
들어가며
eBPF 기반 탐지 도구들을 컨테이너 환경에서 운용을 한다고 할 때 컨테이너가 급작스럽게 삭제 또는 노드가 다운된다면 수집된 데이터들이 유실 될 가능성이 존재하지 않을까라는 생각이 들었다. 데이터가 유실 될 경우 보안 시스템의 신뢰성 저하는 당연하고 위협 행위가 발생했을 때 이를 대처하기 어려울 것이다.
따라서 eBPF 기반 도구들에 의해 수집된 데이터를 안전하게 저장하고 사용할 수 있게 하는 perf buffer와 bpf ring buffer에 대해 알아보도록 하겠다.
eBPF Map
우선 perf buffer와 bpf ring buffer는 모두 eBPF Map이다. eBPF Map이란 Linux 커널 내에서 동작하는 eBPF Program과 User Level에서 동작하는 어플리케이션 간에 데이터를 주고 받을 수 있도록 하는 공유 데이터 저장소를 말한다. 이때 데이터는 key-value 형태로 저장되고, bpf ring buffer, hash table 등 여러가지 자료구조로 구현 가능하다.
데이터 흐름
위 그림은 대략적인 데이터 흐름에 대한 예시이다. Kprobe라는 훅에 부착된 eBPF Program이 수집한 데이터를 Helper 함수라고 하는 API를 통해서 Map에 데이터가 전달된다. 역으로 참조할 때도 Helper 함수를 이용한다. User Level에 위치한 어플리케이션이 Map에 접근할 때는 bpf() System Call을 통해 접근한다.
접근시 사용 API
- 어플리케이션
BPF_MAP_LOOKUP_E_ELEM: 데이터 조회BPF_MAP_UPDATE_ELEM: 데이터 추가 / 수정BPF_MAP_DELETE_ELEM: 맵 데이터 삭제- eBPF 프로그램
bpf_map_lookup_elem(): 맵 조회bpf_map_update_elem(): 맵 데이터 업데이트bpf_map_delete_elem(): 맵 데이터 삭제
Perf Buffer
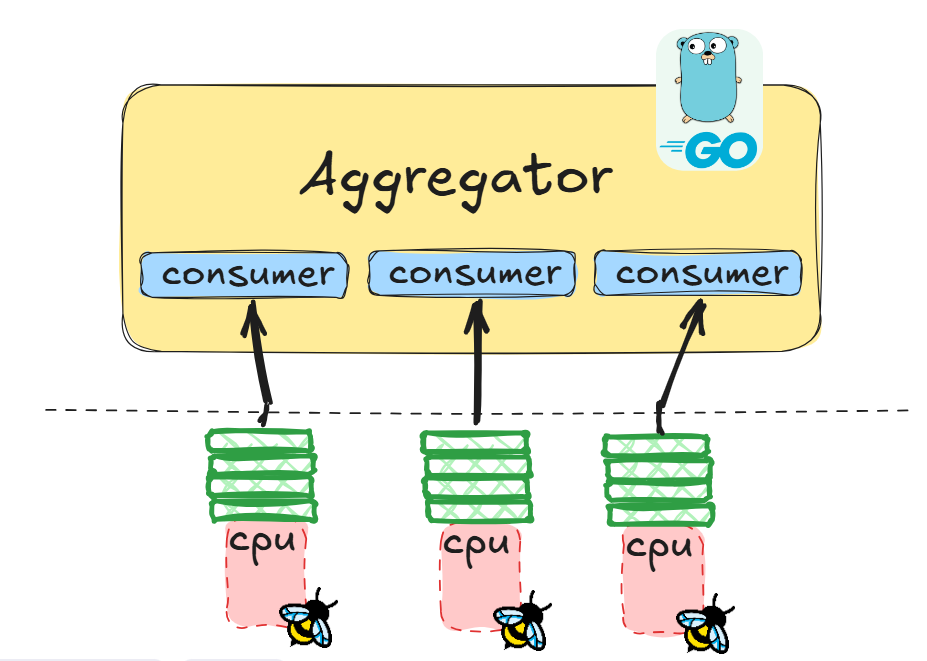
이미지 출처: https://kubefront.net/system/ebpf/ring-buffer-vs-perf-buffer/
앞서 언급한 Map의 형태중 하나가 Perf Buffer이다. Perf Buffer는 cpu 코어 당 개별적인 Ring Buffer를 독립적으로 할당하는 방식이다. Buffer를 개별적으로 할당하기 때문에 데이터 동기화를 위한 Lock에 대한 경합이 발생하지 않아 Write 작업에서의 성능이 매우 좋다는 장점이 있다.
