15-445/645 Intro to Database Systems/Fall 2022 4강을 보고 정리한 내용입니다.
링크: https://www.youtube.com/watch?v=2HtfGdsrwqA
1. Storage
1-1. Pages
1-1.1 Page Layout: log-structured
지난 강의에선 page의 layout 중 slotted pages 방식을 살펴봤다. Slotted-Page 디자인은 여러 문제가 있는데 다음과 같다.
- Fragmentation: 튜플을 삭제하는 것은 페이지 내에 공백을 남긴다. 물론 compaction을 주기적으로 수행함으로써 공백을 삭제하기도 한다.
- Useless Disk I/O: Non-volatile storage는 블럭 중심의 아키텍처 때문에 튜플을 구하기 위해 전체 블럭을 읽어야 한다.
- Random Disk I/O: 20개의 튜플을 읽기 위해 20가지 다른 장소로 점프해야 할 수 있으며, 이 과정은 매우 느리다.
이러한 문제를 해결하기 위해 생각을 전환해보자. 데이터의 생성을 하되 덮어쓰지 않는 시스템을 구현한다면 공백이 생기지 않아 fragmentation 문제를 해결할 수 있을 것이다.
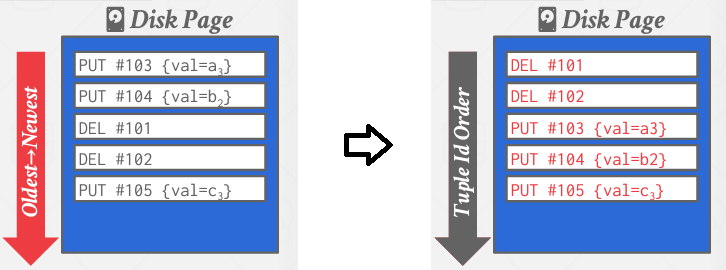
Log-structured storage 방식은 튜플을 저장하지 않음으로써 생각을 전환한다. 튜플을 저장해야하는데 튜플을 저장하지 않는다니 언뜻보면 모순같다. 하지만 log-structured storage 방식은 튜플의 변화를 담고 있는 로그 기록을 통해 간접적으로 튜플 정보를 저장한다. 구체적으로, 로그 기록에 있는 튜플의 고유 식별자를 통해 튜플을 식별한다. 아래 그림과 같이 PUT, DELETE 명령어를 통해 튜플을 저장 혹은 삭제한다.

이러한 방식으로 페이지 내에 로그 기록을 저장했을 때, 페이지가 가득찼을 때, DBMS는 디스크에 페이지를 기록하고 새로운 페이지에 정보를 저장하기 시작한다. 따라서, 디스크에 기록하는 방식이 sequential하고 디스크에 저장된 페이지를 변경할 수 없게 된다. 페이지를 변경하지 않기 때문에 random disk I/O 문제를 부분적으로 해결한다. 앞선 강의에서 하드웨어의 물리적인 제약으로 인해 random write보다 sequential write가 더 빠르다는 것을 확인했다.
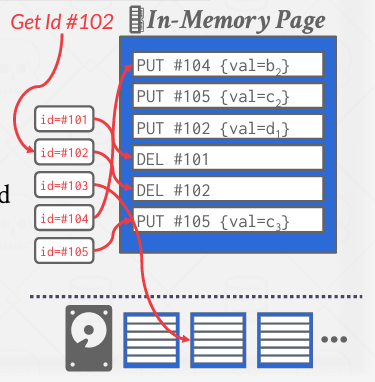
Write가 sequential하다는 것을 알았는데 그럼 이제 로그에 남아있는 기록을 어떻게 읽을지 알아본다. 특정 튜플에 대한 가장 최신 로그가 그 튜플의 현재 상태를 결정짓는다. 따라서 특정 ID의 튜플을 읽기 위해 DBMS는 해당 ID에 해당하는 최신 로그 기록을 찾는다. 튜플 ID를 찾는 데에 있어서 읽는 시간이 길어지는 random disk I/O 문제가 발생하는데 튜플 ID를 최신 로그 기록에 매핑하는 인덱스를 유지하고 관리한다면 완화할 수 있다. 만약 로그 기록이 메모리에 내에 있다면 바로 읽고 디스크에 있다면 검색한다.
