
전반
Gradle
빌드 자동화 시스템
빌드 설정 관리, 버전관리, 라이브러리 의존성 관리(충돌 방지)
build.gradle : Gradle 기반 빌드 스크립트, groovy / kotlin 언어 스크립트
Maven
Maven Repository
다양한 라이브러리들이 존재하는 외부 저장소
build.gradle의 dependencies는 Maven 등의 외부저장소에서 다운로드
RESTful API
Representational State Transfer
REST 아키텍처 스타일을 따르는 API
일반적으로 HTTP를 사용하여 구현
Apache Tomcat
Apache
정적 컨텐츠를 제공하는 웹 서버
Tomcat
동적 컨텐츠를 제공하는 웹 애플리케이션 서버(WAS)
서블릿 (Servlet)
Apache Tomcat
Apache + Tomcat
Spring Boot
Spring을 사용하기 위해 많고 복잡한 설정을 간편하게 해주기 위한 프레임워크
웹 개발에 자주 사용되는 설정을 디폴트로 잡아줌
애너테이션 @Annotation 사용이 많음
내장 Apache Tomcat
spring-boot-start-web
application.properties
Spring 관련 설정파일
자동 설정 값들의 수정이 간편하다는 장점
데이터베이스 설정
서버 포트 설정 등
http
상태코드
2xx 성공
4xx 클라이언트 오류
5xx 서버 오류
Payload
클라이언트가 요청할 때 GET을 제외하고 모두 페이로드를 보낼 수 있음
서버가 응답할 때 항상 페이로드를 보낼 수 있음
HTML 또는 JSON 형식
JUnit
자바 프로그래밍 언어 단위 테스트 프레임워크
개발자 테스트 방식
메서드 별로 테스트 실행 가능
테스트코드 작성 환경 제공
테스트 자동화
Lombok
코드 절약 라이브러리
거의 항상 쓰이는, 필수적인 메서드 생성자 정의 등 자동 생성
@Getter, @Setter, @NoArgsConstructor, @AllArgsConstructor, @RequiredArgsConstructor, ...
Spring MVC
MVC
구성 모듈을 Model, View, Controller로 역할을 구별하는 디자인 패턴
Model: 비즈니스 로직 + 데이터관리(DB) 수행
View: 결과를 클라이언트에게 보여줄 화면으로 구성
Spring Web MVC
Servlet API를 기반으로 구축된 웹 프레임워크
다음 원리로 동작
Servlet
자바를 사용하여 웹 페이지를 동적으로 생성하는 서버 측 프로그램 및 그 사양
서블릿 컨테이너가 있고 여러 서블릿이 존재
Front Controller 패턴
DispatcherServlet이 중앙에서 HTTP 요청을 처리함
사용자 요청 -> DispatcherServlet이 핸들러를 매핑
-> 컨트롤러에 해당 메서드 요청 -> 컨트롤러는 처리결과(모델 정보, 뷰 정보)를 Dispatcher에게 반환 -> View Resolver를 통해 뷰에 모델을 적용하고 결과를 사용자에게 반환
Jackson
JSON 데이터 구조를 처리하는 라이브러리
Object 구조 <-> String (JSON) 변환
DTO
Data Transfer Object
데이터 전송 및 이동을 위한 객체
클라이언트와 주고 받을 때 말단에서 DTO로 매핑됨
JDBC
Java Database Connectivity
애플리케이션 서버 <-> 데이터베이스
데이터베이스에 접근하고 데이터를 조작할 수 있는 API
각 DBMS 회사마다 JDBC 드라이버(jdbc 인터페이스가 구현된 라이브러리)를 배포함
개발에서는 JdbcTemplate을 활용
후반
3 Layer Architecture
서버 처리 과정을 Controller, Service, Repository 세 계층으로 분리
Controller는 API 처리 Service는 비즈니스 로직 처리를, Repository는 DB 관리 작업만을 담당
IoC, DI
왜 사용하나?
