DataBase System
Database Management System
정의: 데이터베이스를 관리하고 운영하는 소프트웨어.
DBMS의 특징
⚫ 상호연관 되어 있는 데이터들에 접근할 수 있는 프로그램들의 집합이다.
⚫ 편리하고 효율적으로 사용할 수 있는 환경을 제공해준다.
⚫ 데이터베이스는 매우 클 수 있다. (많은 사용자들을 저장해야하기 때문에.)
일상속의 DataBase 응용분야
⚫ 은행업, 항공사, 대학교, 판매, 제조업, 인사 관리등
대학교에서의 DataBase System
⚫ 예시1) 새로운 학생, 교수, 강좌 추가하기.
⚫ 예시2) 강의에 학생들 추가 및 수업 제작.
⚫ 예시3) 학생들에게 성적을 부여하고 GPA 계산
초기에는, 이러한 시스템들은 ‘파일시스템’위에 구축되었다.
파일시스템 (FileSystem)
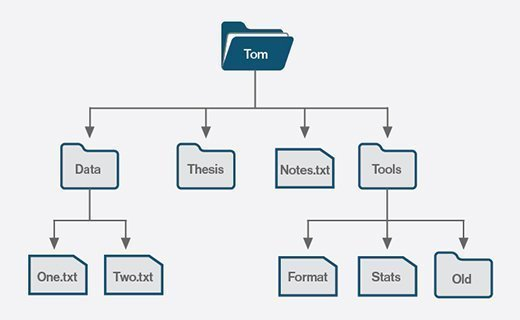
정의: 말 그대로 파일들을 이용하여 System을 구축한 것.
파일시스템의 단점
1. 데이터 중복과 불일치 - 각 파일에 Data가 중복해서 발생할 수 있음.
2. 데이터 접근의 어려움 - 새로운 작업을 수행하기 위해 새로운 Program개발이 요구될 수 있음.
3. 데이터 고립 - 데이터가 여러 파일들과 다양한 형식으로 저장되어 있어서, 가져오기 번거로움.
4. 무결성 문제 - 새로운 조건을 추가하거나 기존 조건들을 변경하는 것이 어렵다.
5. 원자성(Atomicity) 문제 - 업데이트 중 장애가 발생하면, 데이터베이스 중 일부만 업데이트된 불일치 상태가 될 수 있음.
6. 다중 사용자 동시 접근 - 성능 향상을 위해 동시성 제어가 필요할 수 있음. - 통제되지 않는 동시성 제어는 데이터 불일치성을 야기할 수 있음.
7. 보안문제 - 일부 데이터만 특정 사용자에게 보여주는 것이 어려움.
스키마와 인스턴스 (Schemas and Instances)
스키마 (Schema)
정의: 스키마는 데이터베이스의 구조를 정의하는 틀.
테이블, 열, 데이터 타입, 제약 조건 등을 포함해 데이터베이스의 전체적인 설계도 역할을 수행한다.
특징
◼일반적으로 데이터베이스를 처음 설계할 때 설정되며, 잘 변경되지 않는다.
◼데이터베이스에 저장될 데이터의 형태와 구조를 정의한다.
◼데이터베이스의 메타데이터라고도 할 수 있다.
예시
학교 데이터베이스 스키마에서는 학생 테이블에 이름, 학번, 학과 열이 있다고 정의할 수 있다.
인스턴스 (Instance)
정의: 인스턴스는 특정 시점에 데이터베이스에 저장된 데이터의 실제 상태.
특징
◼데이터는 시간에 따라 변동될 수 있으므로 인스턴스는 시점마다 달라질 수 있다.
◼특정 시점에서의 데이터 상태를 나타내며, 데이터가 추가되거나 수정되면 인스턴스도 변한다.
예시
학생 데이터베이스 인스턴스는 학생 테이블에 현재 등록된 모든 학생의 실제 데이터를 포함한다. 오늘과 내일의 인스턴스는 학생들의 등록 현황에 따라 변경될 수 있다.
스키마(Schema)의 종류
⚫ 개념적 스키마 (Conceptual Schema)
◼ 데이터베이스의 전체 구조와 관계를 정의.
