Intro
인프라 확장이 없는 웹 애플리케이션(Was + DB)의 동시성을 제어하는 방법은 두 가지 입니다.
- 애플리케이션에서 버전을 통한 낙관적 락
- DB에서 제공하는 비관적 락(X lock)
하지만
낙관적 락은 실패 시 예외처리 + 재시도로 인한 성능 저하의 우려가 있고,
비관적 락은 row 자체에 락을 걸기 때문에 성능 저하가 있습니다.
다른 방법은 없을까?
동시성이 우려되는 로직 자체를 한 번에 한 스레드만 실행할 수 있다면 어떨까요?
영화관을 생각해 볼까요?
상영관의 좌석은 유일한 좌석 입니다.(5관 J행 12열)
영화를 본다는 행위를 로직이라고 가정한다면 해당 좌석의 티켓을 끊은 사람만 영화를 볼 수 있습니다.
영화가 끝난 뒤에 다음 표를 끊은 사람이 들어올 수 있구요.
요지는 어떤 행위를 한 번에 한 사람만 할 수 있다는 것 입니다.
상품 구매와 재고 관리에 적용해보면 어떨까요?
상품 A, 상품 B 등은 락의 키가 될 것입니다. 상품 A에 대한 재고 차감 혹은 증가는 상품 A의 키를 얻은 스레드만 실행할 수 있습니다.
한 번에 한 스레드만 실행할 수 있기 때문에 동시성 문제가 발생하지 않습니다.
그 대신 로직이 길어 락을 점유하는 기간이 길어진다면 그만큼 성능 저하가 발생합니다.
(락을 점유하는 구간은 짧게 가지는 것이 좋습니다.)
이것이 분산락 입니다.
분산락의 원리
분산락이란 여러 서버가(프로세스) 공유 데이터를 제어하기 위한 기술 입니다.
락을 획득한 프로세스 혹은 스레드만이 공유 자원 혹은 Critical Section 에 접근할 수 있도록 하는 것 입니다.
분산락의 장점은 서버 분산 환경에서도 프로세스들의 원자적 연산이 가능한 것 입니다.(아래 그림처럼요.)
락을 획득한 프로세스, 스레드만이 Critical Section 에 접근할 수 있다.
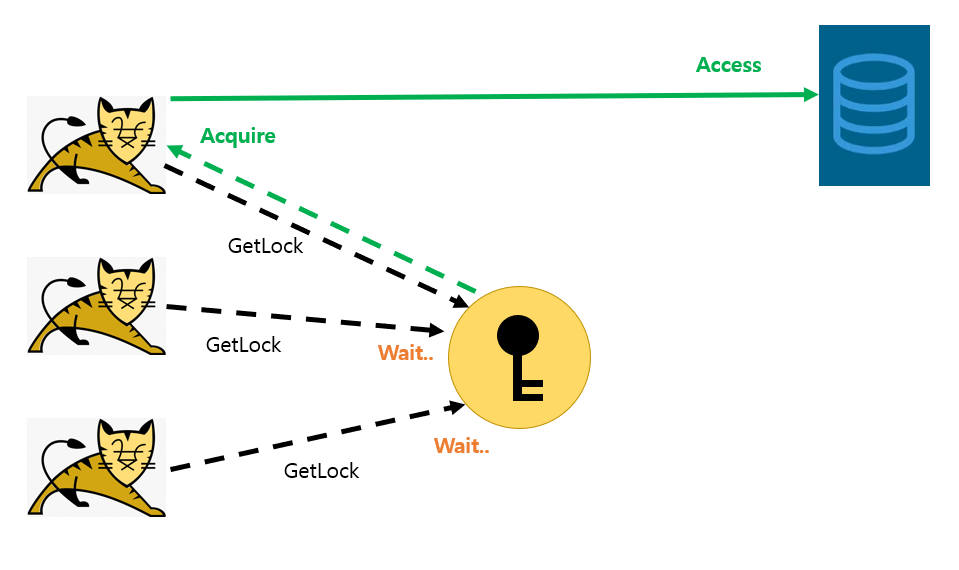
분산락 구현 방법 선택
- Zookeeper : 분산 서버 관리시스템으로 분산 서비스 내 설정 등을 공유해주는 시스템 입니다.