기존 방법 -> 상위 레벨의 모듈이 직접 하위 레벨의 모듈을 생성하고 관리
- 강한 의존성, 강한 결합도
변경하면 -> 느슨한 결합도, 낮은 의존성, 단일 책임 원칙, 재사용성, 확장성을 확보
IoC (제어의 역전)
Inversion of Control
소프트웨어 설계 원칙, 객체지향 프로그래밍
- 객체 생성과 주입 등을 개발자가 하지 않고 프레임워크나 외부 컨테이너가 담당
(Spring, IoC Container)
즉, 프로그램 제어를 개발자가 아니라 애플리케이션이 한다는 것을 의미
DI (의존성 주입)
Dependency Injection
IoC 원칙을 따르는 디자인 패턴 중 하나
-
주입이란
어떤 객체에서 필요로 하는 객체를 전달하는 행위
-
쉬운 의존성 주입 방법 3가지
- 생성자로 주입(객체를 파라미터로 전달), 객체의 불변성 보장
- 메서드로 주입 (setter)
- 필드에 직접 주입 (일반적으로 public 접근 지정자가 필요)
-
내가 이해한 Spring에서 의존성 주입 방법
내가 작성하고 있는 클래스에서 외부 객체가 필요하다면 여기서 객체 생성(new)을 하는 것이 아니라
클래스 바깥 어딘가에서 미리 생성(new)해 둔 객체를 생성자든, setter 메서드든 사용해서 해당 멤버 변수로 저장해서 사용하는 것이다.
Spring의 DI 패턴 구현법
Spring 프레임워크의 DI를 구현하기 위한 기술(?)은 (딱 맞는 표현이 안떠오른다)
의존성 주입 방법을 적용할 클래스를 Bean으로 등록해주어야 한다.
주입당하는 클래스, 주입하는 클래스 둘 다 해당한다.
Bean
Spring이 관리하는 객체를 Bean 이라고 명명
- Bean으로 등록된 클래스를 표시하는 아이콘
- 의존성 주입이 실행되고 있는 메서드
- http method와 url이 연결된 메서드



Spring IoC Container
Bean들을 관리하는 컨테이너
Bean 등록법
-
Bean으로 등록하려는 클래스 위에
@Component지정
또는@Controller,@RestController,@Service,@Repository지정@Component지정만 하면 내부적으로
서버가 동작할 때 Spring은 객체를 생성해서 IoC 컨테이너에 저장함
클래스명이 MyClass면 빈으로 등록되는 객체명은 myClass로 등록
3 Layer Annotation은@Component+ 역할 명시 -
@ComponentScan또는@SpringBootApplication스프링부트를 사용한다면 자동적으로 @ComponentScan이 포함됨
나는 편하게 스프링부트를 사용하므로 @ComponentScan 사용법은 필요할 때 알아보도록 하자main()이 포함된 클래스(그냥 편하게 메인클래스라 하겠다)에서 빈을 찾을 범위를 정해줘야 하는데,
스프링부트 기준 기본값은 다음과 같다스캔 범위(기본값): 메인클래스 파일이 위치한 경로의 같은 레벨 + 그 경로 하위레벨
Bean 사용법 (=주입 방법)
공통. 주입을 실행하는 클래스, 주입당하는 클래스는 모두 Bean으로 등록 (@Component)
1. 필드 직접 주입하는 방법 - 필드에 @Autowired
2. 메서드 주입 (setter) - 메서드에 @Autowired
3. 생성자 주입 - 생성자가 1개일 시 명시하지 않아도 자동 연결됨 (단, Spring 4.3부터) @Autowired
4. Lombok 사용하는 방법 - @RequiredArgsConstructor
5. 직접 컨테이너에서 꺼내는 방법 - 활용 방법은 아래 코드
@Component
public class MemoService {
private final MemoRepository memoRepository;
public MemoService(ApplicationContext context) {
// 1번째 방법 - Bean 객체 이름으로 getBean, 강제형변환 필요
MemoRepository memoRepository = (MemoRepository)context.getBean("memoRepository");
// 2번째 방법 - 리플렉션으로 getBean
MemoRepository memoRepository = context.getBean(MemoRepository.class);
this.memoRepository = memoRepository;
}
...