◼ 사용자나 애플리케이션이 보는 데이터의 통합된 개념적 구조 설계.
⚫ 논리적 스키마 (Logical Schema)
◼ 데이터베이스의 전체 구조. (= 설계도)
◼ 어떠한 데이터가 들어갈지 설계하는 단계.
⚫ 물리적 스키마 (Physical Schema)
◼ 데이터베이스가 실제로 어떻게 저장되는지에 대한 물리적 구조.
이러한 스키마들은 서로 독립적이며, 물리적 스키마를 변경하여도 논리적 스키마에 영향을 미치지 않는 것을 ‘물리적 데이터 독립성 (Physical data Independence)’라고 한다.
데이터 모델 (Data Model)
정의: 데이터를 설명하기 위한 도구들의 모음으로서, 데이터 관계, 데이터의 의미, 데이터 제약조건들을 정의하는데 사용함.
데이터 모델의 종류
1. 관계형 모델 (Realational Model)
➢ 데이터를 테이블 형식으로 구성하여 행(row)과 열(column)로 관리.
➢ SQL을 통해 데이터를 처리하며, 가장 널리 사용되는 데이터 모델.
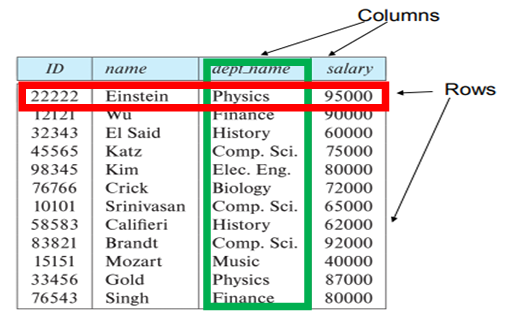
➢ 행(Row)는 Tuple 또는 Record라고도 부른다.
➢ 열(Column)은 Field 또는 Attribute라고도 부른다.
2. 엔티티 – 관계 모델 (Entity – Relationship Model, ER모델)
➢ 데이터베이스 설계를 위해 주로 사용되며, 엔티티(객체)와 그들 간의 관계를 시각적으로 표현함.
➢ ER 다이어그램을 사용하여 데이터 구조를 쉽게 이해할 수 있게 해줌.
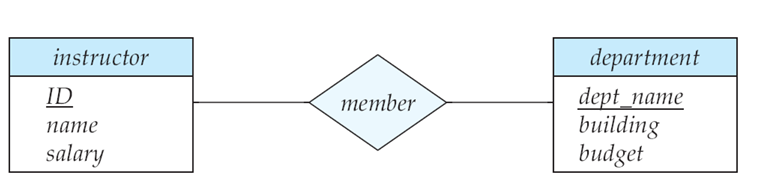
3. 객체 기반 데이터 모델 (Object-Based Model)
➢ 객체 지향 모델: 객체와 클래스를 사용하여 데이터를 표현하는 모델.
➢ 객체 – 관계형 모델: 관계형 모델과 객체 지향 모델의 특징들을 결합하여 설계된
데이터베이스 (Relation Model + Object Oriented Model)
4. 반구조화 데이터 모델 (Semi-structured Data Model)
➢ 마크업 언어를 사용하여 데이터를 표현. ( 예: XML )
XML ( Extensible Markup Language )
• ‘W3C(월드 와이드 웹 컨소시엄)’에 의해 정의된 언어이다.
• 원래는 문서 마크업 언어로 설계되었으며, 데이터베이스 언어가 아니었다.
• 새로운 태그를 정의하고 중첩된 태그 구조를 만들 수 있는 기능 덕분에 데이터 교환의 훌륭한 수단으로 자리 잡게 되었다.
• XML은 차세대 데이터 교환 형식의 기본이 되었다.
• XML 문서와 데이터를 파싱, 탐색, 질의할 수 있는 다양한 도구들이 널리 사용되고 있다.
특징 및 장점
1. 유연한 구조: 사용자가 필요한 태그를 직접 정의할 수 있어, 다양한 형태의 데이터를 표현하고 교환하는 데 적합하다.