튜플을 읽는 시간을 단축하는 또 다른 방법은 로그 데이터 자체를 주기적으로 압축, 즉 compaction을 수행하는 것이다. 이는 현재 시점에 불필요한 정보를 줄여 useless disk I/O를 완화시키는 의미도 있다.
동일한 튜플에 대한 로그 기록 중엔 마지막 로그 기록만이 의미가 있다. 따라서, 다음 그림과 같이 튜플 아이디 #101, #102, #103, #104, #105에 대한 가장 최신 기록만을 취합해 새로운 페이지를 만든다.
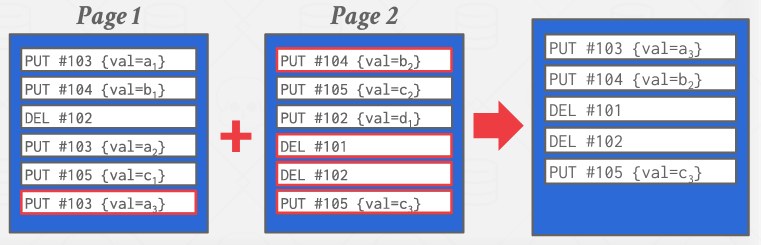
DBMS는 compaction이 완료된 페이지의 튜플 ID를 정렬하여 더 빠른 read를 가능하게 한다. 이를 Sorted String Tables(SSTables)이라고 한다.
Compaction을 수행하는 방법은 universal compaction과 level compaction 두가지가 있다. 간단히 짚어보면, universal compaction은 모든 레벨의 로그 파일을 동시에 병합하는 방식이고, level compaction은 레벨 단위로 로그 파일을 병합하는 방식이다.
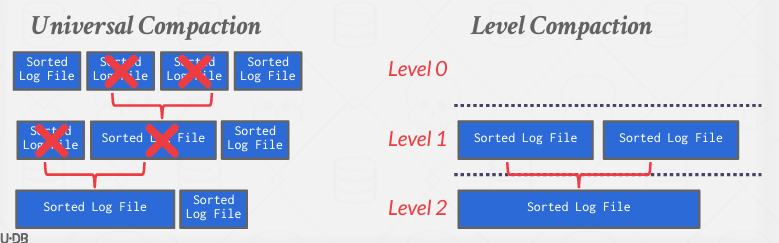
Log-structured 페이지 레이아웃도 단점이 존재하며 다음과 같다.
- write amplification: 메모리에서 쓰인 페이지를 디스크에 쓰는데, 디스크에서 페이지를 메모리에 불러와서 compaction을 진행한 후 다시 디스크에 쓰는 작업을 반복적으로 하게 된다.
- 비싼 compaction: write amplification으로 인해 많은 비용이 발생한다.
이러한 이유로 slotted 페이지 방식을 아직 log-structured 방식에 비해 많이 사용한다. 하지만 분산형 시스템과 같은 경우에 log-structured 방식은 확실한 강점이 있으므로 점점 더 많이 쓰이는 추세에 있다.
마지막으로 정리하자면, log-structured 저장 방식은 튜플을 쓰는 시간이 빠르고, 읽는데엔 상대적으로 느리다. 따라서, 튜플 ID를 최신 로그 기록에 매핑하는 인덱스를 유지, compaction을 통해 튜플을 읽는 시간을 단축한다.
1-2. Tuples
3강 Database Storage, Part1에서 튜플은 본질적으로 바이트의 시퀀스로 이러한 바이트를 해석하여 타입과 값으로 변환하는 것이 DBMS의 역할이라고 했다. 1-2.1 Data representation에서 DBMS가 타입과 값을 어떻게 바이트로 나타내는지를 살펴본다.
1-2.1 Data Representation
integers
- INTEGER, BIGINT, SMALLINT, TINYINT
- 고정된 길이
variable-precision numbers⭐
- FLOAT, REAL
- 고정된 길이
Variable-precision numbers는 정확하지 않은 변수 숫자 유형이다. 다음 그림과 같이 소수점 아래 20자리까지 시각화하여 최대의 정밀도를 구하고자하여도 하드웨어가 숫자들을 정확하게 표현하지 못한다는 것을 알 수 있다.

fixed-point precision numbers⭐
- NUMERIC, DECIMAL
- 시스템마다 다른 정밀도와 scale
대부분의 경우 variable-precision numbers가 충분하겠지만 로켓 공학과 같이 정확한 수치가 필요할 땐 fixed precision numbers를 사용한다. 이러한 데이터가 수치를 정확하게 구할 수 있는 이유는 데이터의 길이, 소수점의 위치와 같은 추가적인 메타 데이터를 거의 문자열과 같은 형식으로 저장하기 때문이다. 많은 정보를 저장해야하므로 자연스레 비용이 증가한다.
