순서만 대략 정리
Q-러닝 알고리즘이 특정 조건에서 행동 값을 과대 평가하는 경향이 발생
이전엔 과대평가의 원인으로 함수 근사와 노이즈를 지목
이 논문에서는 이러한 관점을 통합하여 함수 근사의 오류 원인에 관계없이 행동 값이 부정확할 때 과대평가가 발생할 수 있음을 보여줌
학습 과정에서 가치 추정의 부정확성이 일반적인 현상임을 고려하면, 과대평가가 이전에 생각했던 것보다 더 일반적일 수 있음을 시사함
과대평가가 실제로 발생하고 대규모로 성능에 영향을 미치는지 확인하기 위해, 최근 발표된 DQN 알고리즘(Mnih et al., 2015)의 성능을 분석했고 DQN이 종종 행동 값들을 크게 과대평가한다는 것을 발견.
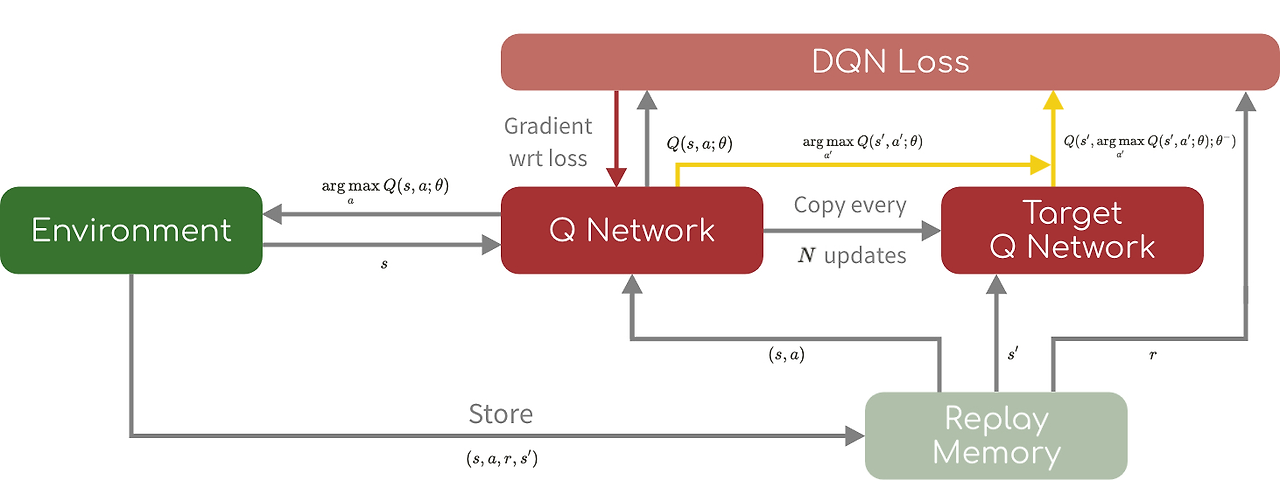
원인은 dqn에서 행동을 선택하고 평가할 때 같은 q값을 사용한다.
즉, 상태 에서의 최적 행동을 선택할 때 를 계산하는데, 이 값 자체가 선택된 행동의 가치를 평가할 때도 사용된다. 만약 이 값에 오차가 있으면, 그 오차가 다음 상태에서도 중첩되어 과대 추정이 발생할 수 있습니다. 따라서 ddqn에서는 target network를 사용하여 두가지를 사용한다. 하나는 greedy policy를 결정하는데 사용하고 나머지 하나는 그의 가치를 계산하는데 사용.
는 서로 역할을 전환하여 대칭적으로 업데이트 가능
(1) Q-Learing에서 왜 overoptimistic이 발생하는지에 대해 증명
(2) value estimates를 분석함으로써 이러한 overestimations이 일반적으로 발생하는 것을 증명
(3) Double Q-Learing은 이러한 overoptimism을 줄이는데 효과적으로 사용될 수 있음을 증명
(4) 기존 DQN 알고리즘에 추가적인 network 구조 혹은 파라미터 없이, Double DQN 이라는 새로운 아키텍쳐를 구현
(5) DDQN은 기존의 알고리즘들보다 더 좋은 policy를 찾을 수 있으며, Atari 2600 도메인에서 state-of-the-art 달성
