// 기존 메시지는 ACK 처리해서 PEL에서 제거
redisTemplate.opsForStream().acknowledge(streamKey, consumerGroup, record.getId());
} catch (Exception e) {
log.error("Error handling failed message: {}", record.getId(), e);
}
}API 요청이나 소비 과정에서 오류가 발생한 경우에 대한 정책을 구현한 코드이다.
만약 실패 상황이 발생하면, retry 필드 값을 확인한다.
만약 retry 값이 3인 경우에는 이 메시지를 DLQ에 추가한다.
DLQ는 더이상 재시도 처리하지 않는 메시지들을 모아둔 메시지의 무덤이다.
이후 장애가 발생한 상황에서 DLQ를 직접 조회하고, 관리할 수 있다.
XRANGE my-stream:dlq - + COUNT 10
요런 식으로 레디스 명령을 치면,

이런 식으로 실패한 메시지의 형태를 확인하고, 관리할 수 있다.
만약 retry 값이 3보다 작은 경우, 메시지를 다시 Stream에 produce한다.
이 과정에서 메시지의 retry 필드의 값을 하나 증가시킨다.
그리고 이렇게 추가된 메시지는, 다시 Consumer에 의해 소비된다.
이런 방식으로 실패한 API 요청에 대한 재시도, 분류 처리가 가능했다!
트러블 슈팅
비동기 처리로 인한 동시성 이슈
분명히 COMPLETE로 바꾼 채팅방의 상태가 컨슈머의 처리 후 ALIVE로 둔갑하는 것이다.
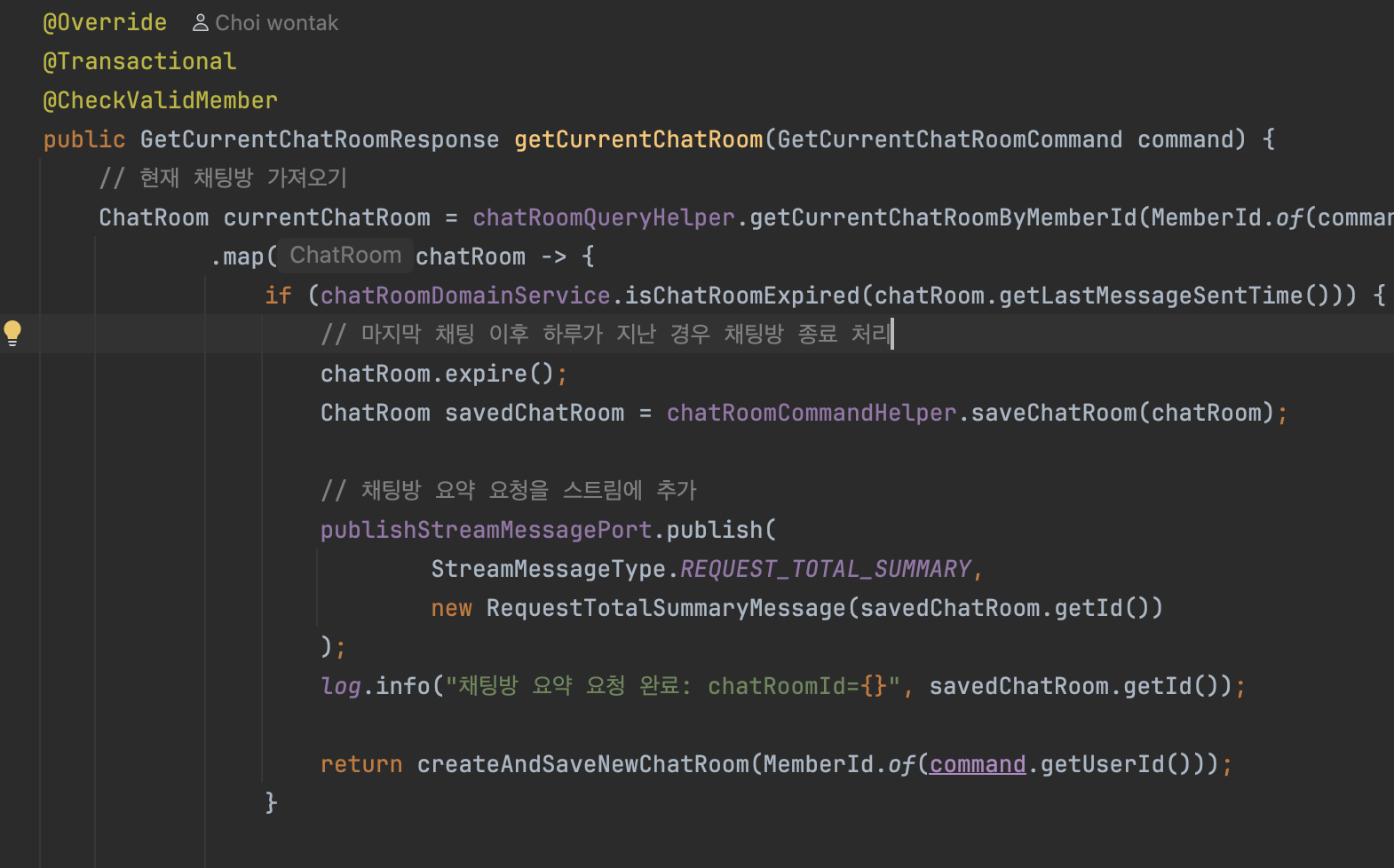
Producer의 코드를 보면, chatRoom.expire()의 코드를 통해
chatRoom의 상태를 COMPLETE로 변경한다.
