
Iterable, Iterator
데이터를 차례대로 접근하여 처리하는 방법을 순회라고 한다. 다양한 자료구조에서 순회의 방식은 제각각이다. 예를 들어, ArrayList는 index를 0부터 size-1까지 차례로 증가시키면서 순회할 수 있으며, LinkedList의 경우 node.next를 사용해 node.next가 null일 때까지 순회할 수 있다. 순회의 목적은 동일하지만, 각 자료구조마다 순회 방법은 다르다.
자료구조의 구현과 관계없이 모든 자료구조를 동일한 방법으로 순회할 수 있는 일관적인 방법이 있다면, 개발자들은 훨씬 더 편리하게 작업할 수 있을 것이다. 자바는 이러한 문제를 해결하기 위해 Iterable과 Iterator 인터페이스를 제공한다.
// Iterable
public interface Iterable<T> {
Iterator<T> iterator();
}
// Iterator
public interface Iterator<E> {
boolean hasNext();
E next();
}Iterable은 단순히 Iterator 반복자를 반환하는 인터페이스이다. Iterator는 hasNext()와 next() 메서드를 제공한다. hasNext()는 다음 요소가 있는지 확인하고, next()는 다음 요소를 반환한다.
보통은 자료구조 클래스에서 implements Iterable을 선언하고, Iterable의 메서드인 iterator()를 오버라이딩하여 구현한다. 이 오버라이딩된 iterator() 메서드는 Custom Iterator 인스턴스를 반환한다.
결국 myArray.iterator()를 사용하려면 myArray가 Iterable을 구현해야 하며, 오버라이딩을 통해 iterator() 메서드를 작성해야 한다. 이 iterator() 메서드는 myArray 자료구조에 맞는 customIterator를 반환하며, customIterator는 hasNext()와 next() 메서드를 구현해야 하므로 Iterator 인터페이스를 통해 동작한다.
import java.util.Iterator;
// Iterable 인터페이스 구현
class MyArray implements Iterable<Integer> {
private Integer[] array;
private int size;
public MyArray(int capacity) {
array = new Integer[capacity];
size = 0;
}
// add 메서드로 데이터 추가
public void add(Integer value) {
if (size < array.length) {
array[size++] = value;
}
}
// iterator() 메서드 오버라이드
@Override
public Iterator<Integer> iterator() {
return new CustomIterator();
}
// Custom Iterator 구현
private class CustomIterator implements Iterator<Integer> {
private int index = 0;
@Override
public boolean hasNext() {
return index < size;
}
@Override
public Integer next() {
if (!hasNext()) {
throw new IllegalStateException("No more elements");
}
return array[index++];
}
}
}
// 사용 예시
public class Main {
public static void main(String[] args) {
MyArray myArray = new MyArray(5);
myArray.add(1);
myArray.add(2);
myArray.add(3);
myArray.add(4);
myArray.add(5);
// for-each문을 사용하여 순회
for (Integer value : myArray)
우리가 사용할 자료구조는 Iterable을 구현해야하고, 구현을 위해 iterator() 오버라이드 메서드를 작성해야한다. 이 메서드의 반환 타입은 Iterator이므로 Iterator를 구현한 커스텀 클래스를 설계하고 이 클래스를 통해 객체를 생성해서 iterator() 오버라이드 메서드의 반환으로 주어야 한다.
향상된 for문
JetBrains IntelliJ에서 매우 유용한 기능 중 하나는 iter + Enter 키 조합이다. 이 기능은 향상된 for문을 바로 IDE에서 생성해주어 개발자가 더 효율적으로 코드를 작성할 수 있도록 돕는다.
향상된 for문을 사용하려면 해당 자료 구조가 Iterable 인터페이스를 구현해야 한다.
특정 자료 구조가 Iterable과 Iterator를 구현했다면, 개발자는 hasNext()와 next() 메서드를 직접 호출하거나 for-each(향상된 for문)을 사용하여 간편하게 순회할 수 있다. 이렇게 하면 순회 로직을 간단하게 처리할 수 있으며, 반복적인 코드 작성이 불필요하다.
