E-Commerce MSA Ver2
MSA를 처음부터 선택한 이유
미래에는 다양한 통신 장비의 등장과 함께 인터넷 트래픽이 급증할 것이며, 기업들은 이를 처리할 수 있는 역량을 요구하게 될 것입니다. 이러한 맥락에서 MSA를 경험해 보고 싶었습니다. MSA 환경은 우리 팀에게는 새로운 설계 방식이었지만, 이를 통해 많은 트래픽을 다룰 수 있는 경험을 쌓을 수 있을 것이라고 생각했습니다.
프로젝트 방향성 논의
처음에는 프로젝트를 어떤 방식으로 진행할지 두 가지 방향성을 두고 논의했습니다.
- Monolithic Architecture(MA)로 기본 기능 개발 후, MSA로 전환하기
- 처음부터 MSA 환경으로 개발하기
고려 사항 분석
MA와 MSA 두 가지 접근 방식의 차이를 분석했습니다. 가장 큰 차이점은 "트랜잭션의 범위"와 "예외 처리 방식"이었습니다.
- MA 구조: 모든 도메인이 하나의 시스템 내에 존재하며, 데이터베이스도 공유하기 때문에 하나의 서비스 내에서 트랜잭션 관리가 용이합니다.
- MSA 구조: 도메인 별로 독립적인 서비스로 분리되어 트랜잭션이 분산되며, 분산된 트랜잭션 환경에서 트랜잭션 실패에 따른 예외 처리 방식이 달라집니다.
결정 및 실행
결국, 두 번째 접근 방식인 "처음부터 MSA 환경으로 개발하기"를 선택했습니다. 이는 짧은 프로젝트 기간 동안 팀원들이 MSA로 분리된 서비스의 전체 흐름과 상호작용을 깊이 이해할 수 있는 가장 적합한 방법이라고 판단했기 때문입니다.
프로젝트 초반에 우리는 Spring Cloud 공식 문서를 함께 읽고, Spring Boot와 Spring Cloud 기반의 기본적인 MSA 서비스를 만드는 실습을 진행했습니다. 서로 학습한 내용을 공유하고, 이해가 안 되는 부분은 질문하며 함께 해결해 나갔습니다.
결과 및 경험
모든 팀원이 독립적인 서비스들의 관계를 이해했기 때문에 프로젝트 진행 중 분산 트랜잭션 환경과 예외 처리에 대해 활발히 토론할 수 있었습니다. 이를 통해 처음 맞닥뜨리는 문제들을 효과적으로 해결할 수 있었습니다.
이러한 경험은 앞으로 더 많은 트래픽을 처리할 수 있는 역량을 키우는 데 큰 도움이 되었으며, 팀원 모두에게도 의미 있는 학습 기회가 되었습니다.
MSA와 DDD(Domain-Driven Development)
도메인 설계 원칙
느슨한 결합(Loose Coupling)과 높은 응집(High Cohesion)
- 느슨한 결합: 다른 서비스들 간의 결합을 최소화하여 각 서비스가 독립적으로 변경될 수 있도록 합니다.
- 높은 응집: 같은 서비스 내에서 관련된 기능과 데이터를 최대한 밀접하게 묶어 유지합니다.
도메인 나누기
도메인을 나눌 때 우리는 3가지 요소를 고려했습니다.
- 변경 영향도: 특정 도메인에서 변경이 발생해도 다른 마이크로서비스에 영향을 미치지 않아야 합니다. MA에서는 특정 부분의 변경이 전체 시스템에 영향을 미칠 수 있지만, MSA에서는 적절한 경계를 가진 도메인 덕분에 영향을 최소화할 수 있습니다.
- 독립적 배포: 각 마이크로서비스를 독립적으로 배포할 수 있어야 합니다.
- 기술 다양성: 도메인 내 서비스는 높은 응집 원칙에 따라 비슷한 기술 스택을 가져야 하지만, 도메인 간 서비스는 느슨한 결합 원칙에 따라 다른 기술 스택을 사용할 수 있습니다.
도메인 분리
위의 원칙을 바탕으로 도메인을 다음과 같이 나누었습니다:
- MemberService: 회원 관리 서비스
- ItemService: 상품 관리 서비스
- PaymentService: 결제 서비스
- OrderService: 주문 처리 서비스
- ReviewService: 리뷰 관리 서비스
- SearchService: 상품 검색 서비스 (추가됨)
- AggregateService: 상품 데이터 W/R 동기화 워커 (추가됨)
도메인 설계 결과
우리 팀은 각 도메인의 독립성을 유지하면서도 필요한 부분에서의 결합을 최소화하는 데 중점을 두었습니다. 이를 통해 각각의 마이크로서비스가 독립적으로 동작하고 배포될 수 있으며, 시스템의 변경에도 유연하게 대응할 수 있었습니다. 이러한 설계 덕분에 우리는 처음 맞닥뜨린 문제들을 효과적으로 해결할 수 있었으며, 팀원 모두가 MSA와 DDD의 원칙을 깊이 이해하게 되었습니다.
시스템 아키텍처
이번에는 프로젝트 진행 중 구상하고 구현했던 아키텍처에 대해 설명하겠습니다. 저희 팀은 아키텍처에 대해 많은 회의와 토론을 거쳤습니다.
