Java Collection Set
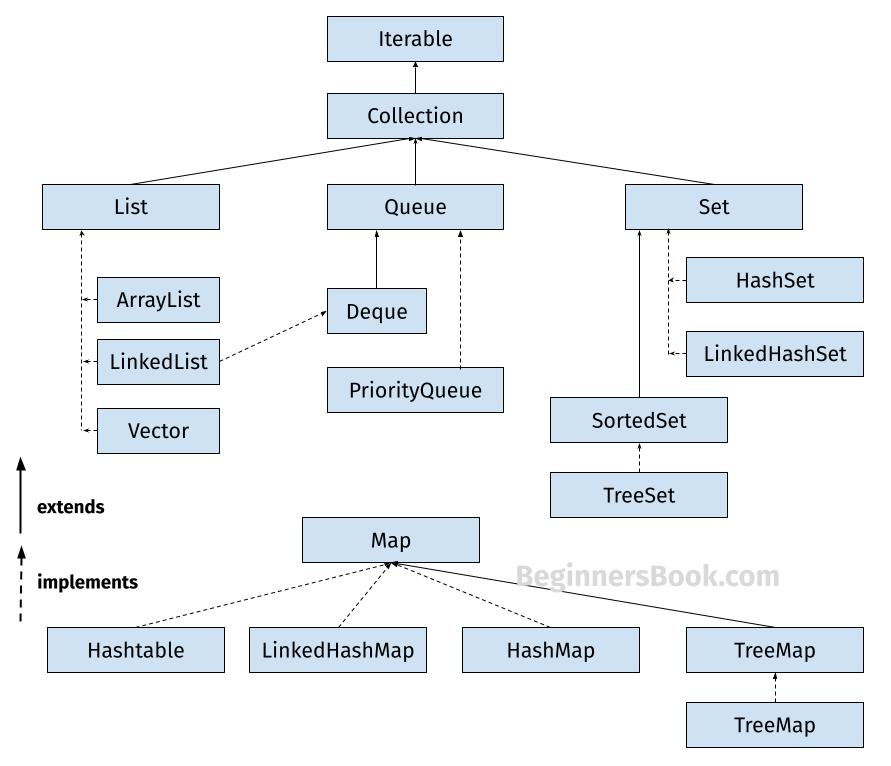
Set 인터페이스는 Collection 인터페이스를 상속받으며, 인터페이스끼리는 구현이 아닌 상속이라고 표현한다. Set은 중복을 허용하지 않는 컬렉션을 다루며, 대표적인 Set 인터페이스의 구현체로는 다음과 같은 것들이 있다:
HashSet: 순서를 보장하지 않으며 해시 테이블을 기반으로 빠른 검색을 지원한다. 중복된 값을 허용하지 않으며, 무작위 순서로 데이터를 저장한다.LinkedHashSet: 순서를 보장하며, 삽입 순서대로 데이터를 저장한다.HashSet의 특성을 그대로 유지하면서 순서가 중요한 경우 사용된다.TreeSet: 정렬된 순서대로 데이터를 저장하며, 이진 검색 트리를 기반으로 동작한다. 데이터를 자동으로 정렬해 저장하고, 범위 검색 등을 빠르게 처리할 수 있다.
HashSet
이전에 직접 구현한 MyHashSet과 거의 동일하지만, 자바 자체의 최적화 기능들이 들어가기에 약간 다르다.
LinkedHashSet
HashSet에 연결 리스트를 추가하여 요소들의 순서를 유지하려면, 요소들이 들어온 순서대로 next를 연결하는 구조를 만들면 된다.
이렇게 연결 링크를 유지해야 하므로, HashSet보다는 조금 더 무겁다. 예를 들어, 10개의 데이터를 이 Set에 추가하고, 그 저장소를 first부터 따라가면 입력 시점 기준으로 순서대로 데이터를 검색할 수 있다.
이 방식은 순서 유지가 중요한 경우에 유용하며, LinkedHashSet과 같은 자료구조에서 활용될 수 있다. HashSet은 데이터를 무작위 순서로 저장하지만, LinkedHashSet은 데이터의 삽입 순서를 기억하고 그 순서대로 데이터를 반환한다.
TreeSet
HashSet의 저장 구조는 단순히 리스트 형태로 되어 있으며, LinkedHashSet은 LinkedList로 들어온 순서대로 next 링크를 연결하여 순서를 유지한다. 반면, TreeSet은 내부 자료구조로 이진 트리(binary tree)를 채택하여, 데이터를 정렬된 순서대로 저장한다. 리스트와 달리 이진 트리는 검색 접근 시간이 O(logN)으로 더 효율적이지만, 데이터들의 순서를 값 기준으로 구현할 수 있다. Set은 리스트와 달리 데이터 순서를 보장하지 않는데, TreeSet은 이러한 단점을 극복할 수 있는 자료 구조이다.
TreeSet에 숫자형이 들어오지 않는다면
TreeSet은 기본적으로 요소들을 정렬된 순서로 유지하는 자료구조이기 때문에, 숫자형이 아닌 요소가 들어가면ClassCastException이 발생할 수 있다. 이는TreeSet이 요소들을 정렬하고 비교하기 위해compareTo()메서드나Comparator를 사용하기 때문이다. 따라서 숫자형 요소들을 다룰 때는Number클래스를 상속받은 숫자 클래스들만 사용할 수 있다. 예를 들어,java.lang.Integer,java.lang.Long,java.lang.Float,java.lang.Double,java.lang.Short,java.lang.Byte,java.math.BigInteger및java.math.BigDecimal과 같은 클래스를 사용할 수 있다.
Tree 구조
16개의 경우 단 4번의 비교 만으로 최종 노드에 도달할 수 있다. 이것을 정리하면 다음과 같다.
2개의 데이터 4개의 데이터 8개의 데이터 16개의 데이터 32개의 데이터 64개의 데이터 ...
- 2로 1번 나누기,
log2(2)=1
2로 2번 나누기,log2(4)=2
2로 3번 나누기,log2(8)=3
2로 4번 나누기,log2(16)=4
2로 5번 나누기,log2(32)=5
2로 6번 나누기,log2(64)=6
2로 10번 나누기,log2(1024)=10
Set 최적화
Collection.Set.HashSet은 우리가 직접 구현한 MyHashSetV3와 거의 유사하지만, 추가적인 최적화가 적용된다. 그 중 하나는 재해싱(rehashing)이라고 불리는 과정이다.
재해싱 (rehashing)
데이터의 양이 75% 이상이면, 배열의 크기를 2배로 증가시키고, 기존에 저장된 모든 데이터의 해시 인덱스를 새로 커진 배열에 맞춰 다시 계산한다. 이 과정은 성능 향상을 위한 중요한 최적화 기법으로, 해시 테이블의 크기를 적절히 늘려주어 충돌을 줄이고 데이터를 효율적으로 저장할 수 있게 해준다.
재해싱을 통해 HashSet은 큰 데이터셋에 대해서도 빠른 조회 성능을 유지할 수 있으며, 충돌이 너무 많이 발생할 경우 성능 저하를 방지할 수 있다.
정리
- 실무에서는
Set이 필요한 경우HashSet을 가장 많이 사용한다. 그리고 입력 순서 유지, 값 정렬의 필요에 따라서LinkedHashSet,TreeSet을 선택하면 된다. - 해시 알고리즘에 사용되는, 즉 해시 셋에 들어가는 인스턴스들은 클래스 설계시 반드시
hashCode(),equals()를 Overriding 해야한다.