}
ApplicationContext: BeanFactory 등을 상속받은 Container- BeanFactory : Bean의 생성과 관계설정 등 제어를 담당하는 IoC 객체
getBean(): 2가지 방법

WAS 동작 흐름 정리
내가 배우고 있는 환경 Java Spring Apache Tomcat 기준
-
서버가 뜨면 (처음 서비스를 시작할 때)
지정한 스캔 범위만큼 패키지 내부 파일들을 확인하며 클래스를 객체를 생성해서 IoC 컨테이너에 저장 ==> Bean으로 등록한다고 표현 -
클라이언트가 http request를 날리면
Spring 내부적으로 front Control 패턴이 동작
Dispatcher Servlet이 Handler mapping을 통해 알맞는 @Controller를 찾는다. -
해당 @Controller는 Bean으로 관리 중이니 (즉, 인스턴스를 갖고 있으니) 메서드에 접근 가능하다.
-
그 이후부터 매핑에 맞는 @Controller의 해당 메서드 개발 로직에 따라 애플리케이션 제어 흐름
JPA
Java Persistence API
Java에서 ORM 기술을 적용할 때 사용하는 대표적 표준 명세
ORM
Object-Relational Mapping, 객체-관계 매핑
자바 애플리케이션의 Entity Object <---> DB Entity 수동 매핑 작업을 하려면
JDBC를 직접 다루는 법을 배워야한다
애플리케이션에서 데이터베이스 연동해서
애플리케이션과 데이터베이스 각 엔티티가 정확히 매칭되도록 각각 설정해주어야 하고,
즉, 한 쪽이 수정되면 다른 쪽도 따라서 수정해야 함
서비스를 수행할 때는 그에 맞는 SQL을 직접 작성해서 쿼리를 날림
쿼리 결과를 DTO에 맞게 생성
이것을 자동 처리해주는 기술
JDBC 사용법을 몰라도 된다
Entity
JPA에서 관리하는 객체. 이 객체는 DB의 테이블과 매핑되는 클래스이다.
Persistence Context 영속성 컨텍스트
JPA에서 Entity 객체를 관리하기 위한 공간
Entity 클래스를 설정하면 이곳에 저장됨
실제 코드에서는
트랜잭션과 Entity Manager를 사용하여 연결된 DB와 상호작용한다. (나중에 설명)
연관단어
트랜잭션, 쓰기 지연 저장소, 캐시 저장소
트랜잭션
- 데이터베이스 개념
- 모든 SQL이 성공적으로 수행되고 나면 DB에 영구 반영
- 단 하나라도 실패시 롤백
- 이와 같은 데이터베이스 개념을 JPA에서도 차용
Hibernate 하이버네이트
JPA를 구현한 프레임워크 중 하나, 사실상 표준(de facto)
Spring Boot의 기본 사양
JPA 사용법(Hibernate)
0. 영속성 설정 파일 추가
Spring 미사용 시 영속성 설정 파일을 생성해야 함
/resources/META-INF/persistence.xml 파일 생성
영속성 유닛의 이름,
유닛에 연결될 엔티티 클래스,
연결 DB 정보,
테이블 생성 방식(덮어 씌우냐, 기존에 계속 추가되느냐 등),
실행된 SQL 로그 설정 등을 입력
1. 의존성추가
실습에서는 데이터베이스로 MySQL을 채택
build.gradle
dependencies {
// hibernate
implementation 'org.hibernate:hibernate-core:6.1.7.Final'
// MySQL
implementation 'mysql:mysql-connector-java:8.0.28'
...
}2. IntelliJ에 데이터베이스를 연동
Data Source 추가 - MySQL
MySQL의 해당 데이터베이스를 연동
3. Entity 클래스 설정
엔티티로 사용될 클래스에 @Entity, @Table
반드시 기본 생성자가 필요
@Entity(name = "entity_name")- JPA가 관리할 수 있는 엔티티 클래스 이름을 설정, 기본값: 클래스명@Table(name = "table_name")- 매핑할 데이터베이스의 테이블 이름 지정, 기본값: 엔티티 클래스명
참고: MySQL의 테이블명은 대소문자 구별 하지 않음
@Id- 기본키 설정, 필수@GeneratedValue(strategy = GenerationType.IDENTITY)- Auto Increment@Column(name = "필드명", nullable = [true/false], unique = [true/false], length = 정수값)
name 기본값: 객체 필드명
nullable 기본값: true
unique 기본값: false
length 기본값: 255, 최대 문자길이 설정
4. EM & EMF
Entity Manager & Entity Manager Factory
-
Entity Manager Factory
일반적으로 서버가 동작하는 동안 DB 하나 당 1개의 팩토리 생성 후 동작 -
Entity Manager
EMF가 생성하고 EM을 통해 CRUD 작업 가능
EM은 내부적으로 영속성 컨텍스트에 접근해서 Entity들에 대해 CRUD 작업을 수행 -
EMF, EM 선언 코드
// 생성
EntityManagerFactory emf = Persistence.createEntityManagerFactory("영속성 유닛 이름");
EntityManager em = emf.createEntityManager();
// 데이터베이스 처리 작업
...