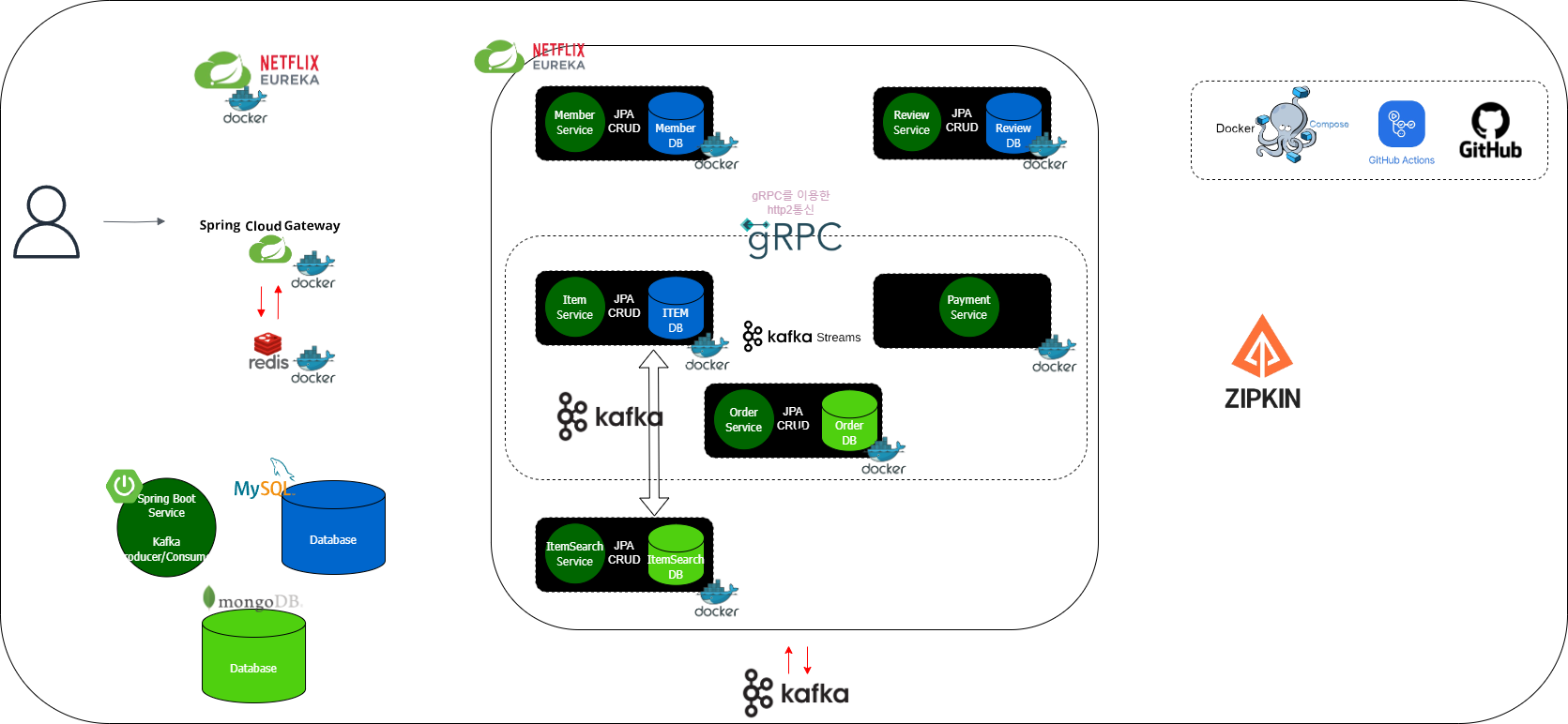
초기 아키텍처
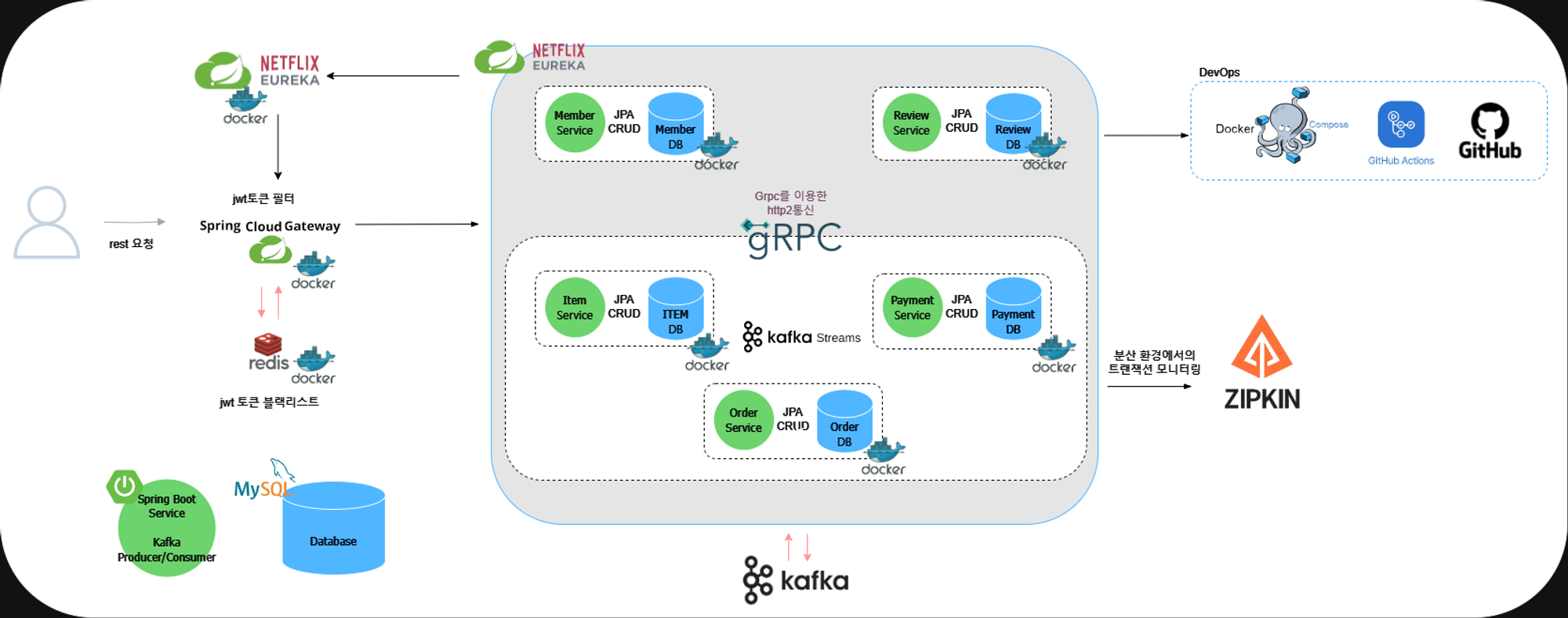
최종 아키텍처
