
원문: https://www.toptal.com/react/react-seo-best-practices
React는 declarative, modular, and closs-platform형의 interactive UI를 생성하기 위해 개발되었다. 현재, 성능좋은 프론트엔드 애플리케이션을 작성하는데 가장 인기있는 JavaScript framworks. 초기에 SPAs(Single Page Applications)를 위해 개발되었지만, 현재는 본격적인 웹사이트와 모바일 애플리케이션을 생성하는데 사용하고 있다. 하지만 리액트가 있기를 얻은 요소와 특징으로 인해 SEO에 많은 문제가 있다.
만약 기존의 웹 개발을 React로 옮긴 많은 경험이 있다면, HTTL, CSS 코드가 JavaScript로 많은 양이 이동함을 알아차릴 것이다. 이것은 React가 UI 요소를 바로 생성하거나 업데이트하는 것을 권장하지 않고, UI의 상태를 묘사하는 것을 추천하기 때문이다. React는 그렇게 가장 효율적인 방법으로 DOM을 상태와 match하며 업데이트한다.
결과적으로, 모든 UI 혹은 DOM의 문제는 React의 엔진을 통해서 진행되어야한다. 개발자들에게는 편리하지만, 이것은 사용자의 load time을 늘리고, 검색엔진이 컨텐츠를 찾고 index하는 일을 늘리며, React 웹페이지의 잠재적인 이슈를 야기할 수 있다.
이 기사에서, SEO 성능이 좋은 React 앱과 웹사이트를 만드는 동안 마주할 문제를 다루고 이를 극복하기 위한 몇가지 전략을 설명할 것이다.
How Google Crawls and Indexes Webpages
Google이 전체 온라인 검색의 90% 이상을 차지하고 있기 대문에, 탐색 및 인덱싱 과정을 더 자세히 살펴볼 가치가 있다.
Google의 문서에서 가져온 이 snapshot이 도움이 될 수 있다.(Note: 단순한 block diagram, 실제는 더 정교함)
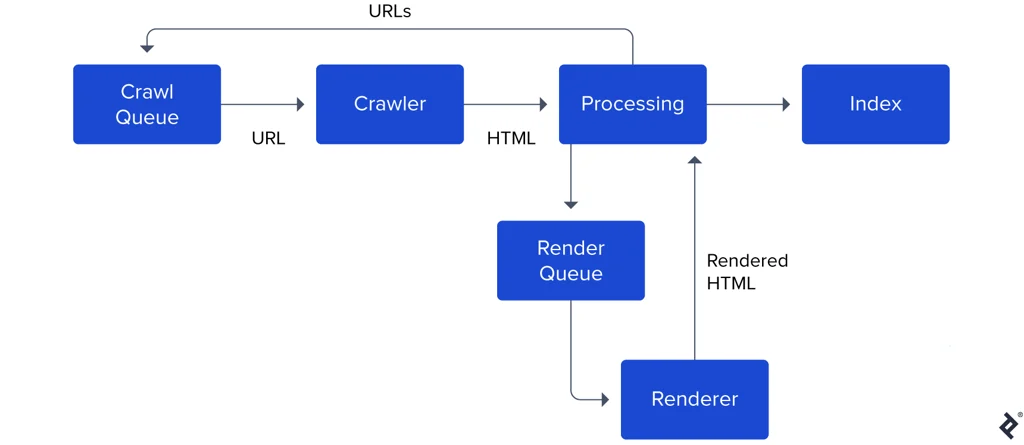
Google Indexing Steps
- Googlebot이 향후 크롤링과 인덱스에 필요할 모든 URL을 crawl queue에 maintain.
- crawler가 비활성화 상태(idle)일 때, 큐에서 다음 URL을 고르고, 요청을 만들고, HTML을 가져온다.
- HTML 파싱 후에, Googlebot은 content를 렌더링하기 위해 JavaScript의 fetch와 execute이 필요한지 결정한다. 만약 필요하다면, 해당 URL을 render queue에 추가한다.
- 나중에, renderer는 페이지를 렌더링하기 위해 JavaScript를 가져와서 실행하고, processing unit으로 렌더링된 HTML을 보낸다.
- processing unit은 웹페이지에서 언근된 모든 URL의 a 태그를 추출하고 다시 crawl queue에 추가한다.
- 해당 content이 Google의 index에 추가된다.
