오늘의 학습
[Pandas 활용해 데이터 전처리]
- Pandas 라이브러리 불러오기
- 인덱스
- 컬럼
- Pandas 라이브러리 불러오기
[pandas 라이브러리 불러오기]
✔️ import 명령어 활용
# pandas 라이브러리 불러와서 pd라고 부른다는 의미
import pandas as pd
# 설치해야 하는 경우
!pip install pandas
[오픈소스 데이터 셋 불러오기]
✔️ seaborn 라이브러리 내 내장 데이터 활용
(seaborn: 데이터 시각화하는 라이브러리 중 하나)
import seaborn as sns
# 설치해야 하는 경우
!pop install seaborn
# 여러 데이터셋 중 tips 데이터셋 불러오기
data = sns.load_dataset('tips')
print(data)[데이터 불러오기]
📍 엑셀 / csv 데이터 불러오기
# 엑셀 파일
pd.read_excel('./파일명.xlsx') #./는 현재 내가 있는 위치 의미
pd.read_excel("tips_data.xlsx")
# csv 파일
pd.read_csv('./파일명.csv')
pd.read_csv("tips_data.csv")
# 인덱스 같이 불러오지 않을 경우
df = pd.read_csv("tips_data.csv", index_col=0)[데이터 저장하기]
📍 엑셀 / csv 데이터 저장하기
# 엑셀 파일
pd.to_excel(’파일경로/파일명.확장자’ , index = False) # index=False 저장 시 인덱스 같이 저장 X
# csv 파일
pd.to_csv(’파일경로/파일명.확장자’ , index = False)- 인덱스
❓ Pandas에서 인덱스(index): 데이터프레임(DateFrame;df), 시리즈(Series)의 각 행/요소에 대한 식별자 (SQL의 PK와 유사)
[기본 인덱스]
➖ 0부터 시작하는 정수(int) 인덱스 제공
➖ 자동 부여 인덱스
# 기본 정수 인덱스를 가진 데이터프레임 생성
df = pd.DataFrame({'A': [1, 2, 3], 'B': ['a', 'b', 'c']})[사용자 지정 인덱스]
➖ 숫자뿐 아니라 문자도 임의로 지정 가능
# 사용자가 직접 인덱스를 설정한 데이터프레임 생성
df = pd.DataFrame({'A': [1, 2, 3], 'B': ['a', 'b', 'c']},
index=['idx1', 'idx2', 'idx3'])[인덱스 활용]
➖ 데이터에 접근이나 조작 가능
df = pd.DataFrame({'A': [1, 2, 3], 'B': ['a', 'b', 'c']},
index=['idx1', 'idx2', 'idx3'])
# 특정 인덱스의 행에 접근
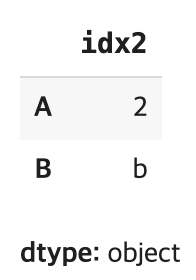
df.loc['idx2']
➡️ 인덱스 idx2에 해당하는 행의 값만 보여줌
# 인덱스를 기준으로 데이터프레임 정렬
df.sort_index()➖ set_index() 특정 컬럼에 들어있는 값을 인덱스로 활용
df = pd.DataFrame({'A': [1, 2, 3], 'B': ['a', 'b', 'c']},
index=['idx1', 'idx2', 'idx3'])
# df가 가지고 있는 특정 컬럼명을 기준으로 인덱스 설정
df.set_index('A')
➡️ A 컬럼 기준 인덱스 설정
B
A
1 a
2 b
3 c
# 불러올 때 인덱스 지정
pd.read_csv('./data/file.csv' , index_col = '컬럼정보')
pd.read_csv('./data/file.csv' , index_col = 0) # 0부터 시작➖ reset_index() 를 활용해서 현재 인덱스를 0부터 시작하는 정수로 변경
# reset_index() 의 기본 값은 drop = False
data.reset_index()
A B
0 1 a
1 2 b
2 3 c
# reset_index(drop = True) 명령어를 활용하면,
# 현재 인덱스 값을 컬럼으로 변경하지 않고 인덱스 초기화 가능
data.reset_index(drop=True)
A B
0 1 a
1 2 b
2 3 c
[인덱스 확인]
➖ DataFrame.index
df.index
#리스트 형태를 활용해서 인덱스를 새로 입력할 수 있습니다.
df.index = ['1번' , '2번' , '3번']
print(df)
➡️ 인덱스 1번, 2번, 3번으로 설정
A B
1번 1 a
2번 2 b
3번 3 c- 컬럼(Column)
❓ 컬럼: DataFrame의 열
[컬럼 특징]
➖ 고유한 라벨(이름) 보유 ➡️ 해당 컬럼의 데이터 식별하는 데 사용
➖ 다양한 유형의 데이터 형태
➖ 시리즈(Series) 객체로 구성
➖ DataFrame의 일부
➖ 해당 열 조작 & 접근할 수 있는 인터페이스 제공
[컬럼]
# Pandas 불러오기
import pandas as pd
# 데이터프레임 생성
data = {
'name': ['Alice', 'Bob', 'Charlie'],
'age': [25, 30, 35],
'gender': ['Female', 'Male', 'Male']
}
df = pd.DataFrame(data)
# 각 컬럼 출력
print(df['name'])
print(df['age'])
print(df['gender']) ➡️ 컬럼:name, age, gender
# 데이터프레임 컬럼 확인
df.columns
Index(['name', 'age', 'gender'], dtype='object')
# 특정 컬럼 데이터 확인
df['컬럼명']
df['name']
name
0 Alice
1 Bob
2 Charlie
dtype: object
[컬럼명 변경]
# rename() 메서드 활용
df = df.rename(columns={'age' : '나이', 'gender' : '남/여'})
print(df)
name 나이 남/여
0 Alice 25 female
1 Bob 30 male
2 Charlie 35 male
[컬럼 추가]
df['address'] = 'seoul'
print(df)
name 나이 남/여 address
0 Alice 25 female seoul
1 Bob 30 male seoul
2 Charlie 35 male seoul
어떻게든 하겠숴여...❕