// 삭제
em.close();
emf.close();5. 데이터베이스 처리 작업
하나의 의미있는 데이터베이스 처리(CRUD)에는 반드시 트랜잭션을 열고 닫기
EntityTransaction et = em.getTransaction()- 매니저로 트랜잭션 객체 get
et.begin()- 트랜잭션 시작
et.commit()- 트랜잭션 끝, 성공, SQL DB 반영
et.rollback()- 트랜잭션 끝, 실패, SQL 취소
- Create 처리 예시
EntityTransaction et = em.getTransaction();
et.begin(); // 트랜잭션 시작
try {
Memo memo = new Memo(); // 저장할 Entity 객체 생성
// 필드 세팅
memo.setId(1L);
memo.setUsername("사용자이름");
memo.setContents("내용");
em.persist(memo); // 영속성 컨텍스트에 저장
et.commit(); // 정상 -> commit -> DB 반영
} catch (Exception ex) {
ex.printStackTrace();
et.rollback(); // 하나라도 실패 -> 롤백
} finally {
em.close(); // Manager 종료
}
emf.close(); // Factory 종료
...JPA 데이터베이스 처리 작업
캐시 저장소
영속성 컨텍스트에서 관리할 Entity가 저장되는 맵 자료구조
key: @Id
value: Entity
처음 서버를 실행하면 비어있음
1차 캐시?
한 번 CRUD가 수행된 엔티티는 캐시 저장소에 등록되며
바로 DB에서 엔티티를 조회하여 가져오는 것이 아닌
캐시 저장소에서 먼저 검색하고, 찾았다면 DB까지 가지 않아도 됨
이미 만들어진 엔티티 객체가 맵에 있으므로 이것을 재사용한다면 객체 동일성을 보장함
쓰기 지연 저장소(액션큐)
Action Queue
트랜잭션 시작 ~ 커밋 사이에 발생한 데이터베이스에 Insert, Update, Delete SQL을 쌓는 큐
em.flush() - 영속성 컨텍스트의 변경 내용을 DB에 반영, 트랜잭션 중이 아닐 경우 TransactionRequiredException 발생
em.commit() - em.flush() + 큐 비우기
em.rollback() - 큐 비우기
즉, 다음과 같은 데이터베이스 변경 처리는 트랜잭션 필수!
조회는 안해도 동작하지만 필요한 경우가 있으므로 트랜잭션 열자.
<Create, 저장>
em.persist(entity) - 매니저로 영속성 컨텍스트(캐시 저장소)에 Entity를 저장
캐시 저장소는 Map이므로 이미 존재하는 식별자는 넣을 수 없음
<Read, 조회>
EntityClass entity = em.find(EntityClass.class, id) - 엔티티클래스 타입과 식별자(@Id)로 조회
막 서버를 시작했거나 등의 이유로 캐시에 없다면 DB에서 가져와서 캐시에 저장
<Delete, 삭제>
- 삭제할 Entity를
em.find() em.remove(entity)
<Update, 변경>
변경 감지, Dirty Checking
영속성 컨텍스트에 엔티티 객체의 이전 상태가 저장되어있고
em.flush()호출하면 DB를 변경하기 전에 이전상태와 현재상태가 다르면 Update SQL이 자동으로 액션큐에 추가되는 기술
이 원리로 다음과 같이 행동하면 됨
1. entity = em.find() - 조회
2. entity.setter(); ... - 엔티티 변경
Entity 상태와 조작
- 비영속(TRANSIENT) - 인스턴스화된 Entity 객체, 컨텍스트에 저장되지 않음
em.persist(entity)선언 전.- 영속(MANAGED) -
em.persist(entity)후- 준영속(DETACHED) -
detach(), clear(), close()잠시 캐시 저장소에서 제거된 상태,merge()로 영속(MANAGED)상태로 돌아옴- 삭제(DELETED) -
em.remove(entity)후 삭제될 예정의 상태, 트랜잭션 후 제거
em.contains(entity) - 엔티티가 영속성 컨텍스트에서 영속 상태인지 확인 [true/false] 반환
em.detach(entity) - 특정 엔티티를 준영속 상태로 강제 전환
em.clear() - 영속성 컨텍스트 초기화 + 모든 엔티티를 준영속으로 전환
em.merge(entity) - 해당 entity로 영속 상태인 새로운 엔티티를 반환
해당 entity가 영속성 컨텍스트에 없다는 가정 하에-
entity의 비영속/준영속 상태 상관 없이 merge(entity) 수행 시
1) DB에서 해당 entity를 찾아본다 find()
2) 없다면 새 entity 인스턴스를 생성해 값을 복사하고 DB와 컨텍스트에 저장 (Create)
3) DB에 있다면.. DB에서 가져온 entity 객체에
그 내용은 병합 요청한 merge(entity) entity의 값으로 수정된다.
