
경진대회?
과기정통부 주최, 정보통신산업진흥원 주관으로 인공지능 기술의 저변을 확대하고 알고리즘 개발 능력이 우수한 예비창업자, 중소·개척기업(벤처기업) 등을 선발하여 인공지능 기술 기반 사업화 기회를 제공하는 대회이다. 대회 기간은 2021년 6월 21일부터 시작하여 7월 2일까지 약 2주 동안 진행되었다.
운전 사고 예방을 위한 운전자 부주의 행동 검출 모델
운전자 얼굴 이미지를 이용해 운전자 상태를 나타내는 객체를 탐지하는 모델을 개발하는 Task를 진행하였다. 7가지의 운전자 상태를(얼굴, 눈, 입, 담배, 휴대폰 등) 분류하며, mAP@IoU=0.75 지표로 평가한다. Test Set의 Public, Private 데이터 비율은 3:7정도 이다.
- mAP (Mean Average Precision)
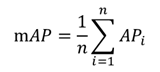
- IoU (Intersection over Union): 객체 탐지 여부 판별을 위한 threshold 0.75 설정
최근 교통사고에서 사망 사고 원인별로 조사 결과, 졸음 및 주시 태만이 67.6%로 가장 높은 것으로 기록된다고 한다.
아마 이런 7종의 데이터를 사용 분류하는 모델을 센서 기술에 도입하여 운전자의 위험 행동을 감지하여 주의를 주는 서비스를 개발하려는 것 같다.
데이터는
- 바운딩 박스 좌표(position)
- absolute pixel 좌표
- x1, y1 (top-left)
- x2, y2 (bottom-right)
- 클래스 (class)
- Train
/images: 273.224개의 이미지 파일labels.json: 각 이미지의 bounding box 좌표(absolute pixel)와 class- Test
/images: 35,631개의 이미지 파일
Baseline model
대회가 시작되고 테스트, 학습, 데이터 로드 코드를 분석하고자 Baseline model을 다운받았는데....
아니!! 마침 인공지능 경진대회 전에 미리 공부해둔 Yolov5의 코드와 거의 동일했던 것이었다.
이때 생각한게"와 진짜 Yolov5 공부 안 했으면 삽질했겠다"라는 생각을 했다. (다른 팀은 Yolov5가 아닌 다른 모델을 사전 신청해서 사용했던 것 같다)
그래서 처음에는 아주 순탄하게 가겠구만…. 이라는 생각으로 점수를 올리기 위한 여러 가지 아이디어를 생각하고 있었다.
하지만 거대한 벽이 우리 앞을 가로막는데….
데이터 드라이브에 쑤셔넣기😥
사실 대회 당시 팀원으로 서버가 없었다. 특히 GPU가 달린 서버는 꿈도 못꾸었는데, 학생이기도 하고 서버를 사서 학습시킬정도로 여유가 있지 않았기 때문이다. 그래서 생각한 방법은
Google 공유 Drive와 달에 만천원정도하는 Colab pro 이 두가지 이다.
근데 23GB 정도의 30만장의 사진을 구글 공유 드라이브에 올리려 정말 많은 시간을 허비해버렸다.😨
-
사실 용량보다는 이미지 데이터의 양이 너무 많다 보니 구글 서버에서 드라이브에 하나하나 올리는 속도가 너무 느리다. 그래서 드라이브 창이 튕기고 드래그앤 드롭하면 오류가 뜬다.
-
음.. 그러면 Zip파일을 올리고 Colab에서 unzip하면 되는거 아니야?
-
이 방법은 Colab환경에는 30만장의 사진이 올라오지만, 드라이브에 올라가는 시간은 이전과 똑같고, Colab의 런타임이 끊어지면 업로드가 끊기기 때문에 이전과 똑같다.
-
대략 30만장의 사진을 드라이브에 올리려면 2일 정도는 코랩을 켜놓아야 한다.
