
들어가며
지난 포스트에서 eBPF가 무엇인지에 대해 알아봤다. 이번 포스트에서는 eBPF Map을 어떻게 정의하고 사용하는지에 대해 정리 해보도록 하겠다.
Remind
eBPF Map은 eBPF 프로그램이 수집한 정보를 저장, 상태 공유의 목적을 가진 일종의 DB로, 데이터는 key-value 형태로 저장되고, ring buffer, hash table 등으로 구현이 가능하다. Kernel Level뿐만 아니라 User Level에서도 eBPF Map에 저장된 데이터에 접근 가능하다.
eBPF Map 정의
Legacy Map부터 BTF(BPF Type Format) 스타일 Map 정의 방식을 차례대로 살펴 보겠다.
Legacy
struct bpf_map_def my_map = {
.type = BPF_MAP_TYPE_HASH,
.key_size = sizeof(int),
.value_size = sizeof(int),
.max_entries = 100,
.map_flags = BPF_F_NO_PREALLOC,
} SEC("maps");위와 같이 Map을 정의하는 것이 Legacy 방식이다. 이 방식은 eBPF 라이브러리 또는 Linux uapi에서 제공하는 타입을 사용했고, ELF 섹션이 존재 해야한다. 하지만 이러한 방식은 key-value의 타입 정보가 손실된다는 문제가 있다.
.key_size = sizeof(int),
.value_size = sizeof(int),위 코드를 보면 sizeof(int)로 설정이 되어 있는데, 이는 컴파일 과정에서 단순한 정수 4로 계산되어 들어간다. 따라서 컴파일 된 후 eBPF ELF 파일의 maps 섹션에 저장될 때는
key_size = 4
value_size = 4이런 형태로 저장되고, eBPF 도구들이 Map을 로드할 때 key-value 값이 각각 4byte라는 정보만 알 수 있는거고, 정확한 자료형 정보를 알 수 없게 되는 문제가 있다.
BTF(BPF Type Format) 스타일 Map
앞선 Legacy 형태의 Map이 가지는 문제를 해결하기 위해 새롭게 나온 eBPF 맵 정의 방식이다.
#define __uint(name, val) int (*name)[val]
#define __type(name, val) typeof(val) *name
#define __array(name, val) typeof(val) *name[]
#define __ulong(name, val) enum { ___bpf_concat(__unique_value, __COUNTER__) = val } name
struct my_value { int x, y, z; };
struct {
__uint(type, BPF_MAP_TYPE_ARRAY);
__type(key, int);
__type(value, struct my_value);
__uint(max_entries, 16);
} icmpcnt SEC(".maps");BTF 스타일의 Map은 자료형 보존을 위해 (1) 섹션 이름 변화, (2) 매크로 사용 두 부분에서 Legacy 방식과 차이가 있다. 먼저 SEC("maps") 대신 SEC(".maps")를 사용함으로써 linux/unix 시스템에서 .data, .text와 같이 어떤 값이 들어가는 공간이라는 의미를 eBPF 프로그램을 커널에 로드하는 libbpf에 알리는 방식으로 바뀌었다.
#define __type(name, val) typeof(val) *name
...
__type(key, int);
__type(value, struct my_value);
...그리고 key_size = sizeof(int) 선언 방식 대신 매크로를 활용해서 int형 포인터를 선언한다. 이는 int 타입을 가리키는 key가 있고, struct my_value를 가리키는 value라는 포인터가 있다고 기록함으로써 linbbpf는 이 정보를 통해 key가 가리키는 대상이 int, value가 가리키는 대상이 struct my_value라는 구조체 형태임을 유지하여 기존 legacy 방식의 문제를 해결했다.
실습
btf 방식과 legacy 방식의 차이를 실습을 통해 알아보도록 하자.
