

이번 4주차에서는 Kubernetes 환경에서의 네트워크 포렌식 프로젝트를 보다 실질적인 분석 단계로 발전시키기 위해, 탐지 결과의 정확도와 이후 분석 과정의 신뢰도를 함께 높이는 구조 설계 및 구현에 집중하여, 필터링-탐지-패턴매칭–상관분석–시각화로 이어지는 전체 흐름을 재정비하는 것을 주요 목표로 설정했습니다.
이를 위해 탐지 프레임워크를 재정립 및 고도화, Tetragon 정책 재정비, 실습 환경 재구축, Fluentd 기반 2차 필터링, 로그 상관분석, Grafana 기반 공격 재구성 시각화 방향 검토로 6개의 파트를 나누어 프로젝트를 진행했습니다.
각 파트는 독립적으로 수행되었으나, 최종적으로는 하나의 탐지 이벤트를 기준으로 서로 다른 로그를 연결하고, 그 맥락을 분석·재구성할 수 있도록 상호 연계 가능한 구조를 만드는 데 초점을 두고 설계를 진행했습니다. 이를 통해 단순 탐지 결과 나열이 아닌, 실제 포렌식 분석으로 이어질 수 있는 기반을 마련하고자 했습니다.
탐지 방향 재정립 및 고도화
지난주에 정립하였던 탐지 방향은 단일 탐지 결과만으로 공격 여부를 단정하기에는 정확도와 신뢰도가 낮아진다는 한계가 있었습니다. 이에 멘토님의 피드백을 바탕으로 탐지 방향을 재정립하여 탐지 고도화 프레임워크를 수립했습니다. 새롭게 수립한 다중 탐지 기법의 상호 보완을 통한 복합 탐지 프레임워크는 한 가지 탐지로는 판단이 모호한 지점을 다른 관점의 데이터로 함께 해석함으로써 사건의 맥락을 형성하는 것에 초점을 두었습니다. 이 과정은 특정 탐지 기법 하나로 모든 공격을 포괄하려는 시도가 아니라, 각 기법이 갖는 탐지 범위의 한계를 서로 보완함으로써 개별 탐지의 hole을 점진적으로 메워나가는 방식입니다.
이와 같은 접근은 탐지 결과의 설득력과 타당성을 높이고, 이후 쿼리 기반 분석이 임의적 해석이 아닌 논리적으로 정합된 분석 과정으로 이어지도록 하기 위한 설계이며, 본 프로젝트에서 지향하는 탐지 고도화의 핵심 방향이라고 할 수 있습니다.
해당 프레임워크는 다음 네 가지 축으로 구성했습니다.
- Hubble을 통한 룰에 기반한 지식 기반 탐지(Knowledge-based Detection)
- Hubble을 통한 공격 여부를 사전에 가정하지 않는 Baseline에 기반한 이상 탐지 (Abnomaly Detection)
- Tetragon 쿼리 검색을 통한 행위·정책 기반 탐지 (Behavior-based Detection)
- 위 내용을 종합하여 이를 토대로 Tetragon과 Hubble에서 로그 묶음을 추출한 후, 이를 상관 분석(Correlation)

Knowledge-based Detection에서는 OpenSearch 내 Alerting 기능을 활용합니다. “어떤 네트워크 패턴이 이상한지”에 대한 사전 지식을 쿼리와 Alert 조건으로 명시적으로 표현하는 방식으로 탐지를 수행하기 때문에, rule 기반 탐지라고 볼 수 있습니다. 외부 C2 통신, 리버스 쉘, 데이터 유출, 단발성 외부 접속과 같이 보안적으로 의미 있는 외부 통신이 주요 탐지 대상입니다. 이들 통신은 연결 수가 적고 지속 시간이 짧으며, 통계적으로는 평소 트래픽 패턴에서 크게 벗어나지 않는 특징을 가지기 때문에 통계 기반 이상 탐지에서는 탐지가 어려운 영역임을 확인했습니다.
Anomaly Detection에서는 OpenSearch 내 anomaly detection 기능을 활용하여, 평소 네트워크 패턴을 baseline으로 삼고 해당 패턴에서 벗어나는 통계적 편차를 이상으로 정의했습니다. DDoS 전조, 스캔류 트래픽, 웜이나 자동화된 행위처럼 짧은 시간 내 TCP 연결 수 급증, 세션 폭증, 네트워크 패턴 붕괴와 같은 통계적 행동 변화가 주요 탐지 대상입니다. 이 방식은 목적지 IP나 공격 의도보다는 네트워크 행동 자체의 변화에 초점을 둔다는 점에서 Knowledge-based Detection과 관점 차이가 있습니다.