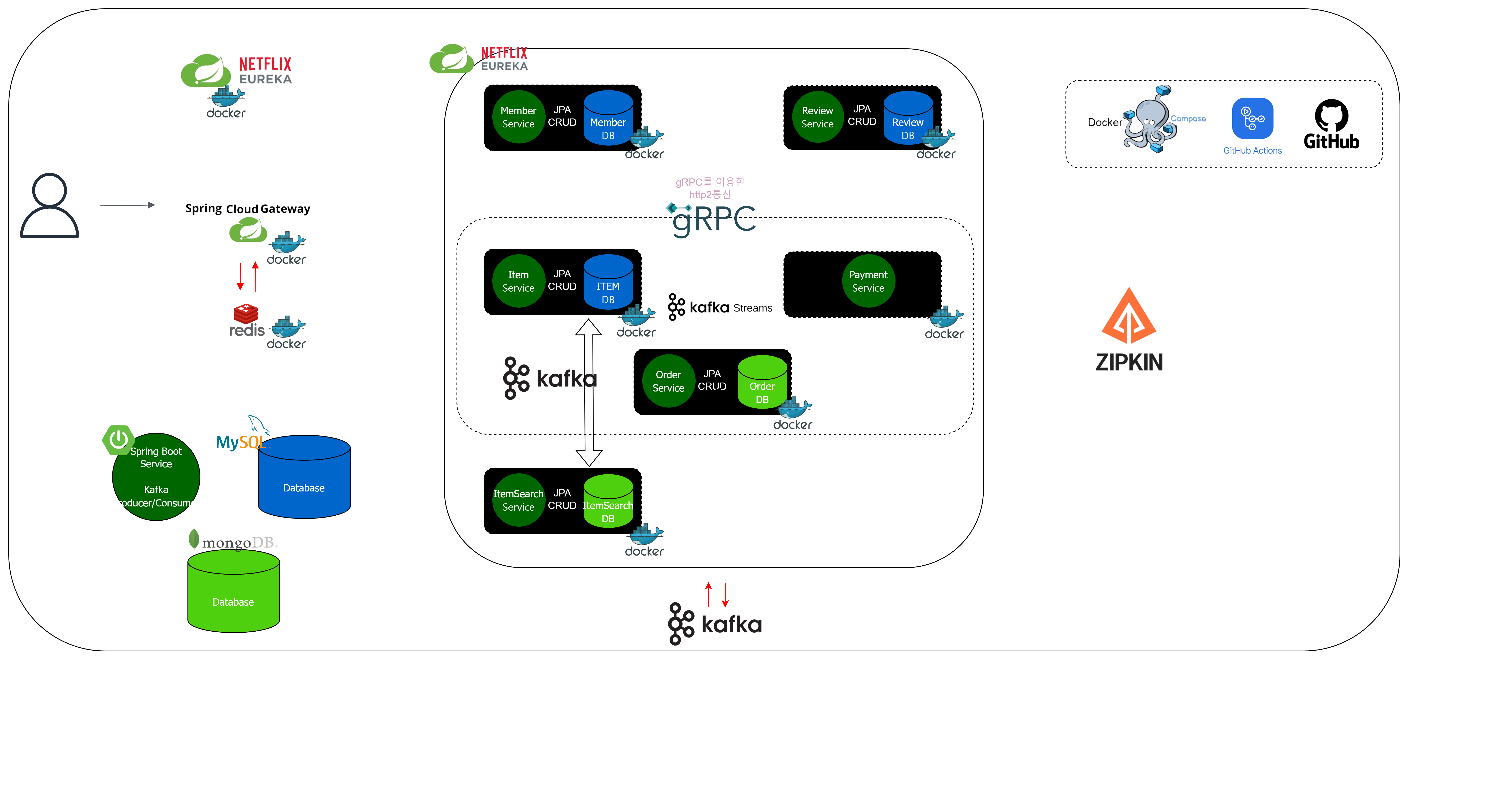
아키텍처에 대해 설명드리겠습니다.
-
jwt 토큰: 시스템의 확장성과 유지보수를 고려하여 세션 기반 인증과 토큰 기반 인증(JWT)을 비교 검토했습니다.