2. 데이터 교환 표준: 플랫폼에 상관없이 데이터를 주고받을 수 있어, 웹 서비스와 같은 시스템 통합에 광범위하게 사용된다.
3. 도구의 풍부함: XML을 파싱하거나 탐색하는 도구들이 많이 개발되어 있어 데이터를 다루는 작업이 용이하다.
기타 오래된 모델들
1. 계층형 모델(Hierarchical Model) : 데이터를 트리 구조로 저장하여 데이터를 표현.
2. 네트워크 모델(Network Model) : 데이터를 그래프 형태로 표현하여 관계를 표현.
DDL (Data Definition Language - 데이터 정의 언어)

⚫ DDL은 데이터베이스 스키마를 정의하기 위한 명세 표기법이다.
⚫ DDL 컴파일러는 데이터 딕셔너리 (Data Dictionary)에 저장되는 테이블 템플릿 세트를 생성.
데이터 딕셔너리 (Data Dictionary)
1. 데이터베이스 스키마 정의
➢ 테이블, 열, 데이터 타입, 인덱스, 뷰, 제약 조건 등의 구조적인 정보를 저장한다.
2. 무결성 제약 조건
➢ 예를 들어, 기본 키(Primary Key), 외래 키(Foreign Key), 고유 제약(Unique Constraint)
등의 규칙을 정의하고 저장한다.
➢ 데이터의 일관성과 정확성을 유지하기 위한 제약 조건이 포함된다.
3. 권한과 접근 제어
➢ 데이터베이스 내에서 누가 어떤 데이터에 접근할 수 있는지에 대한 권한 정보를
관리한다.
➢ 사용자와 역할(role)에 대한 정보, 그리고 각 사용자에게 허용된 권한이 포함된다.
4. 데이터 관계
➢ 테이블 간의 관계(예: 일대다, 다대다)를 정의하여 데이터 간의 연결성을 설명한다.
5. 기타 메타데이터
➢ 트리거(Trigger), 저장 프로시저(Stored Procedure), 기본값(Default Value) 등의 정보도 포함할 수 있다.
데이터 딕셔너리의 중요성
• 데이터베이스 관리: 데이터베이스의 구조와 규칙을 명확하게 정의하고 저장하여 관리를 용이하게 해준다.
• 데이터 무결성 유지: 정의된 제약 조건을 통해 데이터의 무결성을 유지할 수 있게 해준다.
• 보안 강화: 사용자 권한을 명확하게 관리함으로써 보안을 강화할 수 있다.
• 문서화 및 유지 보수: 데이터베이스 구조를 문서화하여 시스템의 이해도를 높이고, 유지 보수를 쉽게 할 수 있도록 돕는다.
DML (Data Manipulation Language – 데이터 조작 언어)
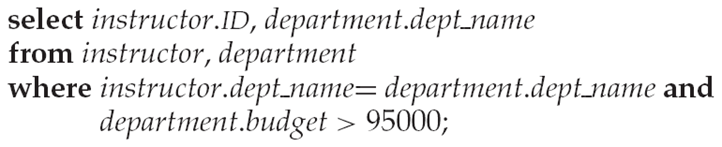
⚫ DML은 데이터를 접근하고 조작하기 위한 언어이다.
⚫ DML은 ‘쿼리 언어(Query Language)’라고도 불린다.
⚫ 또한, DML은 ‘선언형 언어(Declarative)언어’로서, 데이터를 어떻게 가져오는지 명시하지 않고 어떤 데이터를 가져올지를 지정한다.
SQL (Structured Query Language – 구조적 질의 언어)
⚫ SQL은 데이터베이스 관리 시스템(DBMS)에서 데이터를 정의하고 관리하기 위해 설계된 특수 목적의 프로그래밍 언어이다.
⚫ 상업적으로 가장 널리 사용되는 언어이다.
⚫ 응용 프로그램은 임베디드 SQL이나 ODBC(JDBC)와 같은 인터페이스를 통해 SQL쿼리를 데이터베이스에 저장할 수 있다.
DataBase Design
➢ 개념적 설계 (Conceptual Design)
1. 사용자의 요구사항을 바탕으로 데이터베이스의 전체적인 구조를 개념적으로 정의.