Behavior-based Detection에서는 Tetragon을 활용하여 특정 syscall이나 binary 실행을 기준으로 실제 행위의 실체를 확인합니다. Tetragon의 역할은 행위 실체 확인 (forensic evidence) 이기 때문에 이 단계에서는 굳이 Alert를 울리지 않고 시간, 파드, 노드 기준으로 쿼리 검색을 진행하기로 했습니다.
단순히 탐지 방식을 나누는 데에서 그치는 것이 아닌, 아래와 같이 Case 별로 탐지 결과 간 상호 보완 구조를 정리하여 탐지 고도화를 진행했습니다.
- Case1: Knowledge-based Detection에서 Alert가 발생한 경우
동일 시간대 기준으로 Anomaly score를 확인하고, 동시에 Tetragon 로그를 조회하여 해당 통신을 유발한 실제 행위가 존재했는지를 검증 - Case2: Anomaly Detection에서 Alert가 발생한 경우
동일 시간대의 외부 통신 여부를 Knowledge-based Detection으로 확인하고, Tetragon 로그를 통해 실제 행위 여부를 교차 검증 - Case3: 네트워크 탐지로는 포착되지 않는 공격의 경우
Tetragon 행위를 기준으로 이후 네트워크 흐름과 통계적 변화가 있었는지를 역으로 확인
현재 탐지 프레임워크 구현 중에 있으며, 실습을 통해 발생하는 오류나 한계를 해결해나가는 과정에 있습니다.
Tetragon 정책 재정비

Tetragon 정책은 지난주 수행일지에 작성하였듯 MITRE ATT&CK Matrix를 기준으로 공격을 분류한 후 각 Technique별로 정책 설계를 완료하였고 총 약 40개의 정책 파일이 나왔습니다.
1차적으로 설계한 정책을 점검한 결과 정책 별 Hook Point와 System call 함수를 이용한 탐지 범위가 중복되는 것을 확인했습니다. 이는 프로젝트 수행 환경에 적용했을 때 노이즈로 작용할 수 있고, 같은 탐지 범위(Network, Process 등)를 갖는 정책이 서로 다른 정책 파일에 작성되어 있기 때문에 정책 관리적 차원에서도 효율적이지 못하다는 문제를 인식했습니다.
따라서 file, network, permission, process 네 가지 영역으로 정책을 재분류하는 작업을 우선적으로 진행하여 정책 관리 효율성을 증진시켰습니다. 재분류하는 과정에서 sys_open, sys_openat과 같이 유사한 기능을 하는 함수를 do_sys_openat2와 같은 함수로 변경하고 기능적으로 검증하여 정책 최적화를 진행 완료했습니다.
또한 최적화한 정책을 환경에 적용하고 노이즈를 확인하고, 정책을 수정하는 과정을 거치며 1차 Tetragon 정책 고도화를 완료했습니다.
이후 실제 공격 시나리오를 수행하고 분석을 진행한 뒤 이 과정에서 발생한 미탐, 오탐과 같은 문제들을 확인한 뒤 설계한 Tetragon 정책을 2차로 고도화 할 예정입니다.
Fluentd를 활용한 2차 필터링
Tetragon의 TracingPolicy는 커널 레벨의 함수 호출과 그 인자(Arguments)를 대상으로 하기 때문에, 복잡한 조건을 설정하거나 세밀한 MITRE ATT&CK Technique을 매핑하는 데 한계가 존재함을 확인했습니다. 특히 커널 훅(Hook) 지점에서 인자가 메모리 주소(포인터) 형태로 전달될 경우, 이를 역참조하여 문자열 전체를 조건으로 거는 것은 기술적으로 까다롭고 유연성이 떨어집니다.
이에 따라 Tetragon을 1차 필터링 도구로, Fluentd를 2차 필터링 및 태깅 도구로 정의하여 역할을 분담하였습니다. Fluentd는 사용자 공간에서 완성된 JSON 로그의 모든 필드를 파싱할 수 있어, 바이너리 경로뿐만 아니라 구체적인 인자 값, 부모 프로세스 정보 등을 복합적으로 조합한 조건 설정이 가능했습니다.
예를 들어, kubectl 명령어의 경우 Tetragon은 "바이너리가 실행되었다"는 사실 위주로 탐지하지만, Fluentd는 arguments: “get pods -A”라는 문자열 자체에 정규 표현식을 적용하여 실행 의도를 명확히 파악할 수 있습니다. 이를 통해 단순 실행이 아닌 구체적인 행위를 식별하여 'Container and Resource Discovery (T1613)'와 같은 정확한 Technique 태그를 부여합니다.