HTML을 파싱하는 Processing stage와 JavaScript를 execute하는 Renderer stage 사이에는 분명한 구분이 있음을 알아야 한다. 이 차이는 Googlebots이 130조 이상의 웹페이지를 살펴봐야한다는 점에서 JavaScript를 실행하는데 큰 비용이 들기 때문이다. 따라서 Googlebot이 웹페이지를 crawl할 때, HTML을 즉각적으로 파싱하고 JavaScript를 나중에 실행하기 위해 queues에 올린다. Google의 문서에는 페이지가 몇 초 동안 render queue에서 머무른다고 언급한다.
crawl budget 개념도 언급할 가치가 있다. Google의 crawling은 Googlebot instance의 bandwidth(네트워크 대역폭), 시간, 가용성에 의해 제한된다. 각 웹사이트를 index하기 위해 특정 예산이나 자원을 할당한다. 만약 수천개의 페이지를 담은 content-heavy 웹페이지(ex. 전자상거래 웹사이트)를 만든다면, 그리고 이 페이지가 내용을 render하기 위해 수많은 JavaScript를 사용한다면, Google은 그 많은 컨텐츠만큼을 읽지 않을 수도 있다.
Note: crawl budget을 위한 Google의 가이드라인이 있다.
Why React SEO Remains Challenging
이 Googlebot의 crawling과 indexing의 짧은 개요는 표면을 긁을 뿐이다. 소프트웨어 엔지니어는 React 페이지의 crawl과 index를 시도하는 검색엔진이 마주할 잠재적인 문제들을 식별해야한다.
여기 React의 SEO를 도전적으로 만드는 것과 개발자들이 어떻게 이 도전과제들을 극복할 수 있을지를 다룬 자세한 관점들이 있다.
Empty First-pass Content
우리는 React 어플리케이션이 JavaScript에 크게 의존하고 검색엔진에 문제가 자주 문제가 생긴다는 것을 안다. 이것은 React가 기본적으로 app shell model을 사용하기 때문이다. 초기 HTML은 의미있는 content를 포함하지 않으며, 유저 혹은 bot은 페이지의 실제 content를 보기 위해서 JavaScript를 실행해야 한다.
이 접근은 Googlebot이 첫번째 pass 동안 빈 페이지를 감지한다는 것을 의미한다. 페이지가 렌더링될 때만 구글이 content를 볼 수 있다. 수천 페이지를 처리할 대, 이것은 내용의 index를 지연시킨다.
Load Time and User Experience
JavaScript를 가져오고, 파싱하고, 실행하는 것은 시간이 걸린다. JavaScript는 또한 content를 가져오기 위해 네트워크를 호출해야할 수 있고 사용자는 요청한 정보를 볼 수 있기 전에 잠시 기다려야할 수도 있다.
Google은 순위 기준에 사용되는, 사용자 경험과 관련된 core web vitals 세트를 제시했다. load time이 길어질수록 Gogle이 사이트의 순위를 낮게 매기며 사용자 경험 점수에 영향을 미칠 수 있다.
Page Metadata
meta 태그는 Google과 social media 웹사이트에서 페이지에 대한 제목, 썸네일(thumbnail), 설명에 표시할 수 있기 때문에 유용하다. 그러나 이러한 정보를 얻기 위해 웹사이트는 가져온 웹 사사이트의 head 태그에 의존하지만, 그들은 taget 페이지에 대해 JavaScript를 사용하지는 않는다.
React는 클라이언트 측에서 meta 태그를 포함한 모든 content를 렌더한다. app shall은 웹 사이트/애플리케이션의 전체에 대해 같기 때문에, 각각의 패이지와 애플리케이션에 대한 metadata 조정하기엔 어려움이 있다.
Sitemap
사이트맵은 사이트의 페이지, 동영상, 다른 파일들과 그들의 관계를 제공하는 파일이다. Google과 같은 검색 엔진은 웹사이트를 지능적으로 crawl하기 위해 이 파일을 읽는다.
React는 사이트맵을 생성하는 내장된 방법이 없다. 만약 라우팅을 위해 React Router와 같은 것을 사용한다면, 노력을 들여야하지만 사이트맵을 생성하는 도구를 찾을 수 있다.
None-React SEO Considerations
이러한 고려사항들은 일반적으로 좋은 SEO 수행을 설정하는 것과 관련되어 있다.
- 페이지에 대해 사용자와 검색 엔진이 무엇을 기대하는가에 관한 감각을 제공하는 최적의 URL 구조를 갖는다.
