스프링 탄생 비화
옛날 옛적 자바 진영에서는 EJB(Enterprise Java Beans)가 탄생하며 자바 표준으로 자리 잡았다. 많은 기업과 프로젝트에서 EJB를 채택했지만, 이 기술은 여러 문제를 안고 있었다. 예를 들어, EJB의 EntityBean은 ORM 기술 관점에서 부족했으며, 기술 자체가 지나치게 무겁고 느렸고, 개발자들은 EJB의 요구사항에 맞춰 코드를 작성해야 하는 탓에 자바의 객체지향 프로그래밍을 충분히 활용할 수 없었다.
결과적으로 많은 자바 개발자들이 EJB 지옥에 빠져 힘든 시간을 보내야 했다. 2002년, 이런 상황에서 로드 존슨은 EJB 없이도 고품질의 확장 가능한 애플리케이션 개발이 가능하다는 사실을 증명하기 위해 약 30,000라인의 예제 코드를 선보였다. 이 코드에는 현재 스프링의 핵심 개념과 기반 코드가 포함되어 있었다.
이 코드를 기반으로 한 책이 출간된 후, 유겐 휠러와 얀 카로프는 로드 존슨에게 해당 코드를 기반으로 오픈소스 프로젝트를 만들 것을 제안했고, 이로 인해 스프링(Spring)이 탄생하게 되었다.
Spring이라는 이름은 EJB의 지옥, 즉 혹독한 겨울을 나고 새로운 봄이 찾아왔다 해서 Spring으로 지어졌다.
스프링?
나는 스프링 개발자다. 그렇다면 스프링 개발자란 무엇인가? 그리고 스프링은 도대체 무엇을 의미하는 걸까?
스프링은 DI 컨테이너 기술을 의미하는가? 아니면 스프링 프레임워크 자체를 뜻하는가? 혹은 스프링 부트를 포함한 방대한 스프링 생태계를 의미하는가? 심지어 스프링 공식 사이트조차 스프링이라는 단어의 정의가 명확하지 않다고 말한다.
현재, 스프링이라는 용어는 주로 넓은 스프링 생태계 전체를 포괄하는 개념으로 사용된다. 이는 스프링 프레임워크, 스프링 부트, 그리고 이를 기반으로 한 다양한 프로젝트와 기술들을 모두 포함하는 의미로 확장되었다
스프링 핵심 컨셉
스프링의 시작은 로드 존슨의 전설적인 3만 줄 분량의 코드로, 그 안에는 스프링의 핵심 컨셉이 담겨 있다. 이후 스프링은 계속해서 기능을 추가하며 더 커져 나갔지만, 본질적인 핵심은 변하지 않았다.
- 그렇다면, 그 3만 줄 코드의 핵심 컨셉은 무엇일까?
- 웹 애플리케이션을 만들고 데이터베이스 접근을 편리하게 해주는 기술일까?
- 혹은 웹 서버를 자동으로 띄워주는 기능이 주된 목적일까?
이러한 것들은 단지 결과일 뿐, 스프링의 진짜 핵심은 객체 지향 언어가 가진 강력한 특징을 살려 좋은 객체 지향 애플리케이션을 개발할 수 있게 도와주는 프레임워크라는 점이다.
객체지향
이미 자바를 배울 때 학습했던 개념이지만, 다시 학습해보니 느껴지는 부분이 달랐다. 간단한 다형적 설계를 실습으로 여러 번 해본 것, 코딩 테스트를 객체지향적으로 풀어본 것 등 짧은 경험들을 통해 객체지향에 대한 이해가 조금씩 깊어졌다. 이런 경험을 하고 다시 객체지향 설계와 스프링을 학습하니, 이전보다 훨씬 더 와닿는 느낌을 받았다.
다형성(polymorphism)
 USB 2.0 충전 케이블은 많은 기업에서 제조하여 판매하고 있으며, 이는 USB 인터페이스를 다양한 회사들이 구현하여 소비자에게 제공하는 방식이다. 소비자는 원하는 구현체를 선택해 구매하며, 어떤 USB 케이블을 구매하더라도 컴퓨터나 충전기의 USB 포트에 잘 맞아 동작한다.
USB 2.0 충전 케이블은 많은 기업에서 제조하여 판매하고 있으며, 이는 USB 인터페이스를 다양한 회사들이 구현하여 소비자에게 제공하는 방식이다. 소비자는 원하는 구현체를 선택해 구매하며, 어떤 USB 케이블을 구매하더라도 컴퓨터나 충전기의 USB 포트에 잘 맞아 동작한다.