-세션 기반 인증-
서버에 세션 생성 후, 클라이언트는 세션 ID를 쿠키에 저장해 서버에 전송.
장점: 구현이 간단하고 보안성이 높음.
단점: 사용자 증가 시 세션 데이터 관리와 분산이 복잡. 서버 확장 시 추가 인프라와 복잡한 시스템 설계 필요.
-토큰 기반 인증 (JWT)-
무상태(Stateless) 구조로, 서버가 JWT를 생성해 클라이언트에 전달. 클라이언트는 이후 모든 요청에 토큰을 포함.
장점:
확장성: 서버에 세션 데이터를 저장하지 않아 자유로운 서버 확장 가능.
무상태성: 각 요청이 독립적으로 처리되어 MSA 환경에서 서비스 간 의존성 최소화.
유연성: 토큰에 인증 정보를 포함하여 다양한 서비스에서 동일한 인증 메커니즘 사용 가능.
결론
JWT 토큰 기반 인증 도입을 통해 확장성과 유지보수성을 높이고, MSA 환경에 적합한 무상태 구조를 유지하여 사용자 수 증가 시 시스템 성능과 안정성을 보장할 수 있습니다. -
redis 토큰 블락처리: 로그아웃한 토큰은 유효기간이 만료되기전에도 서버에서 인증을 막아야 했는데 이 때 mysql db를 사용하기 보다 속도 측면에서 우수한 redis를 사용하게 됐습니다.
-
API Gateway: 이 애플리케이션은 jwt 토큰을 활용해 유저의 login을 담당합니다. 또한 Eureka 서비스로부터 등록된 애플리케이션 정보를 얻고, 해당 API를 담당하는 마이크로서비스로 요청을 라우팅합니다.
-
마이크로서비스 간 상호작용: 각 마이크로서비스는 Grpc와 Kafka Producer/Consumer 패턴을 통해 상호작용합니다.
-
메시지 처리: 다른 서비스에 데이터를 삽입하거나 수정할 때는 Kafka Producer를 사용하여 메시지를 발행하고, Consumer를 통해 메시지를 수신하고 처리합니다.
-
Kafka를 통한 cdc 구현: 카프카를 이용해 Item도메인의 쓰기 테이블(Mysql)과, 읽기 테이블(mongoDB)간의 Change Data Capture(CDC)를 구현했습니다.
MSA를 도입하면서 새롭게 배운 기술들
MSA 설계로 넘어오면서 기존의 MA에서 사용되던 기술적 패러다임이 바뀌게 되었습니다. 이로 인해 저희들은 프로젝트를 진행하면서 아래와 같은 문제에 직면하게 됩니다.
- 기존에 하나의 서버에서 조회하던 Entity들이 다수의 MS로 분리되어 있다면 Entity 간의 정보를 조합해서 사용해야 할 때는 어떻게 해야하지?
- 분산 트랜잭션 환경에서의 데이터 정합성을 어떻게 맞춰야하지?
- Micro Service 간의 DB의 접근 시 발생하는 다수의 Connection으로 인한 성능 저하
- MS와의 통신 중 실패했을 경우의 예외 처리
저희들은 이러한 문제를 해결하기 MA에서 사용하지 않는 다양한 기술들을 도입하게 되었습니다.
1.번 해결방안 : Grpc http2 통신
기존 MA에서 단순히 도메인 간의 Join을 시도해서 해결하면 되지만 MSA 환경에서는 기존 서비스의 도메인이 없는 상황에서는 조인을 할 수 있는 방법이 없습니다. 이로 인해 서버와 서버 간의 HTTP 요청을 해야 하는 상황이 존재했습니다. 이를 해결하기 위해 저희 팀은 FeignClient를 통해 필요한 데이터를 HTTP 형식으로 요청과 gRPC를통한 HTTP/2 형식의 요청 중 고민을 했습니다.
gRPC는 Google에서 개발한 오픈 소스 원격 프로시저 호출(RPC) 시스템입니다. 특징은 프로토콜 버퍼(Protocol Buffers)를 사용하여 직렬화된 데이터를 전송하며, 성능이 뛰어나고 다중 언어를 지원하는 점입니다. 또한, gRPC는 HTTP/2를 기반으로 하여 payload가 적고, 양방향 스트리밍, 흐름 제어, 헤더 압축 등의 기능을 제공합니다.
FeignClient는 넷플릭스가 개발한 오픈 소스 HTTP 클라이언트 바인더로, 스프링 클라우드(Spring Cloud)에서 많이 사용됩니다. FeignClient를 사용하면 RESTful API와의 상호작용을 단순화할 수 있으며, 선언적 방식으로 HTTP 요청을 작성할 수 있습니다. 주요 특징으로는 인터페이스 기반의 클라이언트 정의, 간결한 코드, 그리고 다른 스프링 클라우드 구성 요소들과의 통합이 있습니다. FeignClient는 Ribbon을 사용한 로드 밸런싱, Hystrix를 통한 회로 차단기 패턴 지원 등 다양한 기능을 제공합니다
저희는 추후 쿠버네티스로의 확장을 고려하고 있고,
처리속도가 빠른 아키텍처를 만들기위해 gRPC를 선택했습니다.
gRPC에 대한 설명을 글로만 읽는 것은 안 와닿을 수 있으니 코드로 예시를 들어보겠습니다.
아래는 OrderMS에서 Search MS의 정보가 필요한 경우의 예시입니다. 요청자인 Member MS에서는 gRPC 스텁을 사용하여 Search MS의 서비스를 호출하면 Search MS에서 제공하는 정보를 가져올 수 있습니다.