이후 saveChatRoom으로 상태를 DB에 반영한다. (정확히는 영속 상태)
Transactional이 메서드 단위에 붙어있기 때문에,
save 시점은 코드가 끝난 후, 즉 모든 처리가 끝나야 커밋 내역이 flush가 된다.
그런데 영속과 커밋 시점 사이에 Redis에 메시지를 발행한다.
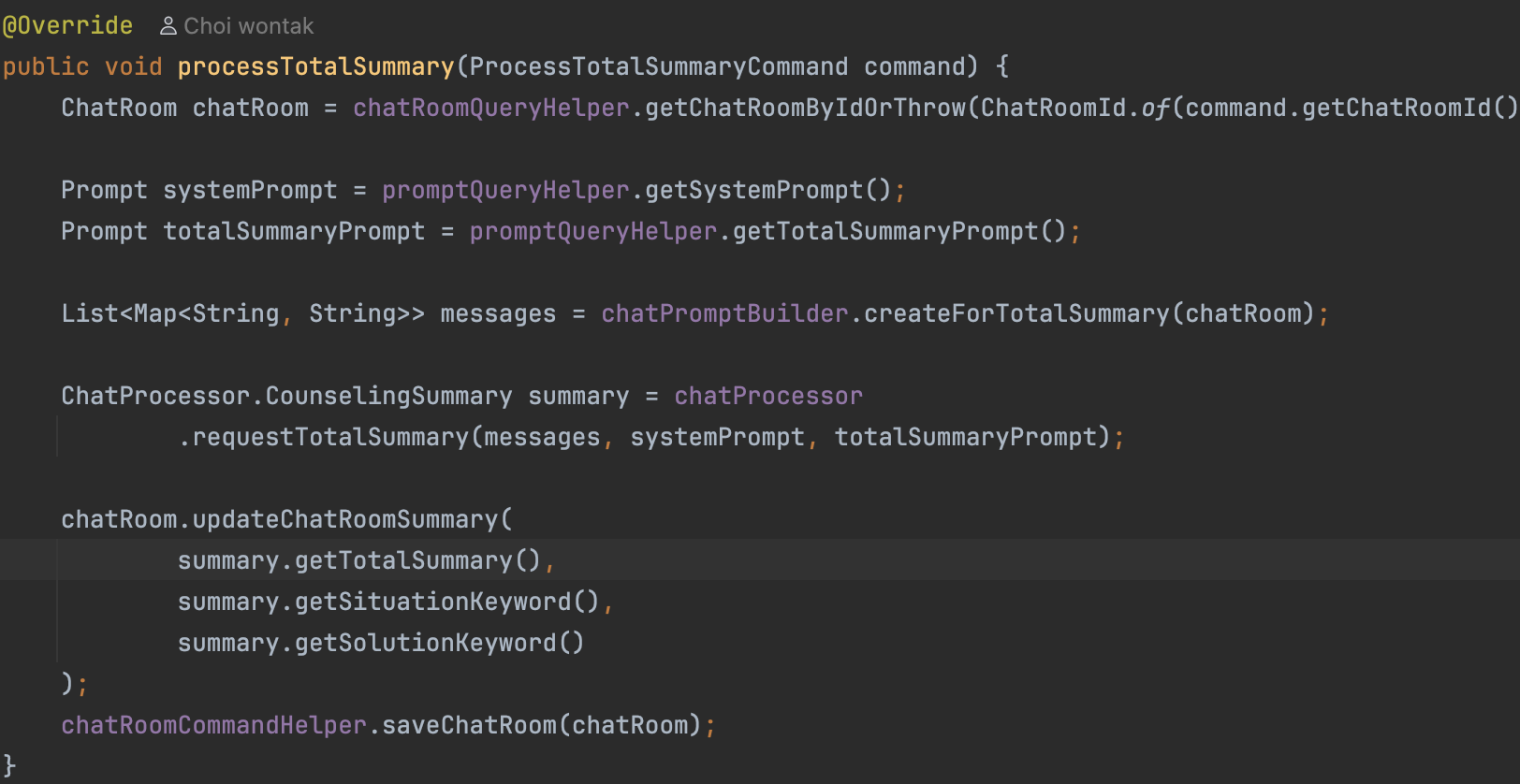
Consumer의 코드를 보면,
chatRoom을 조회해 내부 로직을 처리한 후 변경사항을 저장하기 위해 마찬가지로 chatRoom을 저장한다.