진짜 돈 많이 벌면 GPU 빵빵한 데스크탑부터 산다. 그 다음은 집에 홈짐 차리기
해결방법
-
ㅋㅋㅋ 30만장을 한번에 못올리면 나눠서 올리자 해서 대충 10토막을 내어(3만장) 드라이브에 각각 올리는 방식을 택했다.
-
이 방법도 좋은 방법은 아닌데, 어느 정도 문제는 해결 되었다.
-
하지만 나누었기 때문에, 라벨링과 yaml파일을 다시 만들어야 했다.
여러 전처리
-
label.json 파일에서 중요 정보를 학습시 사용할 txt로 뽑아오도록 라벨링 했다.
-
Test를 하였을 때 나올 Json 파일이 Submission 형식에 맞도록 수정해주었다.
-
열악한 Colab환경에서 더욱 빠른 학습을 위해, 이미지의 이름을 0000000.jpg 이런 형식으로 변경해주었다. (이건 나의 뇌피셜이다.... 맞는지 틀린지는 몰라용)
첫 제출
-
Lr이나 Adam의 베타값은 default로 고정하고 약 3만장을 학습시켜 제출하였다.
-
첫 제출 결과는 11등
-
암담하지만 첫술에 배부를 수 없다고 포기하지 않고 성능을 개선할 방법을 고민했다.

성능 개선
-
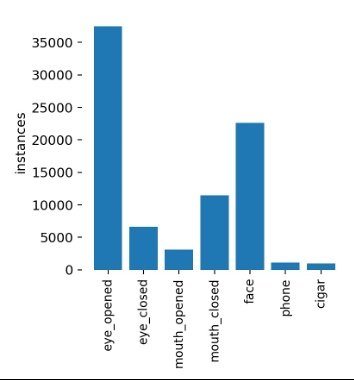
첫 번째로 클래스의 불균형을 맞춰주고자 30만장에서 ["phone", "cigar", "eye"]에 대한 데이터만을 모아서 데이터의 불균형을 해결하였다.
-
Yolov5의 여러 아키텍쳐로 학습시켜보고 성능이 가장 좋은 것 뽑기
-
다른 아키텍쳐를 가지고 앙상블을 통해 Test하기
-
Ensemble은 서로 다른 예측 모형들을 합쳐 더 강한 예측 모형을 만들 수 있다. 예로 정확도가 0.7 0.7인 두 모델을 합쳐 0.9의 성능을 뽑아낼 수 있다.
최종 결과

결국 3등이라는 좋은 결과를 얻게 되었다. 사실 제출하고 점수가 딱 떴을 때, 그 희열은 아직도 잊히지 않는다. 처음에는 단순 호기심과 경험을 목적으로 나간 대회에서 높은 등수 안에 들다니...
아쉬웠던 것은 초짜여서 정말 직관적인 코딩을 하였다.
시간이 더 있었다면 Loss나 Optimizer의 값도 변경해가면서 보다 창의적인 시도를 해봤을 텐데…. 아아!! 다시 생각해보니 컴퓨팅 파워가 따라주지 않아서 시도조차 안 할 것 같다…. ㅋㅋㅋ 이것도 아쉬운 점 중 하나이다.
아마 우리의 고득점 요인은 성능 개선부분에서 했던 3가지가 제일 컸던 것 같다.
그리고 팀 이름도 학교 과 이름으로 나간 것이 조금 아쉽다. (팀만의 정체성이 없달까)
지금은 물론 "알로하"라는 팀명으로 여러 가지를 하고 있지만 말이다.
사실 사업화의 기회도 주어졌는데 사업에 대해 팀원 모두가 까막눈이라서 하고 싶어도 할 수 없는 상황이었다. 만약 사업계획서를 쓸 능력과 여러 지식이 있었으면 또 어땠을까라는 생각을 해본다.
이번 경진대회는 정말 값진 경험이었다. 무엇보다 거셌지만 순위가 조금씩 올라감에 재미를 느꼈고, 당연히 자신의 역량도 많이 늘었으니 말이다.
다음부터는 GPU제공 Task를 해야겠다.