실습환경
OS Version: ubuntu 64-bit arm server 22.04.5
Kernel Version: 5.15.0-164-generic
실습 환경 준비
sudo apt-get update sudo apt-get install -y clang llvm libbpf-dev linux-tools-common linux-tools-generic linux-tools-$(uname -r)
legcy.c
#include <linux/bpf.h>
#include <bpf/bpf_helpers.h>
// 레거시 방식: SEC("maps") 사용, 단순 크기(sizeof)만 지정
struct bpf_map_def SEC("maps") my_legacy_map = {
.type = BPF_MAP_TYPE_ARRAY,
.key_size = sizeof(int),
.value_size = sizeof(int),
.max_entries = 1,
};
char _license[] SEC("license") = "GPL";btf.c
#include <linux/bpf.h>
#include <bpf/bpf_helpers.h>
// BTF 방식: SEC(".maps") 사용, 매크로를 통해 실제 타입(int) 전달
struct {
__uint(type, BPF_MAP_TYPE_ARRAY);
__type(key, int);
__type(value, int);
__uint(max_entries, 1);
} my_btf_map SEC(".maps");
char _license[] SEC("license") = "GPL";앞서 확인한 내용대로 매크로를 사용, 섹션 네이밍 정보 두 가지 부분을 차이로 두고 예제 코드를 작성했다. 이를 컴파일 해주자.
clang -O2 -g -target bpf -I/usr/include/$(uname -m)-linux-gnu -c legacy.c -o legacy.oclang -O2 -g -target bpf -I/usr/include/$(uname -m)-linux-gnu -c btf.c -o btf.o컴파일을 정상적으로 완료하면 object file이 정상적으로 생성됐을거고 llvm-readelf 명령으로 파일 안에 어떤 섹션이 만들어졌는지 확인 해보자.
llvm-readelf -S legacy.o | grep maps
llvm-readelf -S btf.o | grep maps
결과를 보면 이전 설명과 같이 legacy엔 maps, btf엔 .maps로 섹션이 저장된 것을 확인할 수 있다. 그리고 bpftool을 활용해서 생성한 오브젝트 파일을 덤프를 떠서 파일 구조를 확인해보자.
bpftool btf dump file legacy.o
bpftool btf dump file btf.o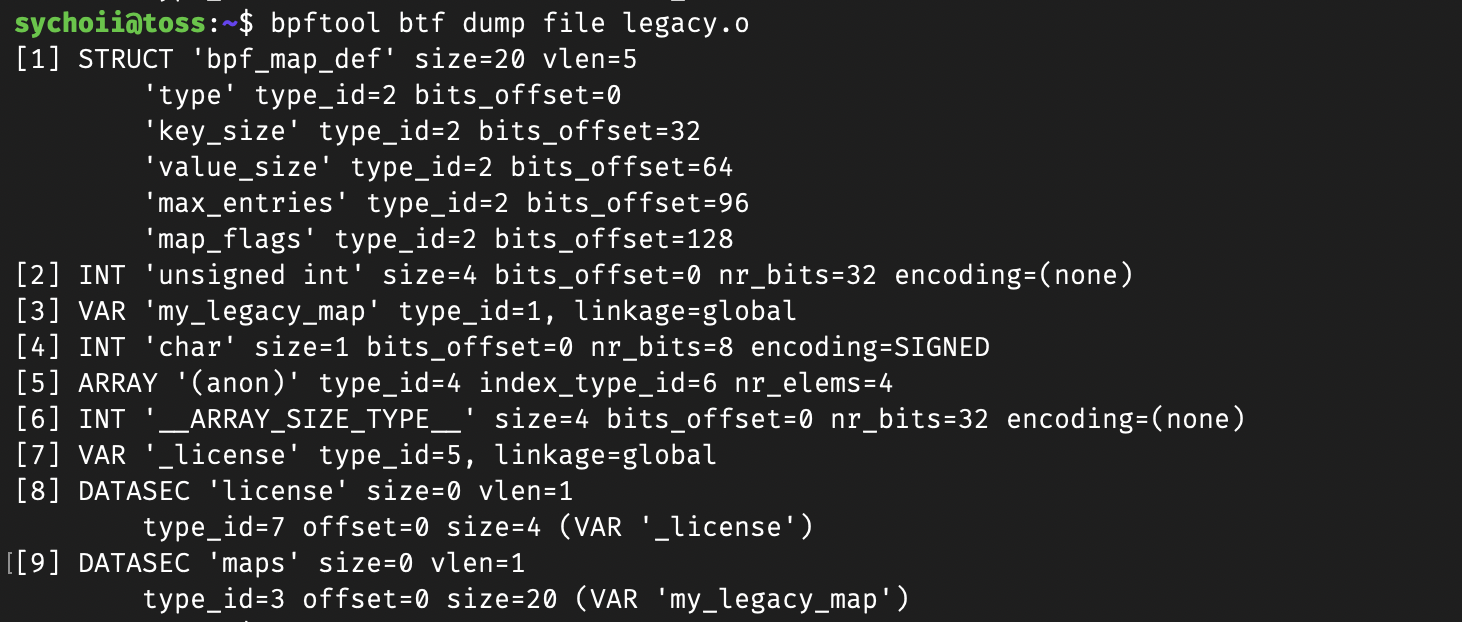
먼저 legacy 덤프 파일을 보면 [1] STRUCT에 필드명으로 key가 아니라 key_size가 기록 되어 있고, key_size의 타입은 type_id=22라고 되어 있다.