문제는 여기서 발생하는데,
Consumer의 chatRoom 조회는 Producer의 코드에서 flush가 되기 전으로, 아직 상태가 ALIVE이다.
Consumer의 chatRoom이 update되는 시점은, Producer의 chatRoom이 flush된 이후에 처리되기 때문에 덮어씌워지는 것
생각치도 못한 문제가 발생했다..ㅎㅎ
리스너 스레드가 굉장히 빠르게 메시지를 가져와서 컨슈머에게 할당하는 것도 신기했다..!
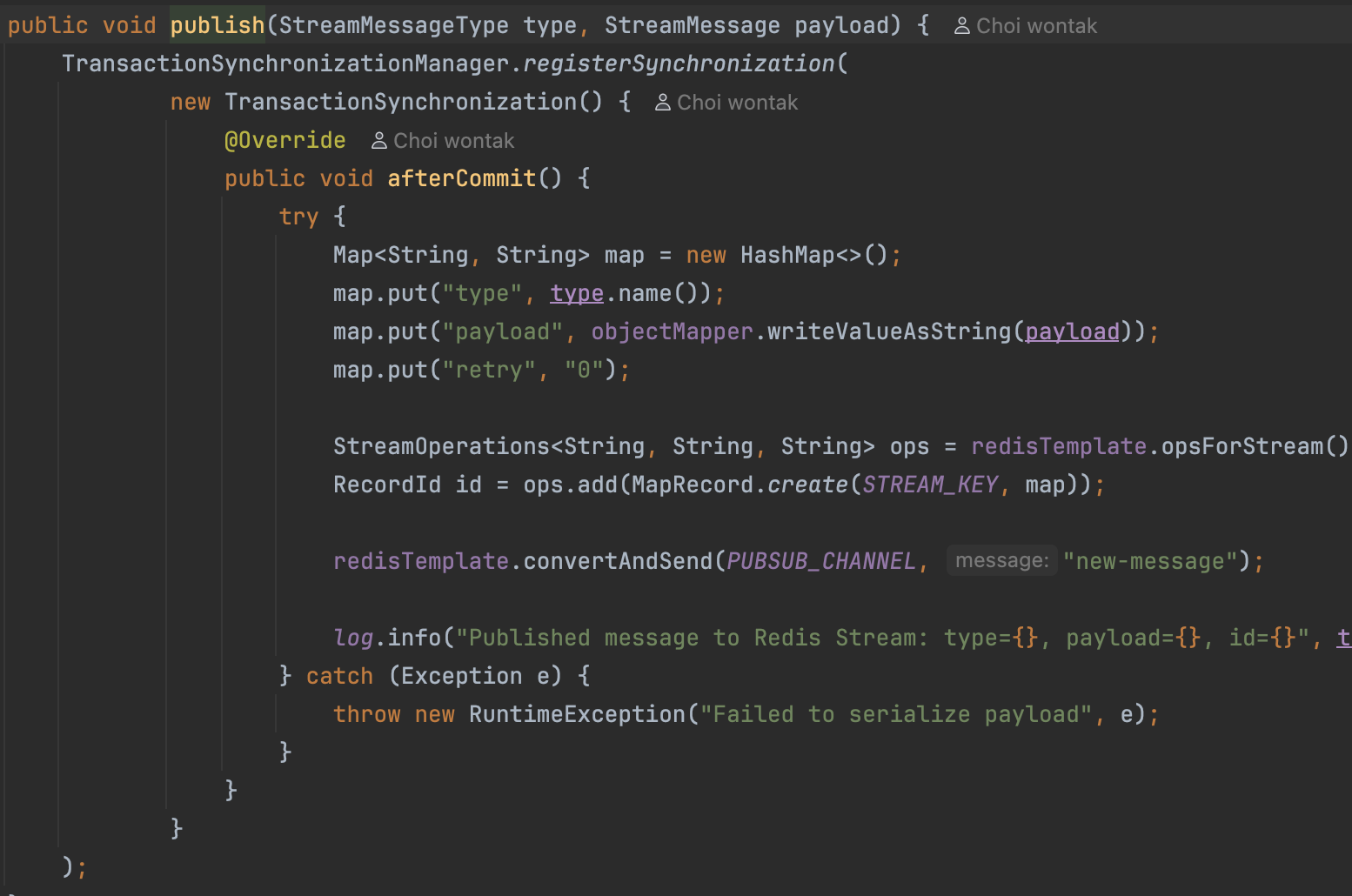
publish 메서드에 afterCommit을 달아 해결했다.