하지만 추가적인 인프라 구성이 필요하고 성능 튜닝을 위한 러닝커브가 존재합니다. 현재는 분산락 이외에 이용할 용도가 없으므로 이용하지 않는것이 좋다고 판단됩니다.
- MySQL : MySQL은 추가적인 인프라 구성없이 문자열로 거는 User Level Lock으로 분산락을 직접 구현할 수 있습니다. 하지만 아래의 단점이 있습니다.
- 락을 자동으로 반납할 수 없어(timeout X) 명시적으로 락을 release 시켜야 한다.
- DB에서 락을 관리하기 때문에 DB에 부담이 여전히 존재한다.
- 락 획득 시도는 스핀락으로 구현해야하기 때문에 WAS에도 부담이 존재한다.
- Redis : Zookeeper와 마찬가지로 별도의 인프라를 구축하고 관리해야하지만 아래의 장점이 있습니다.
- 인메모리 DB로 속도가 빠르다.(초당 100,000 QPS 의 속도)
- 싱글스레드 방식으로 동시성 문제가 현저히 적다.
- 캐시 저장소로 활용이 가능하다.(다양한 자료구조 지원)
Redis 라이브러리에서 다양한 분산락 구현체들을 지원하기 때문에 손쉽게 사용이 가능할 뿐 만 아니라 레디스를 글로벌 캐시 저장소로 이용할 수 있기 때문에 Redis를 추천 합니다.
인메모리 DB Redis!

Redis 구현체를 선택해보자
자바에서 사용할 수 있는 레디스 클라이언트는 크게 세가지 입니다.
- Jedis
- Lettuce
- Redisson
Jedis보다 Lettuce의 성능이 훨씬 좋기 때문에(동기, 비동기 지원)
Lettuce와 Reddison을 비교해보겠습니다.
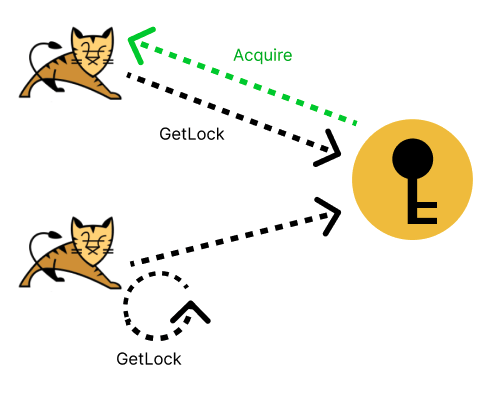
Lettuce는 스핀락을 사용해요.
- setnx를 활용한 스핀락
- setnx(SET if Not eXists)은 레디스에서 제공하는 원자적 연산 입니다.
(값이 존재하는지 확인 -> 없으면 값 세팅)
이 명령어를 통해 루프문을 활용해 키에 해당하는 값이 있는지 확인 후 없다면 키를 획득합니다.

Lettuce로 구현한 스핀락 예제 입니다.
private RedisTemplate rt; /**Lettuce 라이브러리 대신 spring data redis를 사용하면 키를 획득할 때 timeout을 적용할 수 있습니다.**/ public void SampleSpinLock(final String key, ...//비지니스 로직 파라미터) throws InterruptedException { Boolean getKey; do { getKey = rt .opsForValue() //redis의 String(key, val) 사용 .setIfAbsent(String.valueOf(key), //key "lock", //value 300L, //wait time TimeUnit.MILLISECONDS); //setnx 사용 명령어 } while (!getKey) { Thread.sleep(50);//과도한 반복으로 인한 부하를 막기 위해 약간의 sleep을 사용 } if (!getKey) return;//타임아웃 후에도 key를 얻지 못했으면 종료 try { //비지니스 로직 } finally { //키 반납 rt.delete(String.valueOf(key)); } }
재시도 횟수를 정하는 로직을 더할 수는 있지만 기본적으로 스핀락은 일정 시간 이후 레디스에게 setnx 요청을 하게 됩니다.
요청이 많을수록 레디스에 더 많은 부하가 발생하게 됩니다.
300ms가 걸리는 비지니스 로직을 100개의 클라이언터가 실행했다고 가정해보겠습니다.
락을 획득한 한 개의 클라이언터 외의 99개의 클라이언트는 50ms 후에 락 획득을 재시도 합니다.
