사내 M/L 개발자 '고강빈'님의 강의자료 입니다.
1. 데이터 엔지니어링
“우리의 온라인 활동에서 나오는 데이터는 그냥 사라지는 것이 아니다.
이러한 디지털 흔적들을 모으고 분석하면 매년 1조 달러 규모의 가치를 창출하는 산업이 된다.”다큐멘터리 영화, <거대한 해킹 (The Great Hack)> 중
데이터 엔지니어링이란?
- 데이터를 수집, 저장하고 처리하기 위한 시스템을 구축하고 운영하는 일
- 이를 위한 데이터 플랫폼을 개발하고 운영하는 일
- 데이터 파이프라인을 개발 / 구축 / 운영하는 일
- ETL (Extract-Transform-Load)
⇒ 데이터 기반 의사결정을 주도하는 데이터 플랫폼과 관련된 모든 일
데이터 엔지니어가 되려면?
1) CS Fundamental
- 자료구조 & 알고리즘
- 수학 & 통계학
- 컴퓨터 구조
- 네트워크
- Linux (OS)
- CLI, Vim
- Shell Scripting
- Cronjobs
- 기타 개발 지식
- 터미널 사용법
- REST API
- Git Version Control
- …2) Programming Language
- Python (떠오르는 신예)
- Java (전통의 강자)
- Scala
- Go3) Testing
- Unit testing
- Integration testing
- Functional testing4) Database Fundamental
- SQL
- Normalization
- ACID transaction5) DBMS
- MySQL, PostgreSQL, MariaDB, Amazon Aurora, …
- MongoDB, Elasticsearch, Apache Casandra, Neo4j, Redis, …6) Data warehouse & Object Storage
- Snowflake, Presto, Apache Hive, Google BigQuery, …
- AWS S3, Azure Blob Storage, Google Cloud Storage7) Cluster computing fundamentals
- Apache Hadoop, HDFS, Managed Hadoop
- MapReduce
- Lambda & Kappa Architectures
- Amazon EMR, Google Dataproc, Azure Data Lake8) Data Processing
- Batch
- Streaming
- Hybrid9) Messaging
- Amazon SNS & SQS, Azure Service Bus, Google PubSub
- RabbitMQ, Apache ActiveMQ10) Workflow scheduling
- Apache Airflow, Google Composer, Apache Oozie, Luigi11) Monitoring pipelines
- Prometheus
- Datadog
- Sentry
- StatsD12) Infrastructure
- Containers: Docker
- Orchestration: Kubernetes, Docker Swarm, GKE
- Provisioning: Terraform, AWS CDK13) CI/CD
- GitHub Actions, Jenkins14) Data Security & Privacy
데이터 파이프라인
- 데이터를 순차적으로 전달/처리하는 시스템
- 데이터 처리 단계의 출력이 다음 단계의 입력으로 이어지는 구조
- SW 기반 자동화된 데이터 처리 시스템
- ETL
- 데이터 생성/수집/가공/저장 등 일련의 작업들
- 사람이 보기도 편하고 쓰기도 편하게끔 만드는 것이 궁극적 목표
전통적인 데이터 파이프라인: ETL
로그 스토리지, 거래정보 DB, 사용자 정보 DB 등에서 추출(Extract)해서 분석하기 편한 스키마로 변환(Transform)한 후 분석 및 시각화용 DB 또는 스토리지에 적재(Load)하는 프로세스
→ 실제 서비스 데이터가 수집되는 DB ≠ ETL에 의한 분석 DB
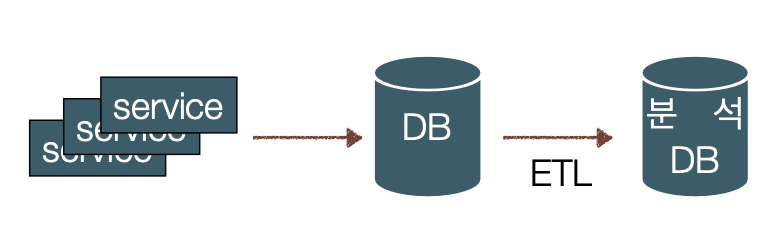


수집 → 저장 → 처리 ⇒ ELT
2. 빅데이터 아키텍처
“몇 년 동안 대중을 몰래 감시해온 저희로서는 수 많은 사람들이 자발적으로 자신의 거주지와 종교적 정치적 견해, 순서대로 정리한 친구 목록, 이메일 주소, 전화번호, 자신이 찍힌 수백 장의 사진, 현재 하고 있는 활동 정보를 공개하고 있다니 놀랍기 그지 없습니다. CIA로서는 꿈에 그리던 일이지요.”