2. 주로 ER 다이어그램을 사용하여 엔티티, 속성, 관계를 시각적으로 표현함.
➢ 논리적 설계 (Logical Design)
1. 개념적 설계를 바탕으로 데이터베이스 관리 시스템(DBMS)에 맞는 논리적 모델을 구축.
2. 주로 관계형 모델을 사용하여 테이블, 열, 관계를 정의.
➢ 물리적 설계 (Physical Design)
1. 논리적 설계를 실제 데이터베이스 시스템에 구현.
스토리지 매니저 (Storage Manager)
스토리지 매니저는 데이터베이스 시스템의 저수준 데이터와 응용 프로그램 및 쿼리 간의 인터페이스 역할을 하는 프로그램 모듈이다.
스토리지 매니저는 데이터베이스의 저장 및 접근 효율성을 높이는 데 중요한 역할을 한다.
주요 역할 및 책임
1. 효율적인 데이터 저장, 검색 및 업데이트
➢ 데이터를 효율적으로 저장하고 필요할 때 빠르게 검색하며,
데이터를 수정할 때도 신속하게 반영되도록 한다.
2. 운영 체제의 파일 관리자와의 상호작용
➢ 운영 체제의 파일 시스템과 협력하여 데이터의 물리적 저장 및 관리를 수행한다.
1. 스토리지 접근 (Storage Access)
➢ 데이터를 빠르고 효율적으로 접근할 수 있도록 접근 방식(예: 순차 접근, 랜덤 접근 등)을 관리함.
2. 파일 조직 (File Organization)
➢ 데이터를 저장할 때 파일의 구조를 어떻게 구성할 것인지 결정해준다. 예를 들어, 데이터를 연속적으로 저장할지, 블록 단위로 나눌지 등을 결정한다.
3. 인덱싱 및 해싱 (Indexing and Hashing)
➢ 인덱스나 해시 테이블을 사용하여 데이터를 빠르게 검색할 수 있도록 한다.
➢ 인덱싱은 검색 속도를 높이는 데 중요한 역할을 하며, 해싱은 데이터의 분산 저장을 통해 효율성을 높여준다.
쿼리 프로세서(Query Processor)
정의: 쿼리 프로세서는 데이터베이스 시스템에서 사용자가 입력한 쿼리를 처리하고 실행하는 역할을
담당하며, 쿼리 처리 과정은 크게 세 단계로 나뉘게 된다.
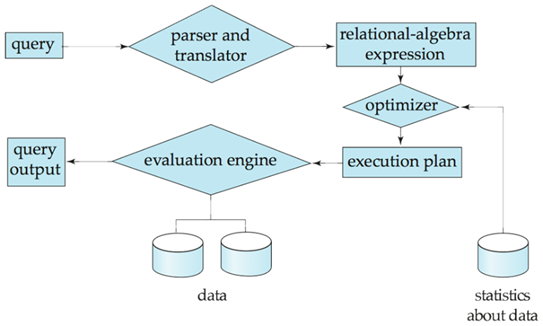
1. 파싱 및 번역 (Parsing and Translation)
➢ 쿼리 프로세서는 입력된 쿼리를 분석하여 구문 오류를 체크하고, 이를
관계 대수 표현(Relational-Algebra Expression)으로 변환한다.
➢ 파서(Parser)와 번역기(Translator)가 이 과정을 수행하며, 쿼리의 논리적 구조를 파악하고 시스템이 이해할 수 있는 형태로 변환한다.
2. 최적화 (Optimization)
➢ 변환된 관계 대수 표현을 최적화하여 효율적인 실행 계획을 수립한다.
➢ 최적화기는 여러 가지 실행 계획 중에서 비용이 가장 적게 드는 계획을 선택한다. 이는
데이터 통계와 시스템의 상태 등을 바탕으로 결정되게 된다.
3. 평가 (Evaluation)
➢ 최적화된 실행 계획을 실제로 실행하여 결과를 생성한다.
➢ 평가 엔진(Evaluation Engine)이 실행 계획을 따라 데이터를 처리하고, 최종적으로 쿼리의
결과를 사용자에게 제공한다.