먼저 프로토콜 버퍼를 사용하여 서비스 인터페이스를 정의합니다.
syntax = "proto3"; // 프로토콜 버퍼의 버전 3을 사용
option java_multiple_files = true; // Java 생성 시 여러 파일로 생성
option java_package = "com.ecommerce.grpc"; // 생성된 Java 클래스의 패키지 설정
option java_outer_classname = "ItemsProto"; // 생성된 Java 클래스의 외부 클래스명 설정
import "product_info.proto"; // 다른 프로토콜 버퍼 파일을 가져옴
// ProductsInfoService gRPC 서비스 정의
service ProductsInfoService {
// getProductsInfo 메서드를 정의, ProductsRequest를 입력으로 받고 ProductsReply를 반환
rpc getProductsInfo (ProductsRequest) returns (ProductsReply) {
}
}
// ProductsRequest 메시지 정의
message ProductsRequest {
// ProductRequest 메시지 타입의 items 필드를 반복적으로 포함
repeated ProductRequest items = 1;
}
// ProductsReply 메시지 정의
message ProductsReply {
// ProductReply 메시지 타입의 items 필드를 반복적으로 포함
repeated ProductReply items = 1;
}
이제 Order MS에서 gRPC 클라이언트를 설정합니다.
package com.ecommerce.orderservice.grpclient;
import com.ecommerce.grpc.*;
import com.ecommerce.orderservice.exception.OrderException;
import io.github.resilience4j.circuitbreaker.annotation.CircuitBreaker;
import io.grpc.StatusRuntimeException;
import lombok.RequiredArgsConstructor;
import lombok.extern.slf4j.Slf4j;
import net.devh.boot.grpc.client.inject.GrpcClient;
import org.springframework.http.HttpStatus;
import org.springframework.stereotype.Service;
import java.util.List;
@Service // Spring 서비스로 등록
@Slf4j // Lombok 애노테이션으로 로깅 활성화
@RequiredArgsConstructor // Lombok 애노테이션으로 필수 인자를 포함하는 생성자 자동 생성
public class ProductsInfoClient {
@GrpcClient("search-service") // gRPC 클라이언트를 search-service로 설정
private ProductsInfoServiceGrpc.ProductsInfoServiceBlockingStub client;
@CircuitBreaker(name = "searchService", fallbackMethod = "fallback") // 서킷 브레이커 패턴 적용, 실패 시 fallback 메서드 호출
public ProductsReply requestProductsInfo(List<ProductRequest> productRequests) {
var request = ProductsRequest.newBuilder().addAllItems(productRequests).build(); // ProductsRequest 메시지 빌드
log.info("gRPC 서버에 상품 정보를 요청합니다.");
ProductsReply response = this.client.getProductsInfo(request); // gRPC 서버에 요청하여 응답 받음
log.info("gRPC로부터 응답을 받았습니다.");
return response;
}
// fallback 메서드: gRPC 요청 실패 시 호출됨
public ProductsReply fallback(List<ProductRequest> productRequests, Throwable t) {
log.error("search-service에 대한 gRPC 요청 실패. ProductsInfoClient의 fallback 메서드가 호출됩니다.");
return null; // fallback 처리: null 반환 (다른 대체 로직을 여기에 추가 가능)
}
}
이제 Search MS에서 gRPC 서버를 설정합니다.
@Slf4j // Lombok 애노테이션으로 로깅 활성화
@GrpcService // 이 클래스를 gRPC 서비스로 마크
@RequiredArgsConstructor // Lombok 애노테이션으로 필요한 인자(final 필드)로 생성자 생성
public class ProductServerService extends ProductsInfoServiceGrpc.ProductsInfoServiceImplBase {
private final ProductRepository productRepository; // 의존성 주입된 상품 데이터 리포지토리
@Override
public void getProductsInfo(final ProductsRequest req, final StreamObserver<ProductsReply> responseObserver) {