크리스토퍼 사르틴스키, CIA 부국장
데이터 처리 방식
- Batch Processing (배치 처리, 일괄 처리)
- Stream Processing (스트림 처리, 실시간 처리)
Batch Processing
- 일괄처리
- 특정 시간 동안 데이터를 모았다가 처리하는 방식
→ 유한한 데이터셋 단위
- 특정 시간 동안 데이터를 모았다가 처리하는 방식
- 대용량 데이터 / 장기간 데이터 처리에 적합
- 분산 스토리지에 저장된 데이터를 정기적으로 추출해서 처리
- 영속성 덕분에 언제든지 재처리 가능 → 이전 데이터에서 문제가 발생했을 때 다시 처리 가능
- 실시간성에 대한 요구사항이 없을 때 이용 → 사후분석
Stream Processing
- 실시간 처리
- 데이터를 piece-by-piece로 들어오는 즉시 처리
→ 무한 데이터셋 (주기도 없고 정해진 크기도 없고) - Unbounded data processing
- 데이터를 piece-by-piece로 들어오는 즉시 처리
- 실시간 처리가 필요할 때 사용 (ex: 카카오 택시 매칭 , 자율주행)
- 과거 데이터나 재처리를 크게 고려하지 않음
→ 최근 재처리 고려할 수 있는 기술이 개발되고 있긴함 - Approximate result
- 유실데이터에 robust
Batch v.s. Stream
스트림 처리가 더 좋은가?
- 틀린 결과, 오류, 누락을 어떻게 보완할 것인가
- 늦게 전송된 데이터를 어떻게 처리할 것인가
→ 시계열성이 중요한 경우 보완이 필요함
그럼 배치 처리?
- 실시간성의 부족
⇒ 두 아키텍처는 상호 보완적 관계
Lambda Architecture: Layer
스트림 처리의 문제점을 장기 저장소와 안정적인 배치 처리로 보완하는 것이 핵심


- 원본 데이터는 장기 저장소(S3, HDFS 등)에 저장 중
- 스트림 처리: 스피드 레이어
- 실시간 처리가 가능해서 처리 결과를 빠르게 확인 가능
→ Real-time View - 데이터 보관 기간이 짧아서 일정 시간이 지난 데이터는 삭제됨
- 정확도가 배치에 비해 떨어짐
- 실시간 처리가 가능해서 처리 결과를 빠르게 확인 가능
- 배치 처리: 배치 레이어
- 과거의 데이터를 장기 저장소에 축적하고 여러 번 다시 집계 가능
→ 재처리 가능 - 대용량 데이터를 처리할 수 있지만 1회 처리에 소요되는 시간이 길다
- 데이터가 쌓이고 배치 작업을 기다리는 동안 데이터를 파악할 수 없음 → 서빙 레이어를 통해 배치 처리 결과물 조회 가능 → 스피드 레이어에서 실시간으로 조회 가능 (배치 뷰 업데이트 전까지) → 두 가지 뷰를 조합하여 조회
- 과거의 데이터를 장기 저장소에 축적하고 여러 번 다시 집계 가능
람다 아키텍처의 문제점
- 데이터 자체를 병합하거나 각각 쿼리를 하는 등의 방식으로 결과물을 사용
- 데이터가 너무 크면 병합도 큰 리소스
- 독립된 두 버전의 파이프라인을 모두 개발/운영해야 하기 때문에 효율이 떨어짐
- 두 파이프라인에서 나온 결과를 병합하거나 양쪽에 쿼리를 해야 했기에 비효율적
⇒ 카파 아키텍처의 등장으로 이어짐
Kappa Architecture
- 카프카 개발자 Jay Kreps가 제안: 참고자료
- 스피드 레이어만 존재
→ 배치 레이어와 서빙 레이어 제거 - 스트림 처리로만 데이터 파이프라인 단순화
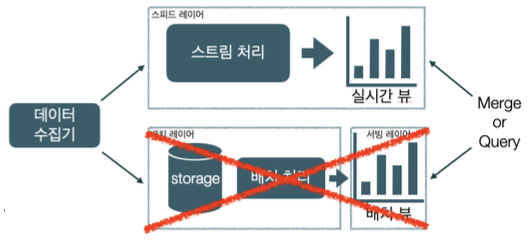
→ 두 처리 방식의 결과물을 병합하기 위한 리소스 절약
→ 단일 파이프라인과 단일 뷰로 개발/운영 효율화
왜 이제서야 등장했나?
