List vs Set
리스트(List)는 요소들의 순차적인 컬렉션으로, 순서를 가지며 중복을 허용한다. 반면, Set(셋)은 유일한 요소들만을 포함하는 컬렉션으로, 중복을 허용하지 않으며 순서를 보장하지 않는다. 셋은 빠른 검색의 특징을 갖고 있다.
이제 해시(Hash)의 개념을 이해하기 위해 Set을 직접 구현하면서 Hash의 개념을 도입해보겠다.
Set 직접 구현 V0
package collection.set;
import java.util.Arrays;
public class MyHashSetV0 {
private int[] elementData = new int[10];
private int size =0;
public boolean add (int value) {
if (contains(value)) {
return false;
}
elementData[size] = value;
size++;
return true;
}
public boolean contains(int value) {
for (int data : elementData) {
if (data == value) {
return true;
}
}
return false;
}
public int size() {
return size;
}
@Override
public String toString() {
return "MyHashSetV0{" +
"elementData=" + Arrays.toString(Arrays.copyOf(elementData, size)) +
", size=" + size +
'}';
}
}내부에서 배열을 사용하여 Set을 구현하고, 데이터 추가, 데이터 검색, 데이터 길이를 관리하는 기능을 만들기 위해 add, contains, size 메서드를 작성했다. 각 메서드는 다음과 같은 방식으로 동작한다.
add:contains메서드를 활용하여 먼저 내부에 동일한 요소가 존재하는지 확인한다. 만약 존재한다면false를 반환하고, 존재하지 않으면 해당value를 추가하고,size++를 통해 크기를 증가시킨다.contains: 배열을 하나하나 순회하면서 입력 인자value와 동일한 요소가 있는지 확인한다.size: 현재Set에 저장된 요소의 개수를 반환한다.
현재 contains 메서드는 배열을 순차적으로 검색하는 방식이기 때문에 빠른 조회의 장점이 부족하다. 이를 해결하기 위해 해시 알고리즘을 도입하려 한다.
해시 알고리즘의 아이디어는 들어오는 데이터가 int 타입이므로, 들어오는 데이터를 배열의 인덱스와 동일하게 매핑하는 것이다. 예를 들어, 데이터 5가 들어오면 인덱스 5에 해당하는 위치에 5를 저장하는 방식이다. 이렇게 하면, 데이터 조회가 훨씬 빠르게 이루어질 수 있다.
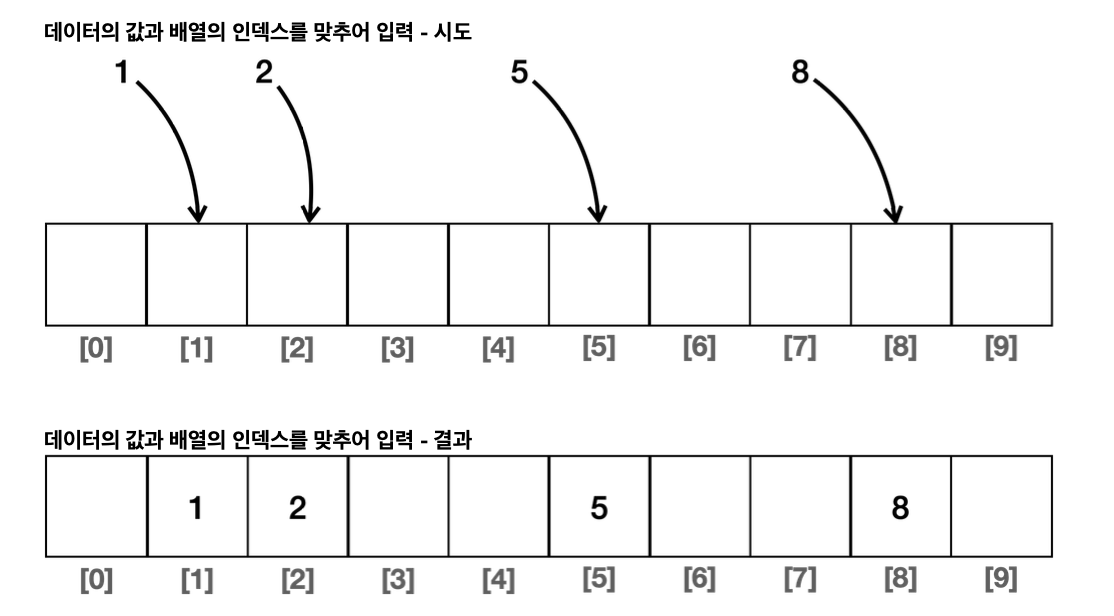 이렇게 했을 때 빠른 배열의 인덱스 주소안의 데이터를 그대로 빠르게 가져와 사용할 수 있다. 하지만 낭비되는 메모리가 생성된다. 만약 마지막 요소가 8이 아니라 99라면 우리는 배열의 크기를 미리 99로 맞추어야 하며 실제로 들어오는 데이터는 4개뿐이므로 매우 많은 메모리 공간이 낭비된다.