// 들어오는 gRPC 요청으로부터 상품 요청 목록을 가져옴
List<ProductRequest> productRequests = req.getItemsList();
log.info("gRPC로 상품 정보 요청 받음");
List<ProductReply> reply = new ArrayList<>(); // 각 상품 요청에 대한 응답을 저장할 리스트
for(ProductRequest productRequest : productRequests) {
int sellerId = productRequest.getSellerId(); // 상품 요청으로부터 판매자 ID를 가져옴
log.info("판매자 ID: " + sellerId);
String name = productRequest.getProductName(); // 상품 요청으로부터 상품명을 가져옴
log.info("상품명: " + name);
Product product = null;
if(sellerId == 0) { // 판매자 ID가 0인 경우, 상품명으로만 상품을 찾음
product = productRepository.findByName(name).get(0); // 상품명을 기준으로 상품을 조회
reply.add( // 상품 응답을 리스트에 추가
ProductReply.newBuilder()
.setProductId(product.getProductId())
.setProductPrice(product.getListings().get(0).getPrice())
.setProductQuantity(product.getListings().get(0).getQuantity())
.setProductStatus(product.getListings().get(0).getStatus())
.build()
);
break; // 상품명을 기준으로 찾은 경우 루프 종료
} else {
product = productRepository.findByNameAndListingsSellerId(name, sellerId); // 상품명과 판매자 ID로 상품 조회
}
if(product == null) { // 상품이 없을 경우 예외 발생
throw new RuntimeException("상품을 찾을 수 없습니다");
}
List<Listing> listings = product.getListings(); // 상품의 리스트 목록 가져옴
// 주어진 판매자 ID에 대한 특정 리스트를 찾음
Listing target = listings.stream()
.filter(listing -> listing.getSellerId() == sellerId)
.findFirst()
.orElseThrow(() -> new RuntimeException("리스트를 찾을 수 없습니다"));
log.info("상품 ID: " + product.getProductId());
int status = target.getStatus() != null ? target.getStatus() : 0; // 상태 값이 null인 경우 0으로 설정
// 필요한 세부 정보로 상품 응답을 빌드
ProductReply productReply = ProductReply.newBuilder()
.setProductId(product.getProductId())
.setProductPrice(target.getPrice())
.setProductQuantity(target.getQuantity())
.setProductStatus(status)
.build();
reply.add(productReply); // 상품 응답을 리스트에 추가
}
// 최종 상품 응답을 빌드하고 클라이언트로 전송
ProductsReply productsReply = ProductsReply.newBuilder().addAllItems(reply).build();
responseObserver.onNext(productsReply); // 응답 전송
responseObserver.onCompleted(); // 응답 완료
}
}2번 해결방안 : kafka streams를 통한 Event driven architecture 와 Saga Orchestration 패턴
KafkaStream & saga(Orchestration) 패턴
주문 처리를 진행할 때 Order MS-> Product MS -> Payment MS 로 분리돼있는 3개의 서비스간의 로직들을 하나의 트랜잭션으로 통합해야했는데 이 때 각 서비스의 DB도 분리 돼있어서 ACID 특성을 잃은 상태였습니다. 이러한 분산 트랜잭션 환경에서 ACID특성을 유지 시키기 위해 팀 내에서는 많은 토의를 진행했었고, 결과적으로 Kafka를 이용한 saga Orchestration 패턴을 적용하기로 결정하였습니다.
이를 구현하기 위해서는 모든 이벤트를 저장하기 위한 수단이 필요합니다. 그중 Kafka의 고가용성, 분산처리, 파티션 단위의 내부로직 분할은 Event Store의 역할을 하기에 적합합니다.
오케스트레이션 saga 아키텍처
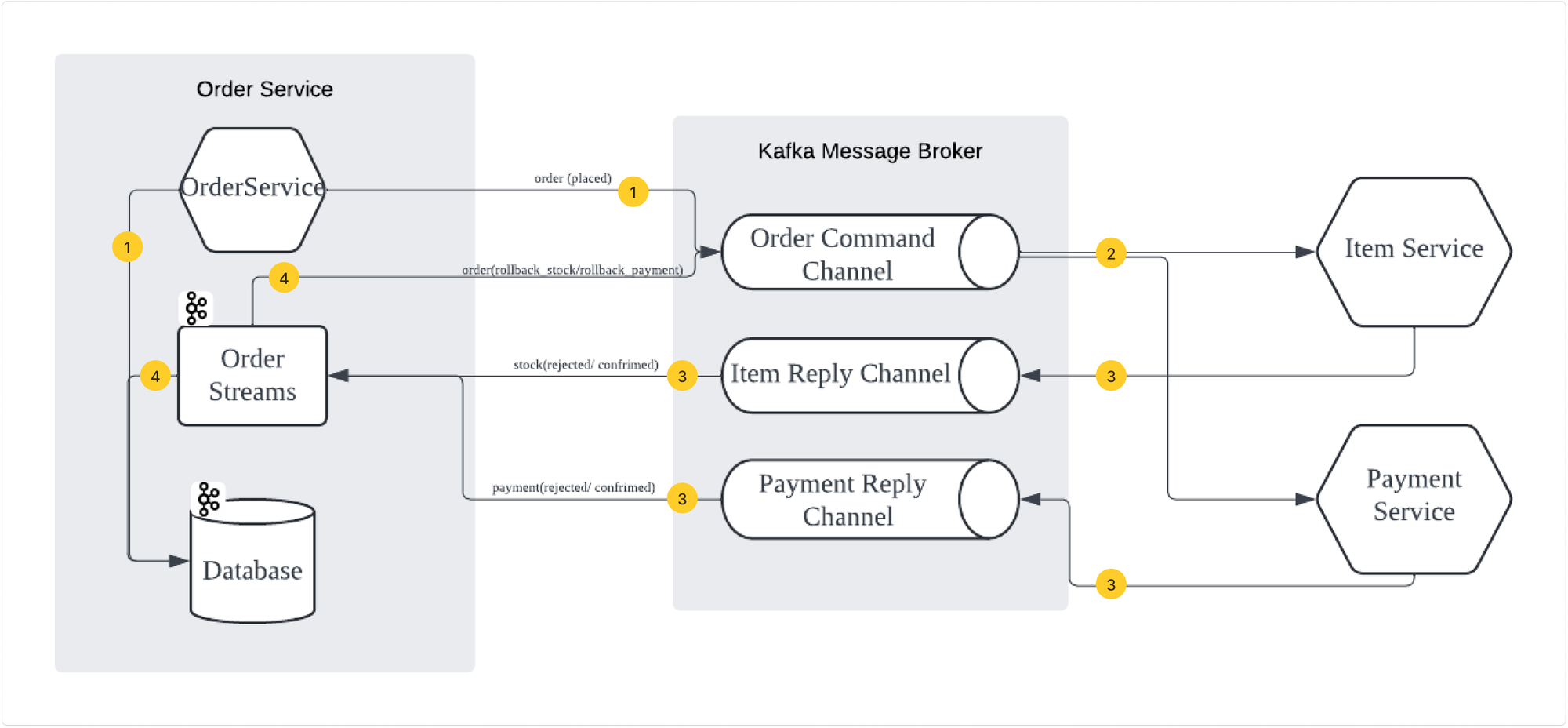
이벤트 소싱 과정
saga패턴의 오케스트레이션을 적용했다. Order MS로 주문 요청이 들어오고, Order MS는 해당 주문을 MongoDB에 Placed상태로 기록한 이후 Kafka producer를 통해 order Topic으로 해당 주문을 producing합니다. 이 후 Order Topic을 구독 하고있던 Product MS와 Payment MS에서 해당 토픽을 consume하고 각각 독립적으로 아이템 재고 업데이트와, 결제 로직을 진행합니다.