수정된 entity를 DB와 컨텍스트에 저장한다. (Update)
트랜잭션 사용
JPA를 사용하여 DB 작업을 수행하려면 트랜잭션 적용 필수
앞서 본 트랜잭션 방법은 수동적 방법이며,
Spring에서는 @Transactional을 메서드에 달면 수행되는 모든 DB 연산 내용은 하나의 트랜잭션으로 묶임, 예외 발생시 롤백
@Transactional을 클래스에 달면 모든 메서드에 트랜잭션 기능 부여
@Transactional을 클래스에 달고 메서드에도 달면 옵션을 덮어 씌우기 가능
@Transactional(readOnly = false) - 옵션 true면 DB를 조회만 가능, 기본값: false
조회는 트랜잭션이 적용되지 않아도 에러가 나지 않지만
특수한 상황에 대비해@Transactional(readOnly = false)을 명시하자
@Transactional(propagation = Propagation.REQUIRED) - 전파 옵션. 부모 메서드에 트랜잭션이 존재하면 자식 메서드도 그 트랜잭션에 포함? 합류? 이어지게 됨. 기본값 REQUIRED(전파함)
Spring Data JPA**
앞으로 SpringBoot 환경에서 JPA를 쉽게 사용할 수 있는 모듈, Spring Data JPA를 사용해 데이터베이스 처리할 것이다. 이전까지의 Service <-> Controller 방식에서 훨씬 추상화된 작업이므로 실제 개발은 여기부터 참고하자. (em을 직접 조작하지 않는다!)
초기설정
- build.gradle 의존성 추가
dependencies {
implementation 'org.springframework.boot:spring-boot-starter-data-jpa'
}- application.properties 하이버네이트 옵션 설정
// 테이블 create/update 방식*
spring.jpa.hibernate.ddl-auto=update
// SQL 쿼리 로그 출력 옵션
spring.jpa.properties.hibernate.show_sql=true
spring.jpa.properties.hibernate.format_sql=true
spring.jpa.properties.hibernate.use_sql_comments=true
spring.jpa.hibernate.ddl-auto=[옵션]
- create - 삭제후 다시 생성
- update - 변경 사항만 업데이트, 새 테이블 생성 x
- ..등등
엔티티 클래스 정의
@Entity, @Table, @NoArgsConstructor
@Id, @Column, @GeneratedValue(strategy = GenerationType.IDENTITY), ...
이전과 동일!
EMF & EM
application.properties 설정을 하면 EntityManagerFactory 자동 생성되므로 추가 선언 x
@PersistenceContnext - em 선언에 사용하여 자동으로 생성된 매니저를 주입받는 것이 가능
@PersistenceContext
EntityManager em;하지만 Spring Data JPA 모듈을 사용하면 모듈에 em 관리, 조작이 내포되어있다!
기본 쿼리만 사용한다면 em을 따로 선언하지 않는다.
Repository 정의
Spring Data JPA는 JPA를 추상화 시킨 Repository 인터페이스를 제공
따라서, 앞서 Repository 클래스로 정의한 것을
인터페이스로 바꾸고 JpaRepository<>를 상속을 받는다.
public interface MyRepository extends JpaRepository<Entity, Long> {
...
