💪🏻공부법
- 반복 연습 : 10분 판다스
- 구글링을 적절히 잘 사용하자 : 스스로 답을 찾는 연습을 해야함.
- 찐 프로젝트를 할 때,
1) 목표 설정하기 : 무엇을 위해 데이터 전처리와 시각화가 필요한지 항상 생각하기
2) 예상 산출물 정의하기 : 데이터 처리 및 시각화해서 나타날 예상 결과물은 무엇인가 생각하기
3) 'as-is' vs 'to-be' 생각하기 : 현재 문제와 상황이 무엇인지 인지하고 어떤식으로 개선할 것인가 방향성 설정하기
⭐깨달은것⭐⭐
- 오늘 공부하니까 뭔가 sql느낌도 살짝 나는것같다.
둘을 잘 알아야 잘 따라갈 수 있을것같은 느낌이 남 - matplotlib : print를 사용해 추출하는것 아님 > plt.show()로 정보 추출.
- 차트를 계속 스스로 다양하게 만들어보자.
⭐잘못한것⭐
🧡1주차🧡
- 데이터 전처리와 시각화는 왜 필요한가?
: 데이터는 설득을 하기 위해서 필요
: 설득을 잘 하기 위해 데이터를 잘 전달해야함
: 시각화가 잘 전달하기 위한 방법 중 하나