이렇게 했을 때 빠른 배열의 인덱스 주소안의 데이터를 그대로 빠르게 가져와 사용할 수 있다. 하지만 낭비되는 메모리가 생성된다. 만약 마지막 요소가 8이 아니라 99라면 우리는 배열의 크기를 미리 99로 맞추어야 하며 실제로 들어오는 데이터는 4개뿐이므로 매우 많은 메모리 공간이 낭비된다.

해시 알고리즘 - 나머지 연산 도입
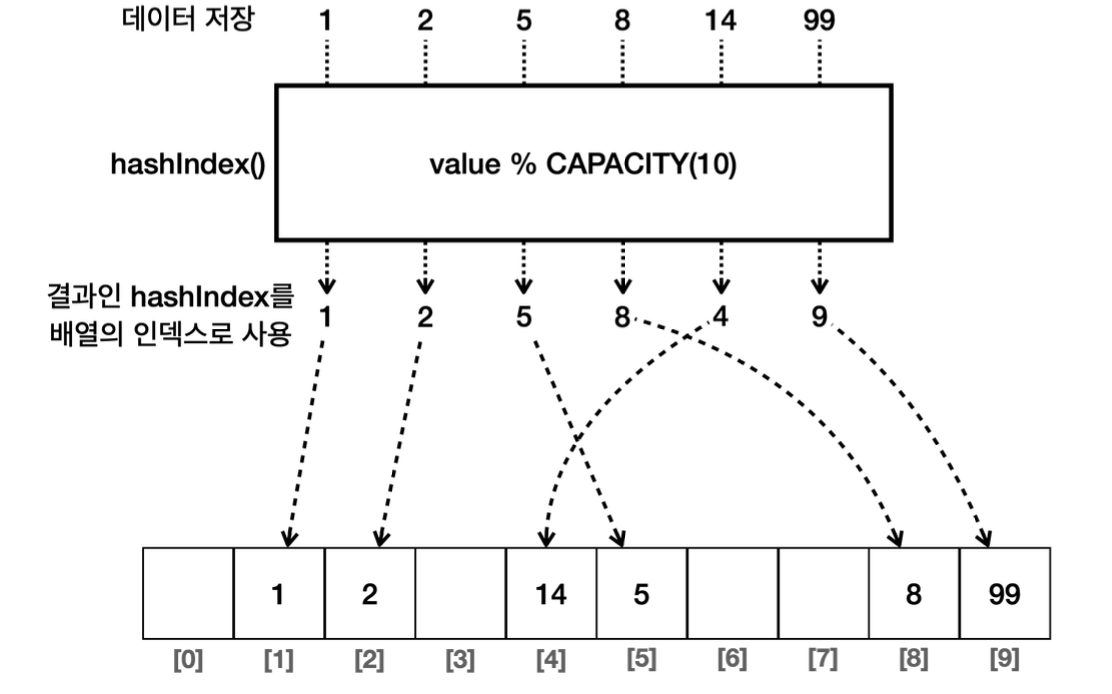
만약 입력 데이터가 1, 2, 5, 8, 14, 99와 같이 주어진다면, 0~99의 크기를 모두 확보할 필요 없이 입력 데이터의 수와 비슷한 크기의 배열을 사용할 수 있다. 이를 위해 나머지 연산(modulo)을 활용할 수 있다. 이 방법은 간단한 해시 아이디어로 널리 사용된다.
예를 들어, 저장할 수 있는 배열의 크기가 10이라고 가정할 경우, 들어오는 모든 데이터를 10으로 나누었을 때 나머지를 인덱스로 사용하여 해당 위치에 데이터를 넣는 방식이다. 이렇게 하면 배열 크기를 고정시키지 않고 데이터의 크기와 비슷한 크기로 배열을 설정할 수 있다.
즉, 나머지 연산을 활용하면 데이터를 효율적으로 저장하고, 충돌 가능성을 최소화할 수 있는 방법을 제공한다.
package collection.set;
import java.util.Arrays;
public class HashStart4 {
static final int CAPACITY = 10;
static int hashIndex(int value) {
return value % CAPACITY;
}
public static void main(String[] args) {
System.out.println("hashIndex() = " + hashIndex(1));
System.out.println("hashIndex() = " + hashIndex(2));
System.out.println("hashIndex() = " + hashIndex(5));
System.out.println("hashIndex() = " + hashIndex(8));
System.out.println("hashIndex() = " + hashIndex(14));
System.out.println("hashIndex() = " + hashIndex(99));
Integer[] inputArray = new Integer[CAPACITY];
add(inputArray ,1);
add(inputArray ,2);
add(inputArray ,5);
add(inputArray ,8);
add(inputArray ,14);
add(inputArray ,99);
System.out.println("inputArray = " + Arrays.toString(inputArray));
int searchValue = 14;
int hashIndex = hashIndex(searchValue);
Integer result = inputArray[hashIndex];
System.out.println(result);
}
private static void add(Integer[] inputArray, int value) {
int hashIndex = hashIndex(value);
inputArray[hashIndex] = value;
}
}
한계 - 해시 충돌
만약 들어오는 데이터가 9와 99일 경우, 이 두 데이터는 10으로 나눈 나머지가 모두 9가 된다. 즉, 위의 코드에서는 하나의 인덱스에 두 개 이상의 데이터가 배치되게 된다.