- 검색 봇이 웹페이지에서 페이지를 crawl하는 방법을 이해하는 것을 돕기 위한 최적의 robots.txt 파일을 최적화한다.
- CSS, JS, fonts 등 정적 자산을 제공하기 위해 CDN을 사용하고 load time을 줄이기 위한 응답형 이미지를 사용한다.
우리는 SSR(Server-side Rendering)이나 pre-rendering을 사용함으로써 이러한 문제를 다룰 수 있다. 아래에서는 이러한 접근을 검토한다.
Enter Isomorphic React
isomorphic의 사전적 정의는 "corresponding or similar in form"이다.
React 측에서, 이것은 서버가 클라이언트와 유사한 형태를 가지고 있음을 의미한다. 다른말로, 우리는 동일한 React 컴포넌트를 서버와 클라이언트에서 재사용할 수 있다.
이 isomorphic 접근방식은 서버가 React 앱을 렌더하고 유저와 검색 엔진에게 렌더링된 버전을 제공할 수 있게하여 JavaScript가 background에서 로딩되고 실행되는 동안 content를 바로 볼 수 있다.
Next.js와 Gasby 같은 프레임워크는 이 접근을 대중화했다. 우리는 isomorphic 컴포넌트가 기존의 React 컴포넌트와 상당히 다르다는 점을 알아야 한다. 예를 들어, 그들은 클라이언트 대신 서버에서 실행되는 코드를 포함할 수 있다. 그들은 심지어 (비록 서버코드는 클라이언트에게 보내기 전에 stripped out되지만) API secret도 포함할 수 있다.
이러한 프레임워크는 많은 복잡성을 추상화할 뿐만 아니라 코드를 작성하는 다양한 의견을 제시한다. 우리는 다른 섹션에서 performance trade-off를 알아보겠다.
trade-off: 두 가지 이상의 요소 또는 가치 중 하나를 선택하고 다른 하나를 포기하는 것
렌더링 방법과 웹사이트 성능의 관계를 파악하기 위한 matrix 분석을 할 것이다. 그러나 우선, 웹사이트 성능 측정을 위한 기본 사항부터 알아보자.
Metrics for Website Performance
웹사이트의 순위를 매기는데 검색엔진이 사용하는 요소 몇가지를 알아보자.
유저의 query에 빠르고 정확하게 답하는 것과 떨어져서, Google은 좋은 웹사이트는 다음과 같은 속성을 가져야한다고 믿는다:
- 사용자는 너무 많은 대기 시간 없이 content에 접근가능해야한다.
- 사용자의 행동에 대해 쉽게 상호작용해야한다.
- 빠르게 로딩되어야 한다.
- 유저의 데이터나 배터리를 소진하는 것을 방지하기 위해서 불필요한 데이터를 가져오거나 비싼 코드를 실행하지 않아야 한다.
이러한 특징들은 다음과 같은 지표(matrix)와 관련이 있다:
- Time to First Byte(TTFB): 링크를 클릭하고 content가 오는 첫번째 비트 사이에 걸리는 시간
- Largest Contentful Paint(LCP):요청한 기사가 보여지기 까지의 시간. Google은 2.5초 미만으로 유지하길 권장
- Time to Interactive(TTI): 페이지가 interactive해지는 시간(스크롤, 클릭 등을 실행가능한 시점)
-Bundle Size: 페이지가 완전히 보여지고 상호작용하게 되기 전까지 다운로드된 총 바이트 수 및 코드 실행 양
우리는 redering path가 각각 영향을 미치는 방법을 더 잘 이해하기 위해 이러한 지표를 다시 살펴보겠습니다.
다음은, React 개발자들이 이용할 수 있는 다양한 render path를 알아보겠습니다.
Render Path
우리는 브라우저에서 혹은 서버에서 React 애플리케이션을 렌더하고 다양한 결과를 생산할 수 있습니다.
클라이언트 측, 서버 측 렌더링 앱 사이에는 routing과 code splitting 두가지 기능이 크게 바뀝니다. 아래에서 더 자세히 살펴보겠습니다.
Client-side Rendering(CSR)
Client-side rendering은 React SPA의 기본 render path입니다. 서버는 content를 포함하지 않는 shell app을 제공합니다. 브라우저가 JavaScript가 포함된 source를 다운로드, 파싱, 실행하면, HTML의 content가 채워지거나 렌더링됩니다.