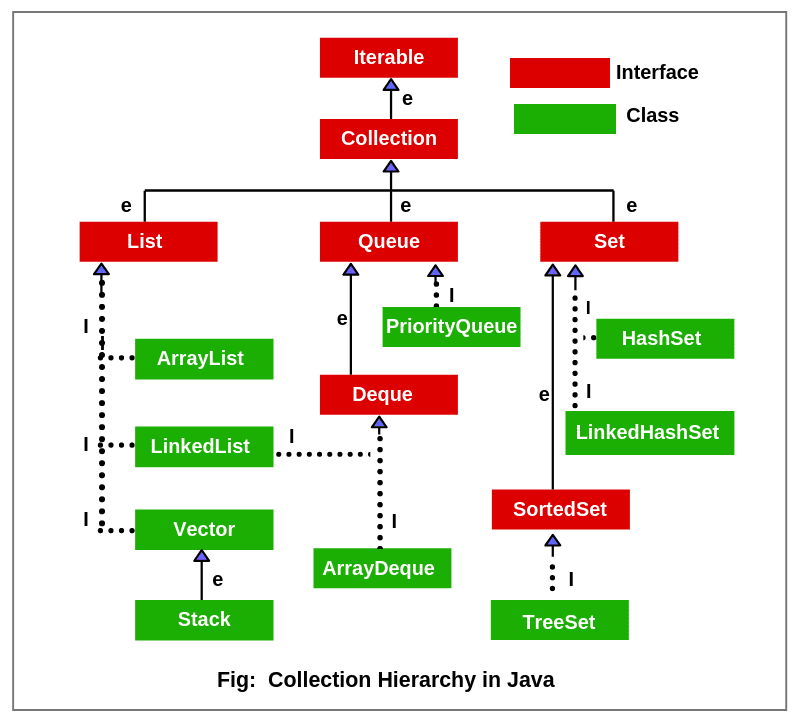 위와 계층도를 보면 자바의
위와 계층도를 보면 자바의 Collection 인터페이스는 Iterable의 구현이므로 모든 Collection 아래의 자료구조들은 iterable하며, 따라서 향상된 for문을 사용할 수 있다.
즉, List, Set, Queue 등 Collection의 구현체들은 Iterable을 구현하고 있기 때문에, for-each 문을 통해 해당 자료 구조들을 간편하게 순회할 수 있다. 이를 통해 반복문을 더욱 직관적으로 사용하고, 코드의 가독성을 높일 수 있다.
Iterable 디자인 패턴
Iterable 디자인 패턴은 컬렉션의 내부 표현 방식을 노출시키지 않으면서도 그 안의 각 요소에 순차적으로 접근할 수 있게 해준다. 이 패턴은 컬렉션을 순회하는 방법을 통일시키고, 코드의 복잡성을 줄이며 재사용성을 높이는 데 도움을 준다.
package collection.Iterable;
import java.util.*;
public class JavaIterableMain {
public static void main(String[] args) {
List<Integer> list = new ArrayList<>();
list.add(1);
list.add(2);
list.add(3);
printAll(list.iterator());
forEach(list);
HashSet<Integer> set = new HashSet<>();
set.add(1);
set.add(2);
set.add(3);
printAll(set.iterator());
forEach(set);
}
private static void forEach(Iterable<Integer> collection) {
for (Integer integer : collection) {
System.out.println(integer);
}
}
private static void printAll(Iterator<Integer> iterator) {
System.out.println("iterator = " + iterator.getClass());
while (iterator.hasNext()) {
System.out.println(iterator.next());
}
}
}
main 실행문 안에 ArrayList와 HashSet 두 가지 자료구조가 존재한다. printAll() 메서드는 Iterator를 인자로 받아 해당 자료구조의 모든 요소를 순회하며 출력하는 기능을 수행한다. List이든 HashSet이든, 두 자료구조는 Iterable 인터페이스를 구현하고 있기 때문에 iterator() 메서드를 사용할 수 있다. 따라서 Iterator를 매개변수로 받는 printAll() 메서드를 통해 다양한 자료구조에 대해 동일한 방식으로 순회할 수 있다.
Iterable 디자인 패턴 덕분에 우리는 printAll이라는 하나의 메서드로 여러 자료구조의 순회를 처리할 수 있게 되며, 이를 통해 코드의 일관성 및 재사용성을 높일 수 있다.
Comparable, Comparator
자바가 기본으로 제공하는 Integer, String과 같은 객체를 제외하고, 직접 만든 객체들을 Collection 자료구조에서 정렬하려면 비교 규칙을 정의해야 한다. 이를 위해 Comparable 인터페이스를 구현하거나, Comparator를 사용하여 정렬 기준을 설정할 수 있다. Comparable은 객체 자체에 정렬 규칙을 정의하는 방식이고, Comparator는 외부에서 비교 규칙을 정의할 수 있는 방법이다.
public interface Comparable<T> {
public int compareTo(T o)
}Comparable은 compareTo()를 구현하도록 한다. compareTo는 자신과 인수(객체)를 비교한다.
package collection.compare;
public class MyUser implements Comparable<MyUser>{
private String id;
private int age;
public MyUser(String id, int age) {
this.id = id;
this.age = age;
}
public String getId() {
return id;
}
public int getAge() {
return age;
}
@Override
public String toString() {
return "MyUser{" +
"id='" + id + '\'' +
", age=" + age +
'}';
}
@Override
public int compareTo(MyUser o) {
return this.age < o.age ? -1 : (this.age == o.age ? 0 : 1);
}
}
MyUser는 Comparable 인터페이스를 구현한다. Comparable에서 요구하는 compareTo 메서드를 구현해야 하며, 그 안에서 객체의 비교 규칙을 정의한다. compareTo 메서드의 반환 값은 다음과 같이 작동한다.
-1일 경우 두 객체의 위치가 변경되지 않는다.0일 경우 두 객체의 위치가 그대로 유지된다.1일 경우 두 객체의 위치가 바뀐다.