하지만 cpu 간 이벤트 순서 지정이 어렵고, cpu 코어당 개별 buffer 할당 방식으로 인해 이벤트가 특정 buffer에 몰리는 상황이 발생하면 시스템 전체적으로 봤을 때 메모리 낭비가 발생한다. 또한, Perf Buffer는 데이터가 들어오면 User Level에 Alert를 보내는데, 이벤트가 폭증하면 이 과정에서 과도한 Context Switching이 발생하여 Buffer Overflow, 데이터 유실과 같은 문제가 발생할 수 있다.
cpu간 ring buffer 공유를 통해 메모리 활용 효율을 높이고, 여러 cpu에 걸쳐서도 시간상 순차적으로 발생하는 이벤트 순서를 유지하기 위해 리눅스 커널 5.8 버전부터 bpf Ring Buffer를 도입하여 사용한다.
BPF Ring Buffer
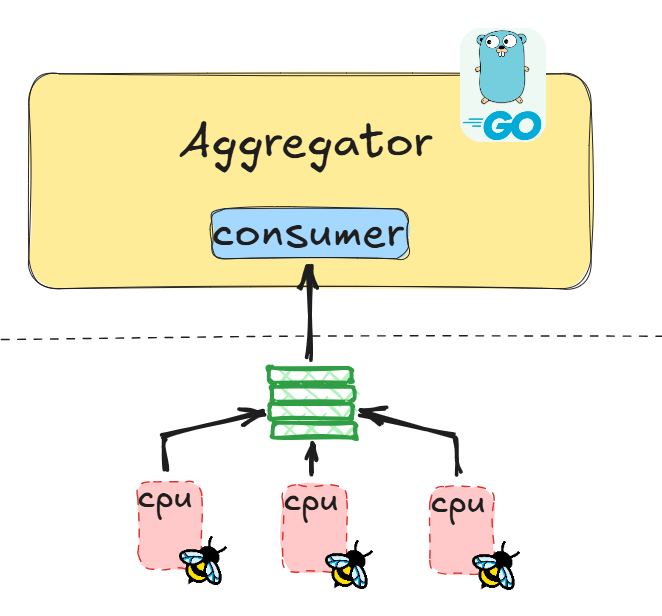
BPF Ring Buffer는 커널 이벤트나 데이터 저장을 위해 모든 CPU가 공유하는 순환 buffer를 사용한다. 모든 cpu 코어가 하나의 ring buffer를 공유하기 때문에 메모리 낭비가 적고, 이벤트 폭증이 발생해도 데이터 유실을 Perf Buffer 방식보다 효과적으로 방지할 수 있다.
또한, 데이터 전송시에 전통적인 I/O 방식이 아닌 mmap 방식을 사용해서 데이터 복사 오버헤드를 줄인다.
| 비교 | I/O | mmap |
|---|---|---|
| 전송방식 | 디스크 → 커널 페이지 캐시 → 유저 버퍼 복사 | 디스크 → 커널 페이지 캐시 ⇄ 유저 가상 메모리 직접 링크 |
| 메모리 복사 횟수 | 2회 (디스크→커널, 커널→유저) | 1회 (디스크→커널/유저 공유 메모리) |
| 시스템콜 호출 횟수 | 데이터를 읽을 때마다 매번 호출 | 최초 매핑 시 1회만 호출 (이후 포인터로 접근) |
| 메모리 효율성 | 커널과 유저 공간에 중복 데이터 존재 | 공간 공유로 메모리 낭비 없음 |
디스크 파일 내용을 읽어오는 과정을 예로 비교 해보면 위와 같다.
mmap이 호출되면 OS 내부에서는 다음과 같이 가상 메모리 조작이 일어난다.
- 가상메모리 영역 할당
mmap()을 호출하면 커널은 해당 프로세스의 가상 메모리 공간에 요청한 크기만큼의 빈 주소영역을 확보한다. - 페이지 테이블 매핑
확보한 가상 주소가 실제 대상을 가리키도록 페이지 테이블을 설정한다. - 페이지 폴트, 로드
어플리케이션이 매핑된 주소의 포인터를 통해 데이터에 접근하는 순간 인터럽트를 발생시킨다. 커널은 이 인터럽트를 받아 파일 내용을 커널 메모리로 복사하고 확보한 가상주소와 동기화 시킨다.
이 과정을 거쳐 User Level에서는 이후 System call 없이 ptr[0]과 같은 방식으로 데이터에 접근할 수 있다. BPF Ring Buffer는 이러한 방식을 채택하여 사용하기 때문에 Perf Buffer와 달리 오버헤드가 적고 안정성을 극대화 할 수 있는 것이다.
정리
일반적으로 사용되는 eBPF 기반 탐지 도구들이 이러한 방식을 채택하기 때문에 데이터 손실과 같은 치명적인 문제를 최소화 하여 안정적으로 운용될 수 있는 것이다.