쿼리 처리 과정의 흐름
• 사용자가 쿼리를 입력하면 파서와 번역기가 이를 관계 대수 표현으로 변환하고, 이후
최적화기가 최적의 실행 계획을 생성한다. 마지막으로, 평가 엔진이 이 실행 계획에 따라
데이터를 처리하여 쿼리 결과를 반환한다.
쿼리(Query)의 대안적 평가 방법
1. 동등한 표현식 (Equivalent Expressions)
➢ 동일한 결과를 제공하는 여러 형태의 쿼리 표현이 있을 수 있는데, 이러한 동등한 표현식은 쿼리의 성능을 개선할 수 있는 가능성을 제공한다.
2. 각 작업에 대한 다양한 알고리즘 (Different Algorithms for Each Operation)
➢ 쿼리의 각 작업(예: 조인, 정렬, 집합 연산)에 대해 다양한 알고리즘이 존재한다. 예를 들어,
조인을 수행할 때는 중첩 루프 조인, 해시 조인, 정렬 병합 조인 등 여러 알고리즘을
사용할 수 있기에, 이러한 알고리즘들은 상황에 따라 성능 차이가 크게 날 수 있다.
3. 작업 비용 추정 (Estimation of the Cost of Operations)
➢ 각 쿼리 연산의 비용을 추정하여, 가장 적은 비용으로 수행할 수 있는 계획을 선택한다.
비용은 주로 CPU 사용량, I/O 접근 횟수, 메모리 사용량 등을 기반으로 계산되게 된다.
4. 평가 방법 간의 비용 차이 (Cost Difference)
➢ 쿼리를 잘못 평가할 경우, 최적화된 방법에 비해 매우 높은 비용이 발생할 수 있다.
5. 통계 정보 의존성 (Dependency on Statistical Information)
➢ 쿼리 최적화는 데이터베이스가 유지하는 관계에 대한 통계 정보에 크게 의존한다. 이 정보에는 테이블 크기, 인덱스의 유용성, 데이터 분포 등이 포함되게 된다.
➢ 중간 결과에 대한 통계치를 추정하여 복잡한 표현식의 총 비용을 계산하는 데 필요하다.
Transaction (트랜잭션)
• 트랜잭션은 데이터베이스에서 수행되는 하나의 논리적 작업 단위로, 데이터베이스의 일관성을 유지하는 것이 핵심이다.
• 트랜잭션은 데이터베이스의 상태를 변경할 수 있으며, 모든 작업이 성공적으로 완료되거나 모두 취소되어야 한다. 이를 ‘원자성(Atomicity)’이라 부른다.
Transaction Manager (트랜잭션 관리자)
• 트랜잭션 관리자는 데이터베이스 내에서 트랜잭션을 조정하고 관리한다.
• 주요 역할은 트랜잭션이 성공적으로 완료될 때까지 모든 변경 사항을 추적하며, 실패 시에는 변경 사항을 롤백 하여 데이터베이스를 원래 상태로 되돌리는 역할을 수행한다.
Concurrency-Control Manager (동시성 제어 관리자)
• 동시성 제어 관리자는 여러 트랜잭션이 동시에 실행될 때 데이터의 일관성을 유지하기 위해 관리해준다.
• 트랜잭션 간의 충돌을 방지하고, 데이터의 무결성을 보장하기 위한 다양한 동시성 제어 기법 (예: 잠금, 타임스탬프)을 사용한다.
데이터베이스 시스템의 역사
- 1950 ~ 1960년 : 자기 테이프를 이용한 저장방식. (펀치를 이용하여 입력함)
- 1960 ~ 1970년 : 하드디스크를 이용한 데이터의 접근이 가능해짐. Edgar F.Codd가 관계형
데이터 모델 (ER Model)을 정의함. 또한, IBM에서는 R언어를 발표. - 1980년 : ORACLE이 등장하고, SQL이 산업의 표준이 되었음.
- 1990년 : 대규모로 확장되었으며, 전자상거래가 발달하였음.
- 2000년 : XML 및 XQuery가 표준화 되었고, 데이터베이스의 관리가 자동화되었다.