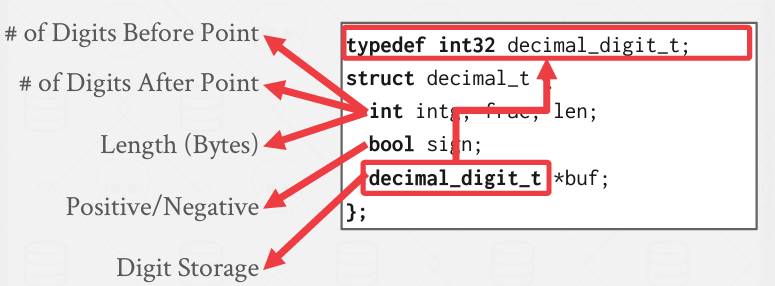
시스템마다 저장 방식이 다르다는 점을 주의하고 MySQL이 fixed-point precision 숫자를 저장하는 방식은 다음과 같다. 이는 흔히 메모리에 바이트에 따라 의미를 나누던 익숙한 방식과는 다른 접근방식이다.
variable length values
- VARCHAR, VARBINARY, TEXT, BLOB
- 임의의 길이
임의의 길이를 갖는 데이터 타입으로 주로 header과 함께 저장된다. Header에는 다음과 같은 정보가 저장된다.
- string의 길이: 다음 값이 어디에 위치하는지 찾는 과정을 용이하게 함
- checksum: 데이터가 유효한 데이터인지 확인하는 기능
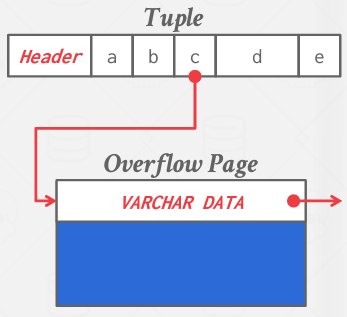
대부분의 DBMS는 페이지 크기보다 큰 튜플을 저장하지 못하게 한다. 일부 이를 허용하는 DBMS(Postgres, MySQL)는 이러한 튜플을 overflow 페이지에 따로 저장하고 튜플에 이 페이지의 위치를 저장한다.
일부 DBMS(Oracle, Microsoft)는 큰 데이터 파일을 아예 외부 파일에 저장한다. DBMS 내에 큰 공간을 차지하지 않게한다는 장점이 있지만 DBMS는 이 파일의 내용에 대한 통제권을 잃는다.
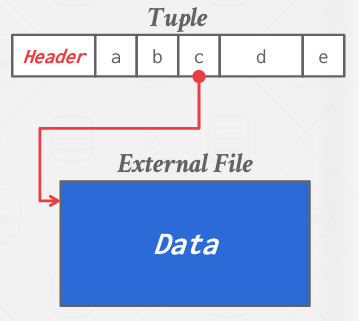
date/times
- TIME, DATE, TIMESTAMP
1-3. System Catalogs
튜플이 아닌 데이터베이스 자체에 대한 메타 데이터는 system catalog에 저장한다. 저장하는 메타 데이터는 다음과 같은 정보를 저장한다.
- 테이블, 칼럼(타입과 순서), 인덱스, 뷰
- 사용자, 권한
- 내부 통계
DBMS의 INFORMATION SCHEMA를 통해 데이터베이스에 대한 정보를 얻을 수 있다.
Q1. 현재 데이터베이스에 있는 테이블 모두 나열하시오.
# 표준 sql
SELECT *
FROM INFORMATION_SCHEMA.TABLES
WHERE table_catalog = '<db_name>';# mysql
SHOW TABLES;SHOW TABLES;결과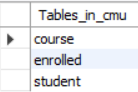
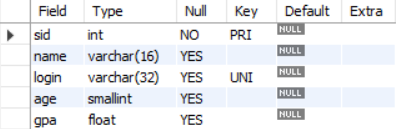
Q2. student 테이블에 대하여 자세히 알려주세요.
# 표준 sql
SELECT *
FROM INFORMATION_SCHEMA.TABLES
WHERE table_name = 'student';# mysql
DESCRIBE student;DESCRIBE student;결과