}내부적으로 위 인터페이스를 가지고 SimpleJpaRepository 클래스를 생성하고 Bean으로 등록한다.
이 Bean이 @Service 생성자에 주입된다.
이전에 사용하던 @Repository 클래스가 SimpleJpaRepository로 바뀐 것 뿐임
그렇다고 @Service의 생성자 매개변수를 바꿀 필요 없다. 인터페이스 이름으로 받으면 된다. (이름은 같으므로 변화가 없다)
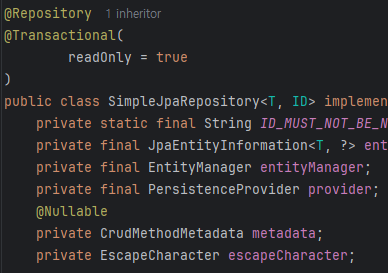
SimpleJpaRepository에 @Repository, @Transactional, EntityManager 등이 선언되어 있음을 확인
그 외에 IntelliJ [Shift-Shift]를 키다운해 SimpleJpaRepository에 정의된 메서드들을 참고할 수 있음
Repository 사용법
3 Layer Architecture를 구현하였다면 @Service 클래스에서 Repository의 처리 방법을 결정한다
따라서 로직에 맞게 Service 내부 메서드에서 Repository 클래스의 탈을 쓴 SimpleJpaRepository 빈 객체를 조작 (=SimpleJpaRepository의 메서드 사용)
<간단 CRUD 예시>
- Create:
save(entity)- 반환값 영속성 컨텍스트에 저장된 entity 객체, 파라미터와 다를 수 있음 (merge) - Read:
findAll()- 테이블의 전체 리스트
findById(id)- 반환값 Optional<>, null 체크 로직을 추가하거나.orElseThrow()로 null인경우 예외 throw - Update:
findById(id)로 해당 엔티티를 찾고 엔티티 메서드(setter)로 수정하면 끝, 주의할 점은 Service의 update() 메서드는 @Transactional이 꼭 필요함 (업데이트 반영 위함) - Delete:
findById(id)로 해당 엔티티를 찾고delete(entity)
부담이 줄어든 것: EM 선언과 관리, 트랜잭션 관리, 영속성 컨텍스트 관리
Query Methods
Spring Data JPA에서 메서드 이름으로 SQL을 생성하는 기능
JpaRepository<>를 상속하는 Repository 인터페이스에 메서드를 정의하기
인터페이스이므로 이름, 반환타입, 매개변수만 지정
보통 반환타입은 List<>
메서드 이름은 레퍼런스 문서 등에 이미 정의된 규칙에 맞게 명명하면
이름을 분석하여 자동으로 구현됨
매개변수는 논리적으로 필요한 것에 맞게 생성됨
예시
List<Memo> findAllByOrderByModifiedAtDesc()
List<Memo> findAllByUsername(String username)
여담) 개인적으로 '우와' 했던 가장 놀라운 기능임
리플렉션으로 메서드 이름을 가져와서 파싱을 하는 걸려나?
추가기능: JPA Auditing
데이터 생성, 수정 시간에 자동으로 타임스탬프 저장해주는 기능
추상클래스 예시코드
@Getter
@MappedSuperclass
@EntityListeners(AuditingEntityListener.class)
public abstract class Timestamped {
@CreatedDate
@Column(updatable = false)
@Temporal(TemporalType.TIMESTAMP)
private LocalDateTime createdAt;
@LastModifiedDate
@Column
@Temporal(TemporalType.TIMESTAMP)
private LocalDateTime modifiedAt;
}@MappedSuperclass: JPA Entity 클래스가 추상클래스를 상속할 때 이 애너테이션이 있어야 추상 멤버변수를 컬럼으로 인식 가능@EntityListeners(AuditingEntityListener.class): Auiditing 기능@CreatedDate: 시간 자동 저장@LastModifiedDate: Entity 값이 변경될 때 시간 자동 변경@Temporal: 날짜 타입을 데이터베이스 매핑할 형식 [Date/Time/Timestamp]@EnableJpaAuditing: @SpringBootApplication 클래스에 (main 메서드) 선언