즉, 타입 정보에 기록된 것은 맵 구조체 안에 key_size라는 변수가 있고, 그 변수 타입은 unsigned int라는 정보만 담겨 있어 맵에 저장될 때 실제 키 데이터의 타입 정보는 담겨 있지 않은 것을 확인할 수 있다.
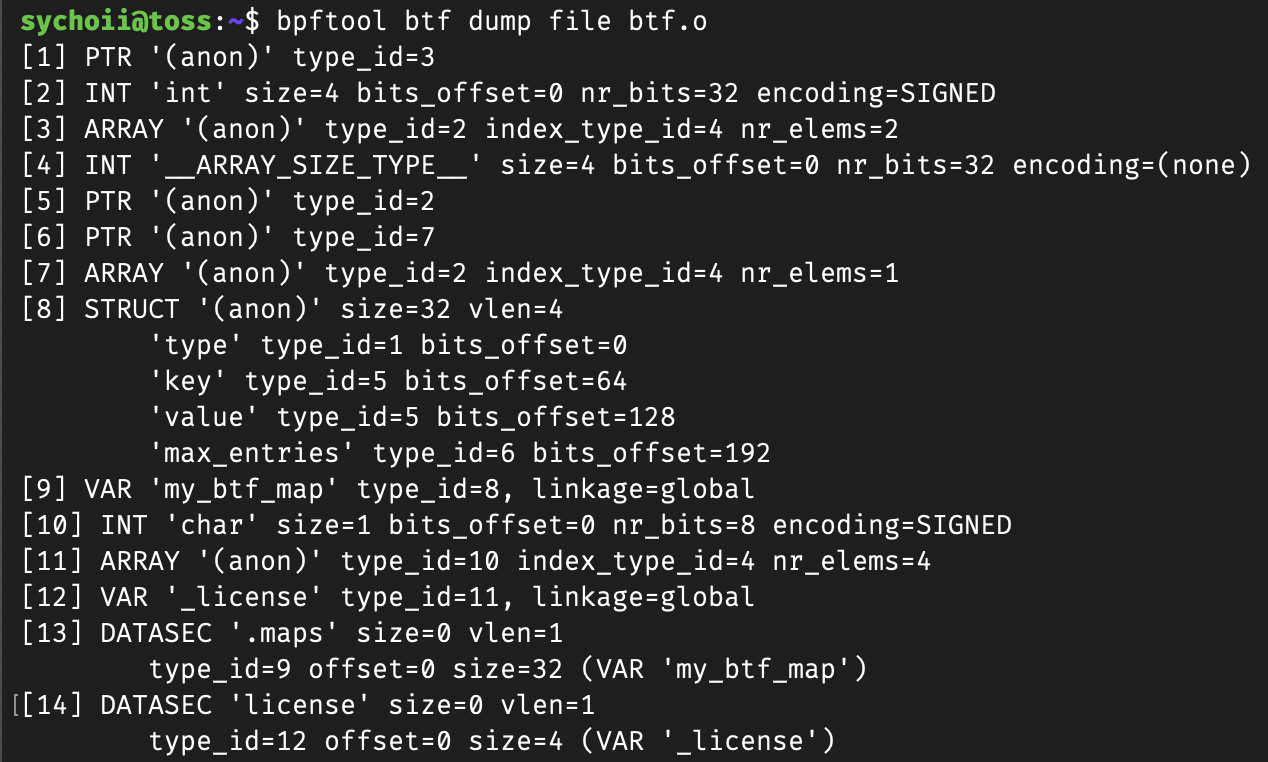
다음 btf 덤프 파일을 보면 key 필드가 존재하고 타입은 type_id=5라는 것을 알 수 있다. 5번 섹션을 보면 PTR 즉, 포인터이고 이 포이터가 가리키는 곳은 type_id=2라는 것을 알 수 있다. 2번을 보면 정확히 INT 'int ...'라고 기록 되어 있는 것으로 보아 기존 레거시 방식과 달리 자료형을 정확히 파악할 수 있다.