해결 방법
-
배열 크기(CAPACITY)를 100으로 설정하는 방법이 가장 직관적이다. 이 방법은 각 데이터의 나머지 값을 그대로 인덱스로 사용하고, 충돌이 발생하지 않도록 할 수 있다. 그러나, 이는 사실상 기존 방식과 동일하게 100개의 공간을 미리 확보하는 방식이라 메모리 낭비가 발생할 수 있다.
-
인덱스에 겹치는 수들을 모두 넣고 나서 두 번째 검색을 시도하는 방법도 있다. 이를 통해 충돌이 발생한 경우, 해당 인덱스에 데이터를 이어서 추가하고, 나중에 검색 시 그 위치를 다시 확인할 수 있다. 이 방법은 속도를 약간 희생하더라도 메모리 공간을 절약할 수 있는 방법이다.
이렇게 되면 가장 빠른 속도를 제공하는 방법은 아니지만, 메모리 공간 이슈를 해결하는 데 더 효율적일 수 있다.
package collection.set;
import java.util.Arrays;
import java.util.LinkedList;
public class HashStart5 {
static final int CAPACITY = 10;
static int hashIndex(int value) {
return value % CAPACITY;
}
public static void main(String[] args) {
LinkedList<Integer>[] buckets = new LinkedList[CAPACITY];
for (int i = 0; i < CAPACITY; i++) {
buckets[i] = new LinkedList<>();
}
System.out.println("buckets = " + Arrays.toString(buckets));
add(buckets, 1);
add(buckets, 2);
add(buckets, 5);
add(buckets, 8);
add(buckets, 14);
add(buckets, 99);
add(buckets, 9);
System.out.println("buckets = " + Arrays.toString(buckets));
int searchValue = 9;
boolean contains = contains(buckets, searchValue);
System.out.println("buckets.contains(" + searchValue + ") = " + contains);
}
private static void add(LinkedList<Integer>[] buckets, int value) {
int hashIndex = hashIndex(value);
LinkedList<Integer> bucket = buckets[hashIndex]; // O(1)
if (!bucket.contains(value)) {
bucket.add(value);
}
}
private static boolean contains(LinkedList<Integer>[] buckets, int searchValue) {
int hashIndex = hashIndex(searchValue);
LinkedList<Integer> bucket = buckets[hashIndex];
return bucket.contains(searchValue); //O(n)
}
}
LinkedList<Integer>[] buckets = new LinkedList[CAPACITY];: 타입변수가 Integer인 LinkedList가 들어오는 배열을 선언한다.add(LinkedList<Integer>[] buckets, int value): LinkedList가 담긴 배열을 받고 추가할 int value를 받는다. hashIndex메서드를 통해 들어갈 index자리를 구한다. 배열의 요소인 buckets의 인덱스=hashIndex를 가져와서 .contains를 통해 중복검사를 진행하고 중복이 아니라면 LinkedList에 value를 추가한다.contains(LinkedList<Integer>[] buckets, int searchValue): add와 동일하게 LinkedList가 담긴 배열을 받고 찾을 searchValue를 받는다. 검색을 위해 hashIndex메서드를 통해 검색할 Index를 구하고 해당 인덱스로 접근하여 LinkedList.contains로 배열 내부의 리스트안에 searchValue가 존재하는지 return한다.
해시 인덱스 충돌 확률
해시 충돌이 발생할 확률은 입력하는 데이터의 수와 배열의 크기와 관련이 있다. 통계적으로, 입력한 데이터의 수가 배열의 크기의 75% 이하일 경우, 해시 인덱스는 자주 충돌하지 않는다. 이 비율은 해시 테이블의 효율성을 높이기 위한 일반적인 규칙이다.
해시 개념은 실제 다른 코딩에서도 많이 사용되는 기본적인 메커니즘이므로, 이를 이해하고 잘 활용할 수 있어야 한다. 예를 들어, 자주 사용하는 자료구조인 HashMap이나 HashSet은 내부적으로 해시 함수를 사용하여 데이터를 빠르게 조회하고 관리한다.
따라서 해시 개념을 익숙하게 다루는 것이 다양한 문제를 효율적으로 해결하는 데 도움이 될 것이다.
