💚 = 클래스지만 함수처럼 동작
💙 = 매서드(객체가 수행할 수 있는 동작이나 기능을 나타냄) => 객체 뒤에 붙으면 매서드 , 아님 함수!
🤎 = dataframe의 속성
💜 = 함수
💛 = 파라미터(매개변수)
⭐헷갈린 개념
- 범주형 데이터 = 정해진 몇가지 "카테고리"만 가지는 데이터.
=> 계산하지않고, 그냥 구분만 하는 데이터
=> ex) 남자+여자
=> object → 문자열로 저장된 범주형 (예: "male", "female")
category → 진짜 범주형 타입 (메모리도 적게 쓰고 더 빠름)- Series 는 항상 Name,dtype를 가짐
Sex
male 577
female 314
Name: count, dtype: int64
=> 그래서 항상 마지막 줄이 나옴!- .1f
: .1=소수점 1자리까지 표시하겠다(반올림)
ex) .0f=정수 , .2f=소수점 2자리
: f 소수형(float) 표현
ex) 6.3f = 전체가 6자리로 맞춰지고 소수점 아래는 3자리
💙1. describe()
- 가장 중요한것 : 데이터의 분포 형태 파악하는것
print("=== 숫자형 변수 기술통계 ===")
titanic.describe()
-> print o/x : 글 / 표로 출력
1) 상세 백분위수 확인법
- 💛percentiles :퍼센타일(백분위수)은 전체 데이터를 100칸으로 나눈 것
detailed_stats = titanic.describe(percentiles=[.1, .25, .5, .75, .9, .95])
-> ✅해석 : describe() 함수가 추가로 계산할 백분위수(percentile)를 지정할 수 있게 해줘.
print("=== 상세 백분위수 분석 ===")
print(detailed_stats['Age'].round(2))
percentiles=[.1, .25, .5, .9, .95]라고 하면,
10% 지점 (.1) → 전체에서 제일 낮은 값부터 10% 위치
25% 지점 (.25) → 4등분 했을 때 첫 번째 점 (1사분위)
50% 지점 (.5) → 딱 중간 값 (중앙값, 2사분위)
90% 지점 (.9) → 위에서 90% 지점
95% 지점 (.95) → 거의 끝에 있는 값
즉, 이건 "몇 번째쯤 되는 값이 궁금해!" 라고 지정하는 거야.
- 💜round() : 소수 ()자리 수 까지만 보여주게 지정하는 함수
- round(2)
2) 범주형 데이터 확인법
-1) 범주형 변수 포함 전체 분석
titanic.describe(include='all')
-> incloud= 데이터 타입 고르는 옵션!
describe(include=None) => 기본은 none이 숨겨져있음!
=> all : 숫자형+문자형+날짜형 등 모든 컬럼을 다 보여줘!
-2) 특정 컬럼만 보고 싶을 경우
titanic[['Fare', 'Age']].describe()
-> titanic에 범위 지정
-3) 범주형 데이터만 보고 싶을때
titanic.describe(include=['category'])
-> count,unique,top,freq 값이 나오는데
category타입으로 컬럼들이 바뀌어 있어야 이 결과가 나옴.
2.범주형 데이터 분석
value_counts() 를 활용한 빈도와 비율 이해
sex_counts = titanic['Sex'].value_counts()
sex_ratios = titanic['Sex'].value_counts(normalize=True)
print("=== 성별 분포 ===")
print("빈도:")
print(sex_counts)
print("\n비율:")
print(sex_ratios.round(3))
- normalize=True : 비율(퍼센트)처럼 보여줘!
male 0.648
=> 남자 64.8% 로 해석
3.분포의 형태 파악하기
- 이상치 영향 의심 > 평균과 중위수의 차이가 클때
=> 이런경우 평균보다는 중위수가 데이터의 중심을 더 잘 나타낸다. 이상치의 영향이 적기 때문 ( 평균이 왜곡되기 때문에 중간값인 중위수를 보는게 맞음 )- 이상치가 안 좋은 이유 : 전체 평균이 왜곡되기 때문
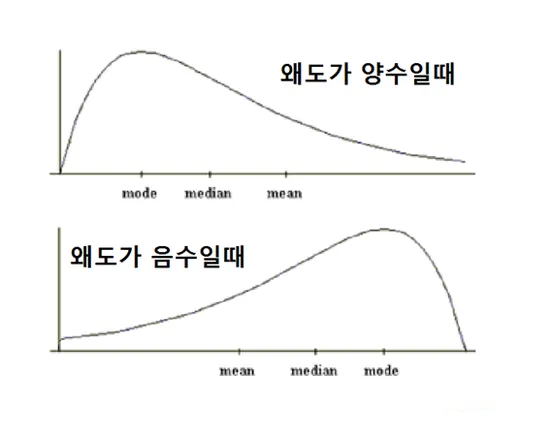
- 왜도
- 양수 왜도 = 오른쪽 꼬리 = 이상치 오른쪽 위치
- 음수 왜도 = 왼쪽 꼬리 = 이상치 왼쪽 위치
= 왜도가 커질수록 이상치가 있다는 신호
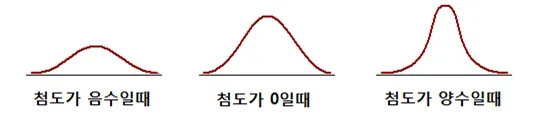
- 첨도
- 첨도 > 3: 정규분포보다 뾰족한 분포
- 첨도 < 3: 정규분포보다 평평한 분포
- 음수
- 이상치 거의 x, 납작,
- 0근처
- 정규 분포 같은 이상적인 모양 , 이상치 중간
- 양수
- 엄청 뾰족 , 값들이 가운데 몰려 잇으며 양쪽 끝에도 좀 있음 , 이상치 있을 확률 높
- physon에서 치우침 판단하는 방법
if mean_age > median_age:
print("→ 평균 > 중위수: 오른쪽으로 치우친 분포")
print(" (고령자 일부가 평균을 끌어올림)")
else:
print("→ 평균 ≤ 중위수: 왼쪽으로 치우친 분포")
=> 이렇게 값으로 비교해 판단
- 추가 매서드 정리
- 💙💜dropna() : NaN 결측치를 제거해주는 함수
- 💙💜skew() : 왜도를 계산해주는 메서드
- 💙💜kurtosis() : 첨도를 계산해주는 메서드
- 상관관계 분석
1)상관관계 vs 인과관계 : 상관관계는 두 변수가 함께 변하는 정도를 나타낼뿐. 다른 인과관계는 x
2) 💙.corr() : 여러 숫자 데이터들 사이의 상관관계를 한 번에 계산해주는 메서드
-> 0부터 1까지의 숫자로 얼마나 관련 있는지를 계산해주는 메서드
- 0.7 이상: 매우 강한 상관관계
- 0.3~0.7: 강한 상관관계
- 0.1~0.3: 중간 상관관계
- 0.1 미만: 약한 상관관계
3) 관련 함수- 💙.drop() Series에서 항목 제거
- 💙.abs() 값의 절댓값 반환
- 💙.sort_values() 값 기준으로 정렬
- 💙.reindex() 순서를 바꿔줌
- 💜print() 출력해줌 (파이썬 내장 함수)
- 💜abs() 절댓값 구해줌 (전역 함수)
4) 조건 나열
-1) 여러 조건 나열
if 조건1 else if 조건2 else
-2) 단일 조건 나열
<값1> if <조건> else <값2>