예를 들어, age 값이 10, 20, 14, 5일 경우, 정렬이 진행되는 과정은 다음과 같다:
- 10과 20을 비교하면
-1이 반환되어 위치가 유지된다. - 20과 14를 비교하면
1이 반환되어 위치가 바뀐다. - 10과 14를 비교하면
1이 반환되어 위치가 유지된다. - 20과 5를 비교하면
1이 반환되어 위치가 바뀐다.
이와 같이 compareTo 메서드에서 변화에 대한 규칙만 정의하면, 자바의 최적화된 정렬 알고리즘이 이를 활용하여 빠르게 정렬을 수행한다.
Comparator 사용법
package collection.compare;
import java.util.Comparator;
public class IdComparator implements Comparator<MyUser> {
@Override
public int compare(MyUser o1, MyUser o2) {
return o1.getId().compareTo(o2.getId());
}
}
Comparator 인터페이스를 구현한 idComparator 클래스에서 compare 메서드를 오버라이드하여 두 객체를 비교한다. compareTo와 달리 compare는 두 개의 객체를 인자로 받으며, 첫 번째 객체와 두 번째 객체를 비교한다. 이때, 결과적으로 String의 compareTo 메서드를 사용하여 사전순으로 문자열을 비교하고, -1, 0, 1 중 하나를 반환한다.
-1은 첫 번째 객체가 두 번째 객체보다 작다는 의미이고,0은 두 객체가 같다는 의미,1은 첫 번째 객체가 두 번째 객체보다 크다는 의미이다.
따라서, compare 메서드에서 1을 반환하면 두 객체의 순서가 변경된다.
또한, String 클래스는 Comparable을 구현하고 있기 때문에 compareTo를 사용하여 문자열을 비교할 수 있다.
TreeSet의 경우
Tree의 경우 이진 탐색 트리를 사용한다. 데이터의 정렬은 저장시부터 이미 결정되어있는데, 그러므로 TreeSet은 생성시점에 Comparator를 전달하거나 TreeSet 제네릭에 직접 만든 클래스를 부여하려면 해당 클래스에 Comparable을 구현해야한다.
package collection.compare;
import java.util.TreeSet;
public class SortMain5 {
public static void main(String[] args) {
MyUser myUser1 = new MyUser("a", 30);
MyUser myUser2 = new MyUser("b", 20);
MyUser myUser3 = new MyUser("c", 10);
TreeSet<MyUser> treeSet1 = new TreeSet<>();
treeSet1.add(myUser1);
treeSet1.add(myUser2);
treeSet1.add(myUser3);
System.out.println("Comparable 기본 정렬");
System.out.println(treeSet1);
TreeSet<MyUser> treeSet2 = new TreeSet<>(new IdComparator());
treeSet2.add(myUser1);
treeSet2.add(myUser2);
treeSet2.add(myUser3);
System.out.println("id 정렬");
System.out.println(treeSet2);
}
}
정렬 정리
자바의 정렬 알고리즘은 매우 복잡하고 완성형에 가까운 수준으로 최적화되어 있으므로, 이를 개선하려는 시도는 굳이 할 필요가 없다. 자바는 개발자가 복잡한 정렬 알고리즘에 신경쓰지 않도록 하고, 정렬 기준만 간단히 변경할 수 있도록 Comparable과 Comparator 인터페이스를 통해 정렬의 기준을 추상화했다.
객체의 정렬이 필요한 경우, Comparable을 사용하여 기본적인 자연 순서를 제공할 수 있다. 만약 자연 순서 외에 다른 정렬 기준이 필요하다면, Comparator를 활용하여 커스텀한 정렬 기준을 제공하면 된다.
Collection 마무리
Collection utils
- Collections.max(list)
- Collections.min(list)
- Collections.shuffle(list)
- Collections.sort(list)
- Collections.reverse(list)
기능은 바로 파악이 될테니 이런 것이 있구나 하고 잘 알고 있자.
Of
List.of, Set.of, Map.of으로 해당 자료구조들을 생성할 수 있었다. .of로 편리하게 컬렉션을 생성할 수 있다. 하지만 이렇게 생성한 컬렉션은 불변이므로 변경이 불가능하다. 변경 메서드 호출시 예외가 터진다.
자료구조 선택가이드
순서가 중요하고 중복이 허용되는 경우 List 인터페이스를 사용하고, 일반적으로는 ArrayList, 추가/삭제 작업이 앞쪽에서 매우 빈번하고 데이터가 매우 클 때만 LinkedList를 적용하자.
중복을 허용하지 않고 순서가 중요하지 않을 경우 HashSet 순서를 고려해야할 경우 Linked, Tree를 활용
요소를 키-값 쌍으로 저장하려면 HashMap 순서를 고려해야할 경우 Linked, Tree를 활용
요소를 처리하기 전에 보관하는 경우는 ArrayDeque를 사용하자
방금 적은 일반적인 경우가 바로 실무에서 대부분 사용하는 경우이다.