이후 Product MS와 Payment MS에서 정상적으로 처리가 됐으면 각각stock Topic과 payment Topic으로 해당 이벤트를 Accepted상태로 프로듀싱합니다. Order MS는 stock 과 payment Topic을 구독하고 있다가 해당 토픽들을 컨슘하고 카프카 스트림즈를 통해 Order Id가 같은 경우 두 토픽을 조인 합니다. 이후 두 토픽모두Accepted상태로기록돼있으면 주문이 정상적으로 처리되고, mongo DB에서 해당주문의 상태값을 CONFIRMED 상태로 기록합니다.
처음엔 카프카 스트림을 이너조인으로 진행했지만. 카프카 스트림이 일정 윈도우 시간 안에 페이먼트나 아이템중 한개의 토픽이 안넘어오면 조인을 안하고 해당 토픽을 누락시켜서 카프카스트림 키테이블에 오더 토픽을 저장하지 않아서 추후에 페이먼트 시스템이 살아나도 주문 자체가 롤백 처리가 진행 되지않는 치명적 결함이 발견됐습니다. 로그를 확인하니 이상이 발생한 오더 서비스에서 페이먼트 서비스에게 헬스 체크요청만이 지속적으로 보내지고 있었습니다.
아웃조인으로 변경 이후 페이먼트나 아이템 서비스중 하나가 다운돼도 카프카 스트림 조인 연산이 진행 되고. k테이블에 해당 토픽을 저장하기 떄문에 롤백연산이 실행됩니다. 예를 들면 페이먼트 서비스가 죽으면 아이템서비스는 재고 업데이트를 진행하고, 결제는 취소됩니다. 그리고 페이먼트 서비스가 살아나면 페이먼트 연산을 진행하지 않은 이벤트에 대응되는 재고 업데이트 이벤트들은 전부 롤백 ( 롤백 결제 및 재고 너무 밀리면 안좋음.)
그래서 서비스가 죽으면 안되기 때문에 유레카 시스템에서 쿠버네티스로 리팩토링을 진행할 예정
카프카 스트림 조인 코드
@Bean
public KStream<String, OrderKaf> stream(StreamsBuilder builder) {
Serde<String> keySerde = Serdes.String();
JsonSerde<OrderKaf> valueSerde = new JsonSerde<>(OrderKaf.class);
KStream<String, OrderKaf> paymentStream = builder
.stream(String.valueOf(PAYMENTS), Consumed.with(keySerde, valueSerde));
KStream<String, OrderKaf> stockStream = builder
.stream(String.valueOf(STOCK),Consumed.with(keySerde, valueSerde));
//join may have to be changed to outer join
//since if one of the stream is not available, the order should be rejected
KStream<String, OrderKaf> orderKStream = stockStream.outerJoin(
paymentStream,
this::confirm,
JoinWindows.ofTimeDifferenceWithNoGrace(Duration.ofSeconds(5)),
StreamJoined.with(keySerde, valueSerde, valueSerde)
);
orderKStream.to(String.valueOf(ORDERS), Produced.with(keySerde, valueSerde));
return orderKStream;
}3번 해결방안 : CQRS 패턴 적용
데이터베이스 부하 문제
저희 팀은 프로젝트에 CQRS 패턴을 적용하였습니다. CQRS 패턴을 적용하게 된 계기에 대해 먼저 말씀드리면
- 데이터베이스 연결 문제
CQRS 패턴을 적용하기 전의 구조는 5개의 서비스가 1개의 AWS RDS DB를 사용하고 있었습니다. 이렇게 모든 서비스들이 하나의 데이터베이스에만 연결되면서 Too Many Connections 문제가 발생했습니다.
MySQLNonTransientConnectionException:Too many connections
DB에 너무 많은 커넥션이 연결돼있어 커넥션이 모자라면 발생하는 문제였습니다. AWS RDS의 default 최대 커넥션 개수는 정해져 있엇고 최대 커넥션을 사용하면 그 이후에 오는 요청에 대해서는 정상적인 처리가 어려운 상태였습니다.
이를 해결하기 위한 직관적인 방법은 DB의 최대 커넥션 개수를 늘려주는 방법이었습니다. 하지만 이는 근본적인 해결 방법이 될 수 없었습니다.
- 집중적인 트래픽
위에서 말씀드렸듯이 5개의 서비스가 1개의 데이터베이스를 사용하고 있었고 API 개수가 늘어나면서 데이터베이스에 집중적인 부하가 발생하게 되었습니다.