무언가의 장점을 제대로 이해하려면, 그것이 없을 때의 불편함을 느껴보면 장점을 이해할 수 있다다. 예를 들어, 만약 각 충전 케이블마다 고유의 충전 어댑터가 필요하다면, 우리는 매번 충전 케이블 + 충전 어댑터를 함께 구매해야 할 것이다. 반면, 현재는 하나의 충전 어댑터로 고장난 케이블만 교체하여 다시 사용할 수 있다. 만약 모든 휴대폰 기종마다 고유한 충전기를 사용해야 한다면, 회사 옆자리 동료의 충전기를 빌리는 일도 불가능했을 것이다.
이 원리는 코드 작성에도 적용된다. 다형성을 이용한 인터페이스 기반 설계, 구현체 교체, 오버라이딩, 제네릭 같은 개념을 활용하면, 일체형 PC처럼 단단히 결합된 코드 대신, 조립식 PC처럼 유연하고 모듈화된 코드를 작성할 수 있다. 이렇게 작성된 코드는 유지보수와 확장이 쉬워지고, 코드의 재사용성이 극대화된다.
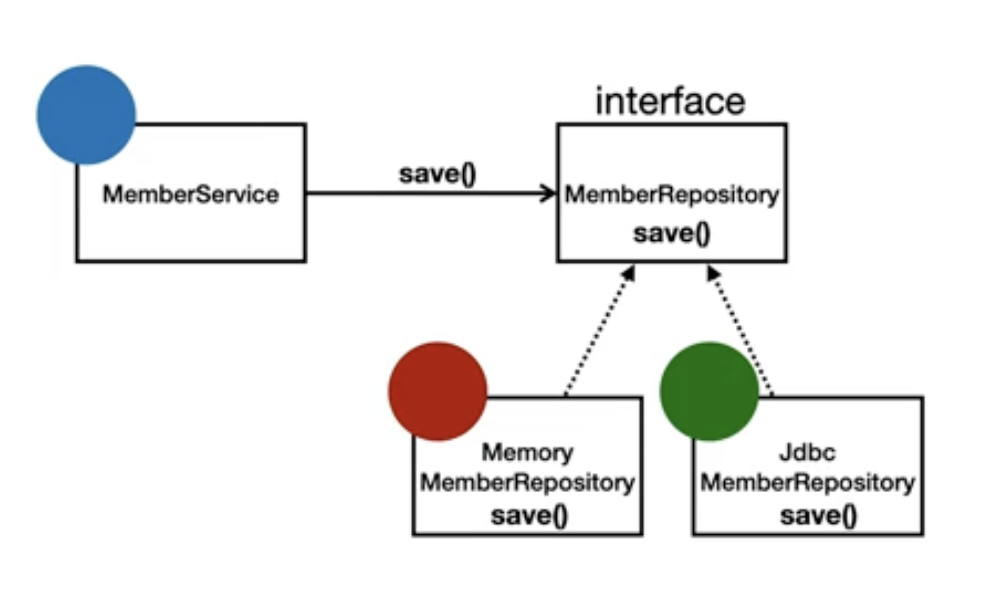 스프링 부트 실습에서 작성했던 구조 또한 다형성의 장점을 잘 보여준다. 초기에는 MemoryRepository를 사용해 프로토타입으로 개발을 진행했고, 이후 JdbcRepository를 구현하여 교체했을 때, 스프링 빈에 등록된 MemoryRepository를 JdbcRepository로 바꿔주기만 하면 작업이 끝났다.
스프링 부트 실습에서 작성했던 구조 또한 다형성의 장점을 잘 보여준다. 초기에는 MemoryRepository를 사용해 프로토타입으로 개발을 진행했고, 이후 JdbcRepository를 구현하여 교체했을 때, 스프링 빈에 등록된 MemoryRepository를 JdbcRepository로 바꿔주기만 하면 작업이 끝났다.
많은 다른 클래스에서 이미 리포지토리 기능을 사용하고 있었음에도, 인터페이스를 통해 의존성을 주입받았기 때문에 전혀 문제가 발생하지 않았다. 이것이 바로 다형성의 강점으로, 코드의 유연성과 확장성을 극대화하는 객체 지향의 핵심 원리 중 하나다.
SOLID
SRP (Single Responsibility) 단일 책임 원칙
구글에서 SRP(Single Responsibility Principle)를 검색하면 대부분의 기술 블로그는 "하나의 모듈이 하나의 책임을 가져야 한다"고 설명을 시작한다. 그러나 이러한 해석은 로버트 마틴이 강조한 SRP의 본질을 제대로 전달하지 못하고 있다.
로버트 마틴은 SOLID 원칙 중에서도 특히 단일 책임 원칙(SRP)이 가장 오해받는 원칙이라고 지적했다. SRP를 단순히 "하나의 모듈이 하나의 책임을 가져야 한다"는 모호한 규칙으로 이해해서는 안 된다.