-> 목적이 가장 중요! 데이터를 통해 무엇을 해야할지 고민해야함
=> 시각화를 해야 쉽게 정보를 볼 수 있음
목적성을 갖는게 가장 중요- 💛가장 중요! 어떤 목적을 가지고 데이터를 분석할 것인가를 먼저 정의해라.
🧡2주차🧡
- 데이터 전처리 = 내가 원하는 데이터를 보기 위해 하는 모든 활동
=> 데이터 전달의 목적성을 지녀야 효과가 증가함- pandas - excel과 비슷
대용량 데이터를 처리하는데 강함 ,
자동화와 프로그래밍 기능,
복잡한 데이터 처리 및 분석도 가능,
확장성과 유연성,
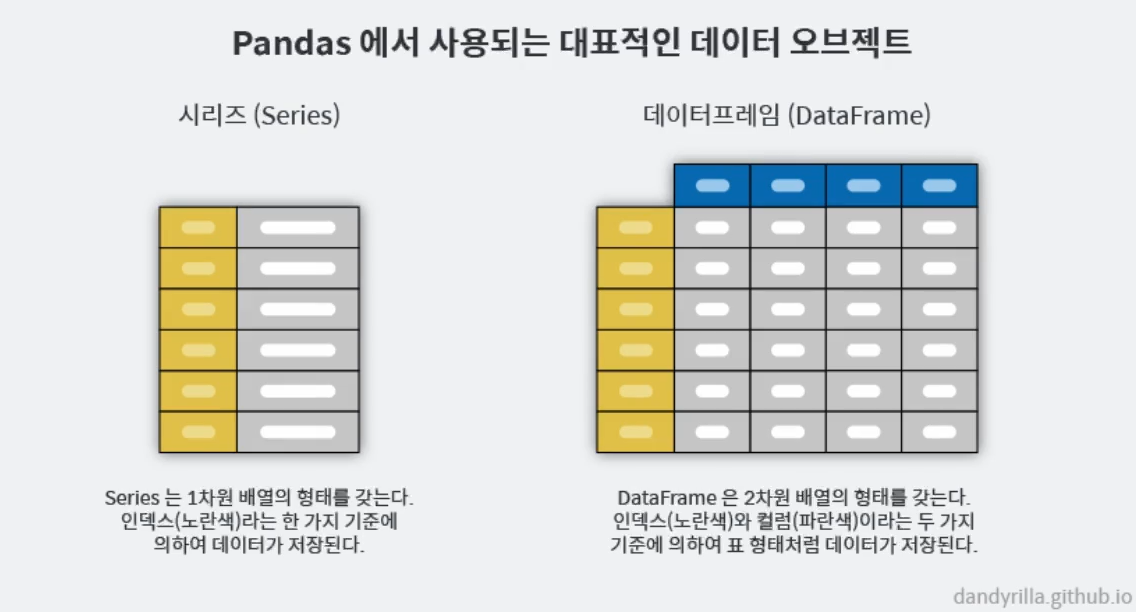
버전 관리- pandas 구조
=>> 하나의 컬럼 = 시리즈 , 컬럼 2개 이상 있는 형태 = 데이터 프레임으로 접근하면 쉬움
🧡3주차🧡
- pandas 기초
- 데이터 전처리 - 컬럼
- data= dataframe
🧡4주차🧡
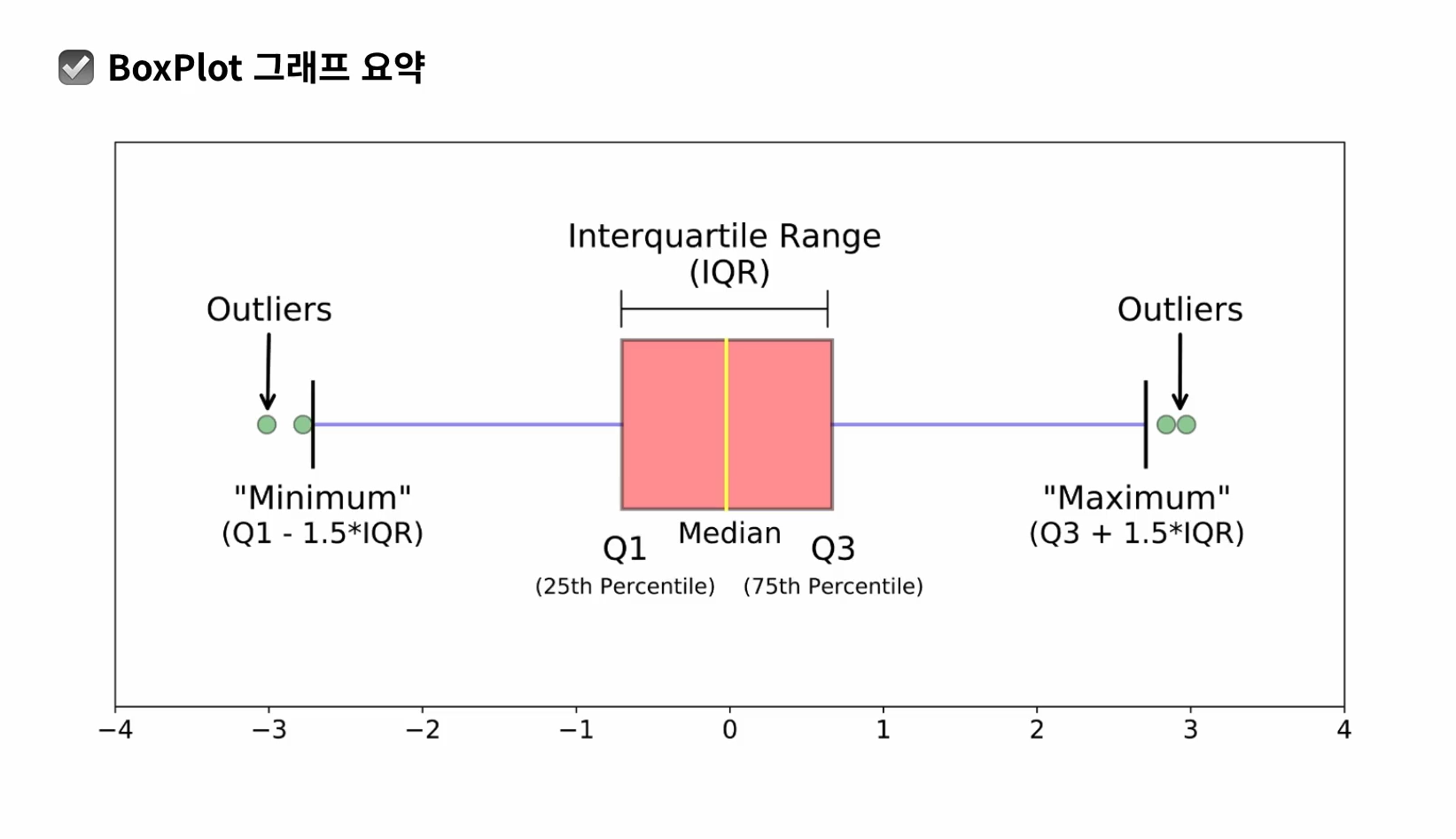
- box plot: 중앙값은 평균값이 아니라 진짜 중간 값임.