이러한 문제를 해결하기 위해 저희 팀은 CQRS 패턴을 도입하기로 결정했습니다. 이를 통해 Read와 Write 데이터베이스를 분리하여 문제를 해결하고자 했습니다. 특히, 트래픽이 많을 것으로 예상되는 Product MS와 Order MS에 우선적으로 적용하였습니다.
CQRS 패턴 적용 이전의 구조
Order MS: 모든 정보를 MySQL에 저장하고, Command와 Query 연산도 모두 MySQL에서 처리.
Product MS: 모든 정보를 MySQL에 저장하고, Command와 Query 연산도 모두 MySQL에서 처리. 아이템 조회 시 항상 아이템과 상세정보를 조인해야 했으며,
Product 등록자와 Order 주문자를 포함한 조회는 gRPC 연산을 통해 Member 도메인의 정보를 얻어야 했음.
CQRS 패턴 적용 이후의 구조
Order MS
Write DB: Kafka의 K-Table로 대체.
Read DB: MongoDB 사용 (member 도메인의 정보를 담아 역정규화)
MySQL DB를 사용하지 않음.
Product MS:
기존 Product MS를 Command 담당의 Product MS와 Query 담당의 Search MS로 분리.
Product MS (Command): MySQL DB 사용.
Search MS (Query): MongoDB 사용. 아이템 데이터를 조회할 때, Product 도메인 이외에 Member 도메인의 정보도 필요했기에, 역정규화를 통해 하나의 Document에 모든 정보를 합쳐 MongoDB에 저장. 이로 인해 조회 시 gRPC 연산이 줄어 응답 시간이 단축되었고, Read DB에서 조인 없이도 빠른 조회가 가능하게 됨.
개선 사항 및 향후 계획
현재 구조에서는 여전히 5개의 서비스가 하나의 Write DB에 의존하고 있어 장애 발생 가능성이 존재합니다. 그러나 현재 트래픽 및 상황을 고려하여 1개의 Write DB만 사용하고 있습니다. 향후 트래픽이 더 많은 서비스를 개발할 경우, 각 서비스마다 1개 이상의 DB를 두고 Replication을 적용하거나 이벤트 소싱 방식을 도입하여 데이터베이스 장애 대응과 트래픽 분산 효과를 도모할 계획입니다.
이와 같은 CQRS 패턴 도입으로 데이터베이스 부하 문제를 효과적으로 해결하였으며, 향후 확장성 및 안정성을 더욱 강화할 수 있는 기반을 마련하였습니다.
**4번 해결방안 : Circuit Breaker : Resilience4J를 통한 장애관리
각 API 게이트웨이의 라우팅 주소들과, Grpc 서버에 Circuit Breaker를 설정해놨습니다.
resilience4j:
circuitbreaker:
configs:
default:
registerHealthIndicator: true # CircuitBreaker를 Spring Boot Health Indicator로 등록
slidingWindowSize: 10 # 슬라이딩 윈도우 크기 (10개 호출을 기준으로 실패율 계산)
failureRateThreshold: 50 # 실패율 임계값 (50% 이상일 때 CircuitBreaker 상태를 OPEN으로 변경)
slow-call-rate-threshold: 100 # 느린 호출 비율 임계값 (100%)
slow-call-duration-threshold: 6000ms # 느린 호출의 기준 시간 (6000밀리초 이상)
permittedNumberOfCallsInHalfOpenState: 3 # HALF_OPEN 상태에서 허용되는 호출 수
waitDurationInOpenState: 10s # OPEN 상태에서 HALF_OPEN 상태로 전환하기 전 대기 시간 (10초)성능 최적화를 위한 Redis 적용
읽고 쓰는 게 기존 RDBMS와 비교해서 월등하게 빠르고 대규모 백엔드 시스템에서 메모리 DB는 거의 필수적으로 사용되고 있었습니다.
하지만 트래픽이 없는 저희 시스템에서 어디에 적용시켜야 좋을지, 성능을 위해서 Redis를 바로 사용해도 되는지 두 가지 고민이 있었습니다.
Redis는 인 메모리 기반 데이터베이스라서 물리적인 메모리 이상을 사용하면 문제가 발생하고 Single Thread라 한 번에 하나의 명령만 수행이 가능하기 때문에 Redis 이상이 전체 시스템 문제를 야기할 수 있다고 생각하여 신중하게 도입을 고민했습니다. 그래서 저희는 쿼리 튜닝, 로직 개선 등을 통해서 최대한 성능을 개선 후 Redis 사용 결정을 했습니다. Redis 운영을 효율적으로 하기 위해서 복잡하지 않은 로그인 시 기한이 지난 토큰이나 로그아웃된 토큰을 블락 처리하는 블랙리스트 기능에만 적용하기로 결정했습니다.
마무리
프로젝트를 수행하면서 MSA 구조 설계에서 고려해야 할 사항들이 많았습니다. 기존에 개발해오던 MA는 개발과 관리가 용이했고 트랜잭션 처리 또한 비교적 쉬웠지만 비즈니스 로직이 복잡해지고 규모가 커지는 경우 MSA 아키텍처를 사용하는 것이 더 나은 선택이라고 느꼈습니다.
MSA 아키텍처로 설계하면서 저희 팀은 DB의 데이터 중복이나 분산 트랜잭션, 장애 추적의 어려움을 겪었습니다. 이런 어려움들을 해결하기 위한 방법들을 함께 논의하며 해결해나갔고 각 MS가 상호의존 없이 단일의 목적 기능을 수행하도록 설계하려고 노력했습니다.