Fluentd 필터링 정책 설계를 위해 먼저 총 9개의 대항목 정책을 정의하고 이를 세분화하여 매핑 표 형태로 정리했고, 이를 토대로 로직을 적용한 필터링 정책을 설계했습니다. 아래는 로직이 적용된 Fluentd 최종 로그의 예시입니다.
{
"_index": "k8s-tetragon-2026.01.05",
"_id": "t7wujZsBQrUnxTYXFGYw",
"_version": 1,
"_score": null,
"_source": {
"process_exec": {
"process": {
"exec_id": "azhzLXdvcmtlcjoyNzIyMzQ1MDMxOTMyMDo5OTkyNg==",
"pid": 99926,
"uid": 0,
"cwd": "/tmp",
"binary": "/tmp/kubectl",
"arguments": "get pods -A",
"flags": "execve clone",
...
},
"policy": "Container and Resource Discovery - T1613",
"@timestamp": "2026-01-05T08:02:41.970963518+00:00",
"fluentd_tag": "kubernetes.tetragon"
}
}Correlation Analysis
이번주에는 탐지 이후의 분석단계를 고도화시키기 위해 상관분석 관련 자료 조사와 실습을 진행했습니다. 멘토링 때 받은 피드백을 반영하여, 상관분석은 크게 ‘같은 공격 시나리오에 대한 Tetragon 로그와 Hubble 로그의 상관분석’과, ‘정상 트래픽과 비정상 트래픽의 상관분석’으로 나누어 진행 할 예정입니다.
Tetragon 로그와 Hubble 로그의 상관분석을 위해서는 두 로그를 함께 엮을 수 있는 공통 필드가 필요했습니다. 기존 로그에서는 timestamp, pod name, namespace 정도를 공통적으로 활용 가능했으나, 해당 정보만으로는 동일 컨테이너 단위의 행위를 정확히 매칭하기에는 한계가 있음을 확인했습니다. Tetragon 로그에는 container ID가 기본적으로 포함되어 있는 반면, Hubble 로그에는 해당 필드가 출력되지 않는 구조였기 때문에 이에 따라 Hubble 로그에서도 container ID를 추출할 수 있는 방법을 조사했고, Cilium에서 제공하는 내부 정보 조회 방식을 통해 컨테이너 식별 정보를 가져올 수 있음을 확인했습니다.
해당 방식을 활용하여 OpenSearch 상에서 Hubble 로그에 container ID를 함께 출력하도록 설정했으며, 이를 통해 기존의 시간·파드 기반 매칭 방식보다 더 정밀하게 Tetragon 로그와 Hubble 로그를 동일 컨테이너 기준으로 상관분석할 수 있는 기반을 마련했습니다. 이때 container ID를 출력하기 위한 과정에서의 latency가 있어 이 부분은 분석 중에 있습니다.
이와 동시에 Kubernetes 보안 관측성 강화를 목표로 이기종 로그 상관분석 구조를 설계했습니다. 먼저 효율적인 상관관계 분석을 위해 오픈소스 Korrel8r를 분석하여 규칙 기반 쿼리 방식의 유효성을 확인했으나, OpenSearch 적용 시 Go 언어 기반 개발 공수를 고려하여 해당 설계 철학을 반영한 Python 기반 스크립트 고도화 방향으로 전략을 확정했습니다.
아키텍처 면에서는 OpenSearch Alerting과 연동되는 FastAPI 기반 상관관계 분석 스크립트를 구축했습니다. 탐지 시 Webhook을 통해 실시간으로 이기종 로그를 쿼리하고, '통합 분석 레코드'를 생성하여 Slack과 OpenSearch에 전송하는 2-Way Dispatch 구조의 PoC를 성공적으로 완수했습니다.
고도화 측면에서는 '공격 생애주기' 재구성을 위해 네트워크 세션의 시작(SYN)부터 종료(FIN)까지 추적하고, 동일 시간대의 Tetragon 프로세스 실행 내역을 병합한 '통합 공격 타임라인' 자동 생성 체계를 마련했습니다. 다만, 다중 세션 환경에서 정상 트래픽이 혼입되는 노이즈 문제는 분석의 정확도를 저해할 수 있으므로, 향후 식별자 정교화 및 필터링 강화 등 지속적인 로직 고도화를 통해 해결해 나갈 계획입니다.