구간 벗어나면 이상치
-> 데이터의 분포, 이상치를 한번에 알 수 있어 좋음
- 연속형 변수들은 숫자만 해당됨
- 상관관계라고 인과관계가 있는건 아님


3주차 필기
1강
2강
3강
4강
- iloc > slice 역할
- loc > slice 역할인데 iloc랑 조금 다름
-> iloc는 숫자값으로 슬라이싱 함 , loc는 컬럼명과 인덱싱으로 슬라이싱함 - ⭐파이썬과 다르게 [2:3]이면 3번째 행 값이 포함됨
5강 - Boolean Indexing >
- > 줄 바꿈
6강 - concat > 데이터 프레임을 합치게 도와주는 함수
- 빈곳들은 다 NAN으로 표기됨
- merge >
=> concat은 그냥 데이터를 위아래,좌우로 그냥 병합을 돕는 함수 , merge는 특정 컬럼을 고려해 병합을 하는 함수
=>>how로 표현을 해줌- inner:
- outer:
- left:
- right:
7강
- groupby : 연산자 다양하게 활용 가능
- pivot table
4주차 필기
1강
- 데이터 시각화의 목적 : 의사결정을 더 잘 할 수 있게 도와줌
2강 - matplotlib : 그래픽을 생성하는데 주로 사용하는 프로그램
3강 - 그래프 그리는 도구 :
1) plot() :
2) 스타일 설정 : 색, 선 스타일 등을 다 다르게 설정가능
3) 범례 추가하기 : label로 설정 넣어줌
4) 축, 제목 입력 하기 : set으로 설정 가능
5) 텍스트 추가하기 :
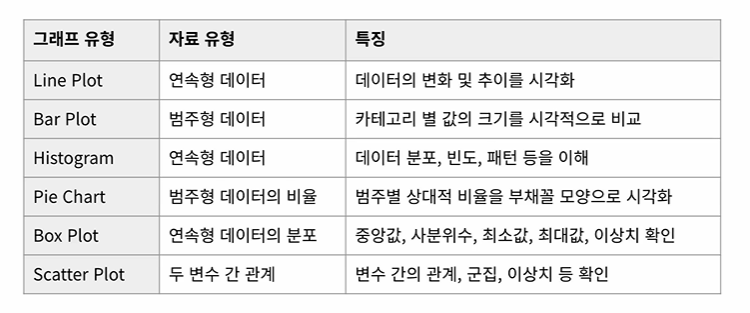
4강 - line : 시간의 변화를 나타낼때 사용하기 좋은 그래프
- bar : 범주형 그래프, 각 카테고리의 크기를 비교할때 사용하는 그래프
- histogram : 연속되는 데이터의 분포를 나타내는 그래프 , 빈도를 시각화해 알아보는 그래프
- pie: 전체 데이터에서 각 부분의 비율을 보여주는 그래프 > 원 그래프
- 🔥box plot : 데이터의 통계적 특성을 파악하기 용이한 그래프, 최솟값,최댓값등을 표기
-scatter : 점들이 몰려있으면 상관관계 o > 변수들의 상관관계를 알고 싶을때 사용 
세션 필기
-
series = 열
ex)
ages = pd.Series([25, 30, 35, 28, 32]) ----> series : 매서드 pd가 클래스
print("Series 예제:")
print(ages) -
df=pd.DataFrame(data) > 판다스 라이브러리의 dataframe 메소드를 가지고 data에 있는 값을 데이터프레임으로 만들어주고 df라는 변수에 할당한것.
-
dataframe에는 딕셔너리 형태가 가장 적합하나 다른 형태도 가능은함
-
메서드는 뒤에 무조건 괄호. ex)dmsk()
-> 괄호 없으면 속성 -
메서드 = 동사, 특성, 값 할당 불가
-
속성 = 명사 , 기능, 값 할당 가능, 값 읽어올 수 있음
ex) column , index--> 속성
-->매서드 -
CSV 파일 읽기 기본
가장 중요!! ⭐🔥 매우 중요한 식!
df = pd.read_csv('파일경로/파일명.csv') -
결측치 처리에 따라 예측값이 달라짐
-
0이면 false 1이면 트루
-
loc만 끝에 포함
-
iloc는 끝에 안 포함
-
or기호 : |
-
isin으로 in을 표현 !

안녕하세요! 마케터를 꿈꾸는 취준생입니다 :)