대신, "모듈이 변경되는 이유가 한 가지여야 한다"는 것으로 해석해야 한다. 여기서 "변경의 이유가 한 가지"란, 해당 모듈이 여러 대상(Actor)이나 책임을 가지면 안 되며, 오직 하나의 Actor에 대해서만 책임을 져야 함을 의미한다. 즉, 하나의 모듈이 다양한 요구사항에 의해 변경될 가능성을 최소화해야 한다는 것이 SRP의 핵심이다.
출처: https://mangkyu.tistory.com/194 [MangKyu's Diary:티스토리]
UserService 클래스에서 AddUser 메서드를 구현할 때, 내부 로직에 유저의 패스워드를 암호화하는 부분이 존재한다고 가정해보자. 이 암호화 로직을 AddUser 내부에 직접 작성할 수도 있지만, 암호화 로직만을 담당하는 별도의 메서드나 클래스로 분리할 수도 있다.
SRP(Single Responsibility Principle)를 적용하려면, 암호화 로직은 반드시 분리되어야 한다. 만약 암호화 로직이 AddUser 내부에 포함되어 있다면, 암호화 방식에 변경 요구가 생길 때 AddUser 내부를 수정해야 한다. 그러나 AddUser의 책임은 "유저를 데이터베이스에 추가"하는 것이므로, 암호화 로직 수정은 AddUser의 본래 책임과는 무관하다. 암호화 로직이 EncrytPassword()라는 메서드로 분리되어 있다면, 변경 요구는 AddUser가 아닌 EncrytPassword로 전달되므로 책임의 명확한 분리가 이루어진다.
SRP를 지켜야 하는 또 다른 이유는, 암호화 로직이 AddUser 내부에 존재할 경우, AddUser의 다른 코드에서도 암호화 로직을 재사용할 가능성이 있다는 점이다. 이 경우, 암호화 로직 수정 시 AddUser의 여러 부분까지 수정해야 하는 문제가 발생할 수 있다. 반면, 암호화 로직을 추상화(따로 분리)하면, AddUser는 수정 없이 변경 사항에 대응할 수 있다. 이것이 바로 SRP의 핵심이자 존재 이유다. SRP를 통해 변경의 이유를 하나로 제한하고, 유지보수성과 확장성을 높일 수 있다.
OCP(Open/closed Principle) 개방 폐쇄 원칙
SOLID 원칙 중에서 가장 중요한 원칙은 OCP(Open-Closed Principle, 개방-폐쇄 원칙)이다. 이 원칙은 SRP와 마찬가지로 추상화에 의존해야 한다는 점에서 동일하다. 잘 알려진 OCP의 정의는 "확장에는 열려 있고, 변경에는 닫혀 있어야 한다"이다.
하지만 이 정의에는 모순이 있다. 확장 자체가 변경을 수반하기 때문에, 단순히 이 한 문장만으로 OCP를 이해하기는 어렵다. OCP는 다형성을 활용한 인터페이스 설계와 구현 클래스의 오버라이딩을 통해 확장하기 쉬운 코드를 작성하는 것을 의미하며, 이는 객체지향 프로그래밍의 본질이다.
예를 들어, 쓰던 USB 충전 케이블이 고장났을 때, 충전 케이블만 교체하면 되지만, 충전 바디까지 바꾸어야 한다면 이는 확장 시 변경이 발생하는 사례이다. 반대로 충전 바디가 USB 표준 규격을 따른다면, 다른 회사의 USB 충전 케이블을 구매해 연결만 하면 끝난다. 이는 확장(케이블 교체)이 일어나도 변경(충전 바디 교체)이 발생하지 않는 경우로, OCP 원칙이 잘 지켜진 사례다.
결론적으로, 확장성이 좋다는 것은 확장 시 발생하는 변경이 최소화됨을 의미한다. 따라서 더 나은 확장성을 추구할수록 OCP 원칙을 더 잘 준수하는 것이 된다. 프로그래밍에서 개방-폐쇄 원칙을 지키기 위해서는 확장 시 발생하는 변경 부분을 최소화하는 설계를 목표로 해야 한다.
LSP (Liskov Substitution Principle) 리스코프 치환 원칙
public interface MemberRepository {
void save(Member member);
Member findById(Long memberId);
}위와 같은 인터페이스가 존재할 때, 이를 구현하는 클래스에서는 save() 메서드를 작성해야 한다. 일반적으로 우리는 save() 메서드의 기능을 "인자로 전달된 member를 저장하는 것"이라고 이해한다. 그러나 만약 save() 메서드 내부 로직을 저장이 아니라 삭제 기능으로 작성하더라도, 컴퓨터는 이를 문법적으로 문제 삼지 않고 컴파일할 것이다.