브라우저 히스토리를 관리함으로써 클라이언트 앱이 routing 기능을 핸들링합니다. 이것은 어느 route가 요청되었는지에 관계없이 같은 HTML을 제공함을 의미하고, 클라이언트는 렌더링 후 뷰 상태를 업데이트합니다.
Code splitting은 비교적 간단합니다. 동적 import 혹은 React.lazy를 사용하여 코드를 분할할 수 있습니다. route 혹은 유저 액션을 기반으로 필요한 종석성만 로드되도록 분할합니다.
만약 블로그 제목이나 제품 설명과 같이 서버에서 content를 렌더하기 위해서 데이터를 가져와야하는 페이지일 경우, 관련 컴포넌트가 마운트되고 렌더링되는 경우에만 가져올 수 있습니다.
웹 사이트가 추가 데이터를 가져오는 동안 "Loading data" 기호 혹은 indicator를 볼 수 있습니다.
Client-side Rendering With Bootstrapped Data(CSRB)
DOM이 렌더링된 후에 데이터를 가져오는 대신, 제공된 HTML 안에서 서버가 관련된 bootstrapped된 데이터를 보내는 CSR 시나리오를 고려해보자.
bootstrapped Data: HTML에 포함된 데이터
우리는 이와 같은 node를 포함할 수 있다:
<script id="data" type="application/json">
{"title": "My blog title", "comments":["comment 1","comment 2"]}
</script>그리고 컴포넌트가 마운트될 때 파싱된다:
var data = JSON.parse(document.getElementById('data').innerHTML);우리는 round trip 과정을 절약했습니다. 우리는 trade-off를 살펴보겠습니다.
Round trip to the server: 클라이언트와 서버 간에 데이터를 요청하고 응답을 받는 과정
Server-side Rendering to Static Content (SSRS)
우리가 HTML을 동적으로 생성할 필요학 있는 경우의 상황을 상상해보자.
on the fly: 어떤 작업이나 처리가 사전 계획 없이 즉각적으로 이루어진다
우리가 온라인 계산기를 개발 중이고 /calculate/34+15의 쿼리를 보내면, 쿼리를 처리하고, 결과를 평가하고, 생성된 HTML에 응답을 해줘야한다.
생성된 HTML은 꽤 구조가 간단하며 생성된 HTML을 제공하고 나서 DOM을 관리하고 조작할 필요가 없다.
그래서 우리는 단지 HTML과 CSS content를 제공만 한다. 이를 달성하기 위해 renderToStaticMarkup 메소드를 사용할 수 있다.
CDN 캐싱을 이용하여 더 빠른 응답을 제공할 수 있으며, 각각의 결과에 따라 HTML을 다시 계산할 필요가 없기 때문에 라우팅이 서버에서 완전히 서버에서 처리된다.CSS 파일 역시 브라우저에 의해 캐시되어 페이지 로드가 빨라질 수 있다.
Server-side Rendering With Rehydration (SSRH)
앞에서 묘사한 것과 같은 상황이지만, 이번엔 완전히 작동하는 React 애플리케이션이 필요한 상황을 생각해봅시다.
서버에서 첫번째 렌더를 수행하고, JavaScript 파일에 따라 HTML content를 다시 보낼 것입니다. React는 이 시점부터 서버에서 렌더한 마크업과 CSR 애필리케이션처럼 동작하는 애필리케이션을 rehydrate할 것입니다.
React는 이러한 수행을 내장 method로 제공합니다.
첫번째 요청은 서버에 의해서 처리되고, 이후의 렌더는 클라이언트에서 다뤄집니다. 그러므로 그런 앱은 universal React app(서버와 클라이언트 둘 다에서 렌더되는)라고 불립니다. 라우팅을 다루는 코드는 클라이언트와 서버에서 분할 또는 복제됩니다.
ReactDOMServer는 React.lazy를 지원하지 않으므로, code spliting에 어려움이 있다. 그래서 Loadable Components와 같은 라이브러리를 사용할 수 있다.
ReactDOMServer: SSR을 위한 React의 도구
React.lazy: 비동기적으로 컴포넌트를 로드
Loadable Components: SSR과 코드 분할을 함께 사용하기 쉽도록 도와주는 라이브러리
ReactDOMServer는 얕은 복사를 수행한다. 다른말로, 렌더가 포함되어 있어도, componentDidMount와 같은 life-cycle method는 호출되지않는다. 따라서 다른 방법을 사용하여 컴포넌트에게 데이터를 제공하도록 코드를 refactoring해야 한다.