BPF Map 생성
eBPF 프로그램에서 Map은 User Level에서 생성된다. libbpf와 같은 로더 라이브러리는 컴파일 된 ELF 파일에서 Map 선언을 가져와 자동으로 Map을 생성한다.
Map은 수동으로도 생성할 수 있다. 이때 System Call의 BPF_MAP_CREATE 명령을 사용하거나, 이와 같은 기능을 가진 라이브러리를 사용하여 생성할 수도 있다. Map은 무한정 생성할 수 있지 않고, eBPF 프로그램 당 64개로 제한된다.
개수가 제한되는 이유는 #define MAX_USED_MAPS 64라는 매크로 상수가 64로 하드코딩 되어 있고, FD(File Descriptor) 자원의 독점 방지를 위해서 제한이 있다. eBPF Map이 User Level 어플리케이션과 통신을 위해 내부적으로 FD를 부여받는데, 단일 프로그램이 너무 많은 맵과 연결되어 있으면 시스템 리소스 관리 복잡도 증가, 고갈 문제가 발생할 수 있어 제한된다.
이러한 제한 사항을 우회?하기 위해 Tail Call, Map-in-Map과 같은 아키텍처 패턴을 채택하고 권장한다고 한다. 이 내용은 이후에 추가로 정리 해보도록 하겠다.
실습
해당 실습은 Map 개수 제한을 확인하기 위해 간단하게 진행했다.
cat << 'EOF' > generate_maps.sh
#!/bin/bash
NUM_MAPS=$1
FILE_NAME="test_${NUM_MAPS}_maps.c"
echo '#include <linux/bpf.h>' > $FILE_NAME
echo '#include <bpf/bpf_helpers.h>' >> $FILE_NAME
# 1. 지정된 개수만큼 맵 선언
for i in $(seq 1 $NUM_MAPS); do
cat << MAP_DEF >> $FILE_NAME
struct {
__uint(type, BPF_MAP_TYPE_ARRAY);
__type(key, int);
__type(value, int);
__uint(max_entries, 1);
} map_$i SEC(".maps");
MAP_DEF
done
# 2. XDP 프로그램 작성 및 맵 참조
echo 'SEC("xdp")' >> $FILE_NAME
echo 'int test_prog(struct xdp_md *ctx) {' >> $FILE_NAME
echo ' int key = 0;' >> $FILE_NAME
for i in $(seq 1 $NUM_MAPS); do
echo " bpf_map_lookup_elem(&map_$i, &key);" >> $FILE_NAME
done
echo ' return XDP_PASS;' >> $FILE_NAME
echo '}' >> $FILE_NAME
echo 'char _license[] SEC("license") = "GPL";' >> $FILE_NAME
echo "✅ $FILE_NAME 파일 생성 완료!"
EOF
chmod +x generate_maps.sh입력한 개수만큼 Map을 선언하고, 선언된 Map들을 모두 참조하는 eBPF C코드를 만들어주는 스크립트다.

# 1. 64개 맵을 사용하는 코드 생성 및 컴파일
./generate_maps.sh 64
clang -O2 -g -target bpf -I/usr/include/$(uname -m)-linux-gnu -c test_64_maps.c -o test_64_maps.o
# 2. 65개 맵을 사용하는 코드 생성 및 컴파일
./generate_maps.sh 65
clang -O2 -g -target bpf -I/usr/include/$(uname -m)-linux-gnu -c test_65_maps.c -o test_65_maps.oclang을 통해 64개, 65개 코드를 각각 만들고 컴파일한다. 컴파일 단계에서 이를 제한하진 않기 때문에 정상적으로 오브젝트 파일이 생성된다.
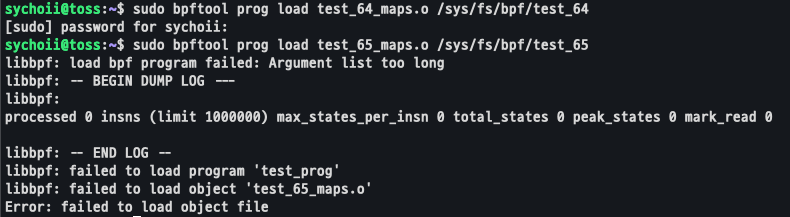
sudo bpftool prog load test_64_maps.o /sys/fs/bpf/test_64
sudo bpftool prog load test_65_maps.o /sys/fs/bpf/test_65이제 생성된 각각의 오브젝트 파일을 이용해 로드 해보면 65개만 에러가 발생한다는 것을 확인할 수 있다. 에러 메세지도 보면 "Argument list too long" 즉, 개수를 초과하여 Map이 생성되지 않았다는 것을 확인할 수 있다.
libbpf
앞서 설명한 Map 생성 기능을 제공하는 라이브러리 중 하나가 libbpf다.