여기에서 LSP(Liskov Substitution Principle, 리스코프 치환 원칙)이 중요해진다. LSP는 "해당 객체를 사용하는 클라이언트는 상위 타입이 하위 타입으로 변경되더라도, 차이점을 인식하지 못한 채 상위 타입의 퍼블릭 인터페이스를 통해 하위 타입을 사용할 수 있어야 한다"는 원칙을 의미한다.
즉, save() 메서드는 '저장' 기능에 맞게 구현해야 한다는 것이다. save()라는 이름과 상위 타입의 의미에 부합하는 기능을 구현해야만, 클라이언트가 이를 예상대로 사용할 수 있다. 이는 객체지향 설계에서 하위 클래스가 상위 클래스의 행동 규약을 깨지 않고 일관성을 유지하는 데 핵심적인 원칙이다.
ISP (Interface segregation principle) 인터페이스 분리 원칙
인터페이스를 잘 분리하라는 뜻은, 하나의 인터페이스에 너무 많은 책임을 담지 말고, 기능별로 나누어 구성하라는 것이다. 예를 들어, 자동차 인터페이스에 액셀 기능과 정비 기능을 모두 포함하는 대신, 운전 기능 관련 인터페이스와 정비 기능 관련 인터페이스로 나누어 설계해야 한다.
이처럼 인터페이스를 분리하면, 특정 기능을 필요로 하는 클래스는 해당 기능만을 구현하면 되므로 불필요한 의존성이 줄어든다. 이는 인터페이스 분리 원칙(ISP, Interface Segregation Principle)의 핵심으로, 코드의 유연성과 유지보수성을 높이는 데 중요한 역할을 한다.
DIP (Dependency Inversion Principle) 의존 역전 원칙
public class MemberServiceImpl implements MemberService{
private final MemberRepository memberRepository = new MemoryMemberRepository();
// private final MemoryMemberRepository memberRepository = new MemoryMemberRepository();
@Override
public void join(Member member) {
memberRepository.save(member);
}
@Override
public Member findMember(Long memberId) {
return memberRepository.findById(memberId);
}
}MemberServiceImpl에서 MemoryMemberRepository를 MemberRepository 타입으로 사용하는 것은 추상화에 의존하는 설계의 예시이다. 이는 변경 가능성과 확장성을 높이는 객체 지향의 중요한 원칙을 따르는 것이다.
만약 MemoryMemberRepository 타입으로 직접 사용한다면, 실행에는 문제가 없겠지만, 이후 XxxMemberRepository와 같은 새로운 구현체가 추가되었을 때, 기존 코드를 수정해야 하는 상황이 발생할 수 있다. 반면, MemberRepository 인터페이스를 기준으로 설계하면, 어떤 구현체가 추가되더라도 수정 없이 새로운 구현체를 사용할 수 있다.
인간은 "인간은 2족보행을 한다"는 추상적인 개념을 인식하고 있기 때문에, 홍길동씨가 걷는다는 사실을 특별히 신기하게 여기지 않는다. 하지만, 추상화 없이 홍길동씨만 알고 있다면, 김철수씨가 2족보행을 한다는 사실은 새로운 정보처럼 여겨질 것이다.
추상화를 통해 "인간은 2족보행을 한다"는 공통적인 특성을 알고 있다면, 홍길동이든 김철수든 그들의 행동은 자연스럽게 이해될 것이다.
코딩에서도 이 원칙이 동일하게 적용된다.
MemberRepository memberRepository = new MemoryMemberRepository();는 MemberRepository라는 인터페이스 아래에서 MemoryMemberRepository를 사용하는 것이다. 이는 MemberRepository에 정의된 공통 기능만 활용하겠다는 의미로, 코드의 유연성을 높인다.
반대로, MemoryMemberRepository 타입으로 직접 사용한다면, 설계가 특정 구현체에 종속되며 추상화의 장점을 잃게 된다. 결과적으로, 새로운 구현체를 추가하거나 변경 사항이 발생했을 때 기존 코드를 수정해야 하는 일이 많아진다.
추상화를 통해 우리는 구체적인 구현에 종속되지 않고, 인터페이스의 범주 안에서 코드를 설계할 수 있다. 이는 객체 지향의 기본 원칙을 따르는 것으로, 확장성과 유지보수성을 높여주는 설계 방식이다. MemberRepository라는 인터페이스를 사용하면, 새로운 구현체를 추가해도 기존 코드는 수정 없이 동작할 수 있다. 이러한 설계는 변화에 유연하게 대응할 수 있는 코드를 만드는 데 핵심적이다.