마지막으로, Tetragon 로그와 Hubble 로그를 상관분석 하기 위해 해당 로그를 외부에 추출하여 전처리/상관분석을 하기 위한 스크립트 및 코드를 개발 중에 있습니다. 공통 필드로 로그를 묶은 후, 해당 로그를 어떤 기준과 관점으로 연결하여 의미 있는 상관분석 결과를 도출할 것인지에 대한 분석 방향 설정을 핵심 과제로 두고 있습니다.
Grafana Node Graph를 활용한 공격 재구성 시각화 방향 검토

프로젝트의 최종 목표는 수집된 로그를 바탕으로 "공격자가 어떤 행위를 행했는지 재구성"하는 것입니다. 이를 달성하기 위한 시각화 도구로 Grafana를 검토하였으며, 특히 Node Graph 기능이 부모 프로세스부터 자식 프로세스로 이어지는 흐름을 시각적으로 표현하는 데 적합함을 확인했습니다.
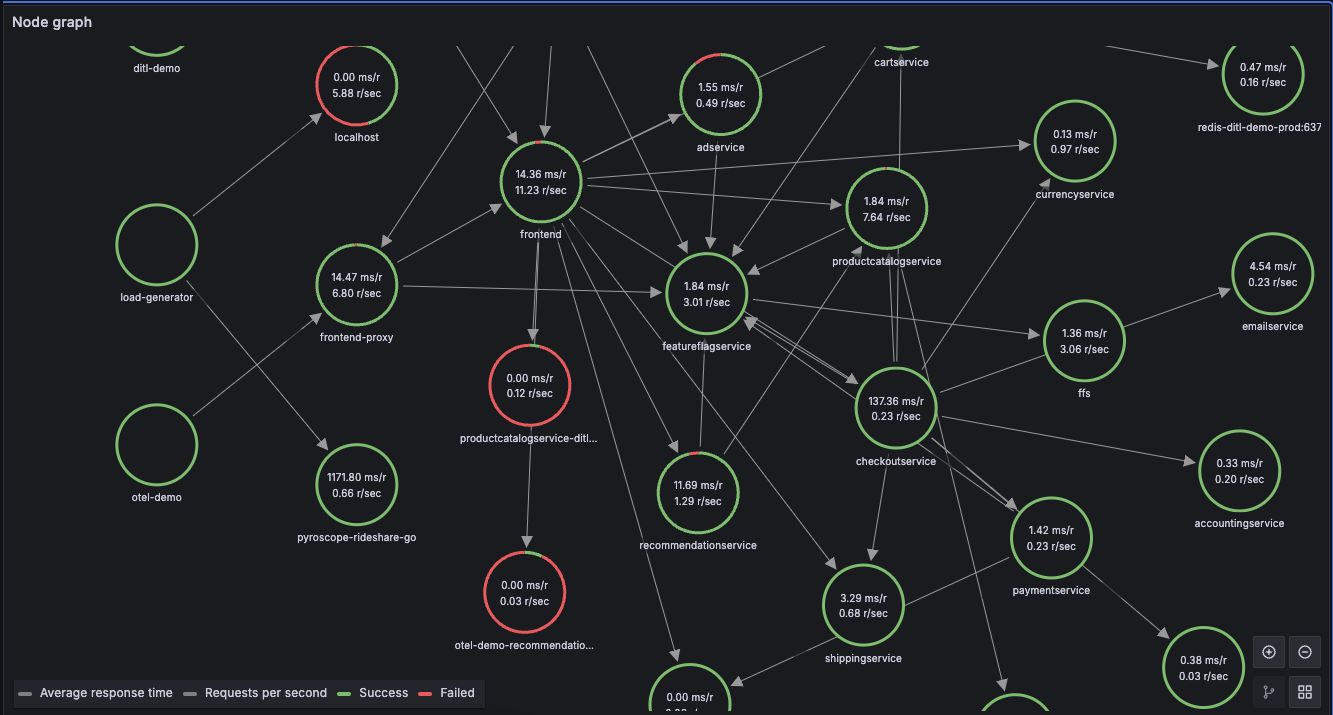
Node Graph를 활용하면 특정 쉘 실행부터 파일 읽기, 외부 사이트 통신 등의 일련의 공격 과정을 노드와 엣지의 연결 관계로 파악할 수 있을 것으로 판단됩니다. 현재는 Opensearch에 저장된 Hubble(네트워크)과 Tetragon(시스템) 로그를 추출한 후, 이를 Grafana가 인식할 수 있는 형태로 가공하여 시각화하는 파이프라인 구상을 시작하였습니다. 실시간 대응보다는 사후 포렌식 분석에 초점을 맞추고 있으므로, 앞으로 Grafana의 Alert 기능보다는 데이터의 맥락을 연결하여 보여주는 시각화 구현에 집중할 계획입니다.