LIBBPF_API int bpf_map_create(enum bpf_map_type map_type,
const char *map_name,
__u32 key_size,
__u32 value_size,
__u32 max_entries,
const struct bpf_map_create_opts *opts);
struct bpf_map_create_opts {
size_t sz; /* size of this struct for forward/backward compatibility */
__u32 btf_fd;
__u32 btf_key_type_id;
__u32 btf_value_type_id;
__u32 btf_vmlinux_value_type_id;
__u32 inner_map_fd;
__u32 map_flags;
__u64 map_extra;
__u32 numa_node;
__u32 map_ifindex;
};해당 코드는 /tools/lib/bpf/bpf.h의 일부로, 해당 bpf_map_create 함수는 libbpf 런타임 중 Map을 생성하는 데 사용한다.
Map 사용
Map은 Kernel Level에서 사용하는 것과 User Level에서 서로 다른 방식으로 조작된다.
Kernel Level에서 Map 사용
Kernel Level에서 동작하는 eBPF 프로그램이 Map을 사용할 때는 Helper 함수를 통해 Map과 상호작용하고, 이는 해당 함수에 정의되어 있다.
bpf_helper_defs.h 파일에 기능들이 담겨 있는 것을 알 수 있다.
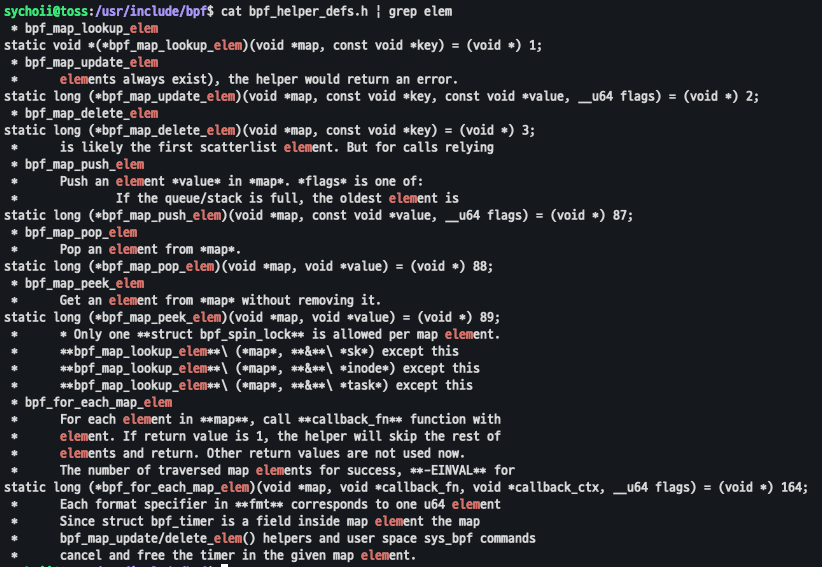
bpf_map_lookup_elem을 통해 Map의 요소를 읽고, bpf_map_update_elem을 사용하여 업데이트, bpf_map_delete_elem을 사용하여 삭제를 할 수 있다. 외에도 bpf_for_each_map_elem과 같이 루프 기능, bpf_redirect_map과 같은 패킷 리다이렉션, bpf_perf_event_output 메세지 전송 등과 같은 기능도 제공한다.
User Level에서 Map 사용
User Level에서 대부분 System Call 명령을 통해 BPF_MAP_LOOKUP_ELEM 읽기, BPF_MAP_UPDATE_ELEM 업데이트, BPF_MAP_DELETE_ELEM 삭제 기능을 지원한다. 하지만 Map의 유형에 따라 지원하는 기능이 달라 Map 별로 지원하는 명령을 확인해야 한다.
마치며
이번 포스트에선 eBPF Map에 대해 조금 더 깊게 알아봤다. 다음 포스트에선 Verifier에 대해 정리 해보도록 하겠다.