클라이언트 Lock Time Redis 100 UnLocked 99 -> TryLock Client1 Locked Client1 ... 50ms later Locked 99 -> TryLock Client1 Locked Client1 ... 50ms later Locked 99 -> TryLock Client1 Locked Client1 ... 50ms later Locked 99 -> TryLock Client1 Locked Client1 ... 50ms later Locked 99 -> TryLock Client1 Locked Client1 ... 50ms later Locked 98 -> TryLock Client2 Locked 표에서 보이는것과 같이 300ms 간 레디스에는 495번의 락 획득 시도가 일어납니다.(Client1의 락 획득 이후 ~ Client2가 락 획득할 때 까지)
1초동안 발생한다면 약 1980번(495 * 20)의 요청이 레디스에 발생합니다.
출처 : https://hyperconnect.github.io/2019/11/15/redis-distributed-lock-1.html
(HyperConnect Fitz님의 레디스를 활용한 분산 락과 안전하고 빠른 락의 구현)
- 스핀락이 락을 획득하는 방법
Redisson이 왜 좋아요?
Lettuce는 반복적으로 락 획득을 시도하기 때문에 레디스에 많은 부하가 발생합니다.
Redisson은 아래와 같은 방법으로 리소스를 절약하고 있습니다.
LuaScript로 Atomic 연산 제공
Redis는 내부적으로 Lua Engine을 가지고 있습니다. Lua Script로 쓰여진 로직은 한 커멘드로 레디스 서버 내부에서 작동합니다.
때문에 setnx와 같은 로직을 한 번에 실행시켜 Atomic한 연산을 할 수 있을 뿐만 아니라 애플리케이션 서버에서 Redis 서버로 가는 네트워크 비용도 절약할 수 있습니다.
다만, Lua Script는 싱글 스레드로 작동하는 Redis에서 하나의 커맨드로 동작하기 때문에 연산이 길어진다면 그만큼 blocking 하는 시간이 길어짐을 주의해야 합니다.
PubSub 사용
Redisson은 Redis가 제공하는 Message Broker을 사용해 키가 반납되면 Publisher가 등록된 Subscriber에게 채널을 통해 키를 획득할 수 있다고 알려줍니다.스핀락처럼 클라이언트가 지속적으로 레디스에게 요청하는 것이 아닌닌 별도의 Pub이 자신의 Sub들에게 키 획득이 가능할 때 메세지를 주고 클라이언트는 비로소 락을 획득할 수 있습니다.
때문에 리소스가 절약되는 것 입니다.
PubSub에 대한 기본적인 내용은 https://velog.io/@a01021039107/%EB%A6%AC%EC%95%A1%ED%8B%B0%ED%94%84-%EC%8A%A4%ED%94%84%EB%A7%81-2.-Reactive-Stream%EC%9D%84-%EC%A7%81%EC%A0%91-%EB%A7%8C%EB%93%A4%EB%A9%B0-%EC%9D%B4%ED%95%B4%ED%95%B4%EB%B3%B4%EC%9E%90
를 참고해주세요.
RedLock 구현
일반적으로 PubSub 구조의 분산락을 구현한다면 싱글 인스턴스에 의존적이기 때문에 클러스터 환경, Master-Slave 환경에서는 결함 허용성이 부족합니다.
즉, 한 클러스터 혹은 Master에서 락 획득에 결함이 발생했을 때 이후 행동(Lock 없이 실행할 것 인지, fail처리 할 것인지, 재시도 할 것인지)가 어렵다는 점 입니다.이를 해결하기 위해 RedLock 알고리즘이 있습니다.
자세히 이야기하면 길어지기 때문에 간단히 요약하자면
현재시간을 기준으로 n개의 모든 노드에서 Lock 획득을 시도한다. 가 포인트 입니다.
참고 https://redis.io/docs/manual/patterns/distributed-locks/하지만 이 행동으로 인해 클러스터 환경에서는 Redis 싱글 인스턴스에 비해 성능 저하가 극심합니다.
또한 가용성 측면에서 멀티 노드의 레디스는 관리 포인트가 증가합니다.
결론
- 이러한 단점에도 불구하고 싱글 인스턴스로 구성된 레디스를 분산락 서버로 사용한다면 단순히 락 점유 로직만 수행한다면 부하가 심하지 않을거라 생각됩니다.
다음 글에서는 Redisson 구현체를 통해 분산락을 구현해보겠습니다.

좋은 정보 감사드려요!! 잘보고갑니당