- 발전된 스트림 처리 엔진
- 초기 람다 아키텍처가 소개될 당시 스트림처리 엔진의 신뢰성이 낮았음
- 지금은 at-leat-once뿐만 아니라 exactly-once까지 지원
- at-most-once: 최대 한번, 메시지 유실 가능성 있음
- at-least-once: 최소 한번, 메시지 유실 가능성 없음, 중복 가능성 있음
- exactly-once: 전달 보장, 유실 가능성 없음, 중복 가능성 없음
- 심하게 과장된 스트리밍의 한계
- 재현 가능한(replayable) 메시지 브로커: Kafka
- 메시지 브로커의 데이터 보관기간이 충분히 길다면 과거의 데이터를 다시 스트림 파이프라인에 흘려서 재처리 가능해짐
- 무엇보다 실시간성이 중요해짐
→ 되니까.. 보다는 필요하니까! (ex: 우버 매칭)
카파 아키텍처의 문제점
- 높은 부하
- 재처리 시에는 수 배 ~ 수 십 배의 리소스 필요
- 실시간성에 완벽하게 의존하기 때문에 Computation-intensive한 작업이 어려움
- ML/DL 등 계산량이 많이 필요한 경우 계산 속도가 이를 따라가지 못함
⇒ 분산처리, Scale-Out, Cloud Computing
3. 데이터 엔지니어링 on Cloud
“넷플릭스 서비스 역시 빠른 속도로 진화함에 따라 많은 리소스를 차지하는 새로운 기능이 다수 도입되고 데이터 사용량도 지속적으로 증가해 왔습니다. 넷플릭스의 기존 데이터 센터가 이러한 급성장을 지원하기란 매우 어려웠지요. 그러나 클라우드의 탄력성 덕분에 이제 수천 개의 가상 서버와 페타바이트급(PB) 저장 용량을 불과 몇 분 내에 추가할 수 있게 되었습니다. 이에 전 세계에 분산된 AWS 클라우드 지역을 기반으로 글로벌 인프라를 유연하게 활용하고 그 역량을 확대할 수 있게 되었으며, 언제 어디서나 더 편안하고 즐겁게 콘텐츠를 스트리밍할 수 있는 환경이 조성되었지요.”
유리 이즈라일예브스키, 넷플릭스 클라우드&플랫폼 엔지니어링 부사장
Why Cloud?
- 뛰어난 확장성
- 늘어나는 데이터를 손쉽게 대응 (컴퓨팅 자원, 스토리지, 신규 기능)
- 효율적인 자원 활용
- 뛰어난 비용 효율성
- 빠른 리소스 구축
- 현대 데이터 엔지니어링과 클라우드는 뗄 수 없는 사이
- Public Cloud든 on-prem이든
데이터를 위한 수많은 서비스
- 개발/구축할 인력 대신 만들어진 서비스를 이용
- 일부 대체 불가능한 서비스들(Bigquery, S3, …)
- 법적 제도적 이슈 (클라우드 및 개인정보 관련 인증과 제도)
- 손쉽게 사용 가능한 ML/DL 솔루션