Callee는 Caller의 트랜잭션을 전파받는데,
이 트랜잭션에 "나는 당신들 처리 끝나면 실행하시오" 하고 등록해두는 셈이다.
결론
문제 해결?
이전에 충분 조건을 확인해보자.
- 재시도를 할 수 있어야 한다.
→ API 요청 실패 시 재시도 메시지를 큐에 넣는다.- 일정 재시도 횟수를 초과한 경우, 따로 분류한다.
→ DLQ에 저장- 외부 인프라를 사용해야 한다.
→ 레디스 스트림 사용, 서버 재시작 시 큐에 있는 메시지를 처리하는 방법으로 사고 대응 가능
포스팅 도중 알게된 내용인데 추가적으로 처리할 부분이 남았다..ㅎㅎ
메시지 처리에 실패해서 큐에 재시도 메시지를 넣는 것까지는 구현하였으니
서버가 재시작되더라도 큐의 메시지를 Consume해서 다시 처리가 가능한 것은 맞다.
그러나 메시지가 Consume되어 처리되는 도중 서버에 장애가 발생하면,
메시지는 ACK되지 않고 Pending 상태로 남게 된다.
서버 재시작 시 PEL에 등록된 메시지를 직접 확인할 수 있긴 하지만
이 방법은 번거롭다.
아마 다음의 방법으로 확인할 수 있을 것 같다.
- 재시작 시 XPENDING 명령을 사용해 현재 컨슈머에 할당된 처리 미완료 메시지가 있는지 확인
- 만약 Pending 메시지가 있다면, XCLAIM 명령으로 해당 메시지들의 소유권을 다시 현재 컨슈머로 가져오기
근데 이 방법은 컨슈머가 두 대일 때 하나가 처리하고 있는 메시지를 재부팅된 컨슈머가 중복으로 처리할 수도 있지 않을까?
그건 유휴 시간(idle time)의 개념을 도입하면 될 것 같다.
MIN_IDLE_TIME을 초과한 메시지들만 XCLAIM하는 방식을 사용해
오랜시간 ACK없이 PEL에 존재하는 메시지들, 즉 뭔가 문제가 있다고 판단되는 메시지들만 옮기는 방법으로 해결할 수 있을 것 같다.
확장하기
지금은 요청이 완전히 실패한 경우 DLQ에 넣어버리지만,
다른 큐에 넣고 다른 방식으로 처리해줄 컨슈머를 생성하는 방식으로 확장할 수 있다.
API 요청이 완전히 실패한 경우, dlq와 함께 슬랙 알림을 주는 방식으로 확장한다면, 운영 상 더 편리할 것으로 예상한다.
추가적으로, 현재 프로젝트의 규모에 적합할지는 조금 알아봐야겠지만,
OpenAI API 서버에 대한 지속적인 헬스체크를 통해 서버가 정상 상태일 때 실패 API를 재처리하는 로직 등 다양한 방식의 확장이 가능할 것 같다!
결론
이런 식의 확장 방식을 고려해볼 수 있는 것도 메시지 브로커 도입의 장점인 것 같다!
다음 포스팅에서 계속...