이것이 NextJS와 같은 프레임워크가 나타난 이유다. SSRH에서 라우팅 및 코드 분할과 관련된 복잡성을 mask하고 개발자 경험을 돕는다. 그러나 이 접근은 페이지 성능과 관련하여 엇갈린 결과를 낳는다.
Pre-rendering to Static Content (PRS)
사용자가 요청하기 전에 웹페이지를 렌더할 수 있는 경우는 어떨까요? 이것은 build 시점이나 데이터가 변화할 때 동적으로 완료할 수 있습니다.
그리고 나서 HTML content를 CDN에 캐싱하고 사용자가 요청할 때 빠르게 제공할 수 있습니다.
Pre-rendering은 사용자 요청 전에 content를 렌더링하느 것입니다. 이 접근은 사용자 공급 데이터에 의존하지 않기 때무네 블로그나 전자 상거래 어플리케이션에 사용될 수 있습니다.
Pre-rendering With Rehydration (PRH)
우리는 사용자가 미리 HTML로 렌더링되어서 작동하는 React app을 사용하기를 원할 수도 있습니다.
첫번째 요청이 제공된 후, 애필리케이션은 표준 React 앱과 같이 작동합니다. 이것은 라우팅과 코드 분할 측면에서 SSRH와 유사합니다.
Performance Matrix
기다리던 순간에 도착했습니다. showdown의 시간입니다. 각각의 rendering path가 웹 성능 지표에 어떤 영향을 미치는지 살펴보고 위너를 결정하겠습니다.
이 지표에서, 우리는 각각의 rendering path가 performance metric에서 얼마나 잘하는지에 따라 점수를 할당합니다.
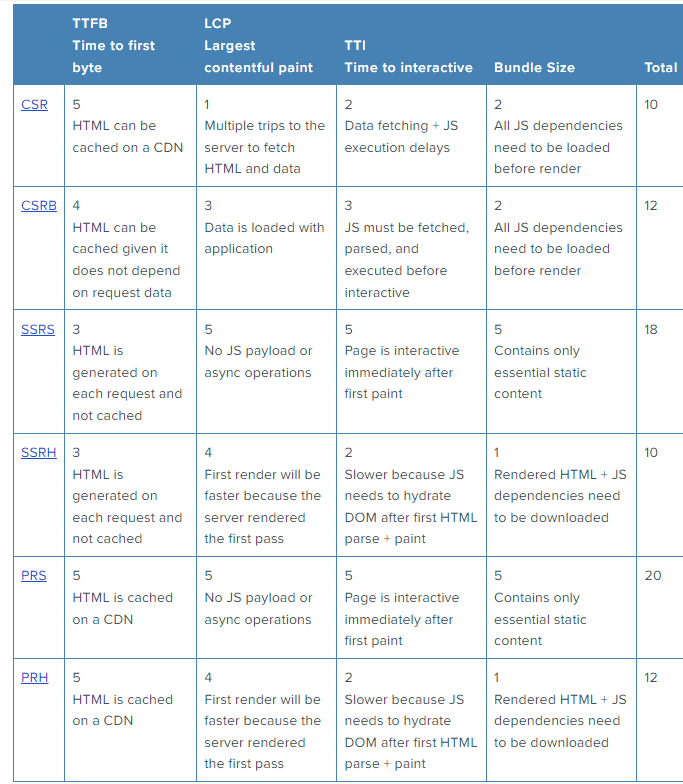
Key Takeaway
Pre-rendering to static content(PRS)은 가장 뛰어난 성능의 웹사이트를 만드는 반면, server-side rendering with hydration(SSRH)나client-side rendering(CSR)은 기대에 미치지 못하는 결과를 낼 수 있습니다.
또한 웹사이트의 다른 부분에 대해 다양한 접근방식을 적용할 수 있습니다. 이러한 성능 지표는 공개 웹페이지에 중요하게 작용되어 효율적으로 색인화될 수 있지만, 사용자가 로그인하고 개인 계정 데이터를 볼 때는 덜 중요할 수 있습니다.
각각의 render path는 데이터 처리 위치와 방법에 따라 trade-off가 있습니다. 가장 중요한 것은 엔지니어링 팀이 이러한 trade-off를 분명하게 보고 논의하며 사용자의 만족도를 극대화하는 architecture를 선택하는 것입니다.
