JPQL 경로 표현식
JPQL에서 경로 표현식은 자바의 문법을 활용하듯 .(점)을 찍어 객체 그래프를 탐색하는 것을 말한다.
select m.username from Member m
join m.team t
join m.orders o
where t.name위에서 경로 표현식은 m.username, m.team, m.orders에 해당한다. 짧게 가독성을 주기 위해 alias를 활용하는 것이 일반적이다. m, t, o는 이에 해당한다.
m.username의 경우 상태 필드를 나타내며, 연관필드 접근을 위해서도 동일하게 m.team, m.orders을 사용한다.
상태 필드와 달리 연관필드는 묵시적 내부 조인이 발생한다.
묵시적 조인
묵시적 조인에 대비되어 명시적 조인이 존재하는데, 예시로 바로 파악해보도록 하자.
1. 명시적 조인
select m from Member m join m.team t
2. 묵시적 조인(무조건 내부 조인)
select m.team from Member m1의 경우 jpql로도 sql을 바로 알아볼 수 있는 join문이다. 반면 2의 경우 사실 jpql만 보고는 sql의 어떤 쿼리가 나갈지 jpa에 능숙하지 않다면 추상적이라 복잡하게 느껴질 수있다.
2의 경우또한 하나의 쿼리로 team을 모두 가져오는 방법이지만 2.는 1과 달리 명시적으로 join이 작성되지 않았기에 직관적으로 이것이 join을 일으키는지 알기가 힘들다.
2.에 대해서 조인이 나가는 것을 확인하려면 Member가 가진 team객체가 연관 필드임을 알아야한다. 그러한 확인 절차가 직관적이지 않기에 인식문제가 발생하게 된다.
묵시적 조인은 사용하지 않는다.
묵시적 조인을 사용하는 jpql은 언뜻보면 자바 개발자 입장에서 편리한 듯 보이나 실무에서는 유용한 방식으로 채택될 수 없다. JOIN의 사용은 매우 예민한 문제중에 하나인데, 결국 자바 개발자의 편의를 위해 튜닝의 관점을 매우 복잡하고 불편하게 만드는 일이 묵시적 조인의 남발이다.
RDB의 문법과 객체지향의 문법에서 사항마다 다르게 판단해야할 문제이지만 JOIN이 다뤄지는 부분에서는 절대적으로 RDB의 관점에서 바라봐줘야 한다. 그러한 의미에서 JOIN을 사용하는 기능에서 JOIN이 사용된다는 명시적인 표현이 들어가는 것이 성능 튜닝에 있어 매우 중요한 요소가 될 수 있다.
즉 select m.team from Member m과 같은 표현보다는 무조건 sql처럼 select m from Member m join m.team t과 같은 표현으로 조인이 일어나는 상황을 한눈에 보이도록 해야한다.
Fetch join
fetch join은 실무에서 정말 중요한 기술이다. 매우 간단하게 적용할 수 있으면서도 튜닝의 관점에서 매우 효과적인 개선을 이루어낸다.
fetch join은 sql에는 없는 문법으로 jpql에서 성능 최적화를 위해 제공하는 기능이다.
단순한 join jpql의 경우에 N+1문제가 발생하는데 예시를 보며 이해해보자.
@Entity
public class Member {
@Id
private Long id;
private String name;
@ManyToOne
private Team team;
}try {
Team team1 = new Team();
team1.setName("팀A");
em.persist(team1);
Team team2 = new Team();
team2.setName("팀B");
em.persist(team2);
Member member1 = new Member();
member1.setUsername("회원1");
member1.setTeam(team1);
em.persist(member1);
Member member2 = new Member();
member2.setUsername("회원2");
member2.setTeam(team2);
em.persist(member2);
Member member3 = new Member();
member3.setUsername("회원3");
member3.setTeam(team2);
em.persist(member3);
em.flush();
em.clear();
List<Member> resultList = em.createQuery("select m from Member m", Member.class).getResultList();
System.out.println("resultList = " + resultList);
tx.commit();
} catch (Exception e) {
tx.rollback();
e.printStackTrace();
} finally {
em.close();
}
emf.close();
}위 jpql 결과는 다음과 같다.
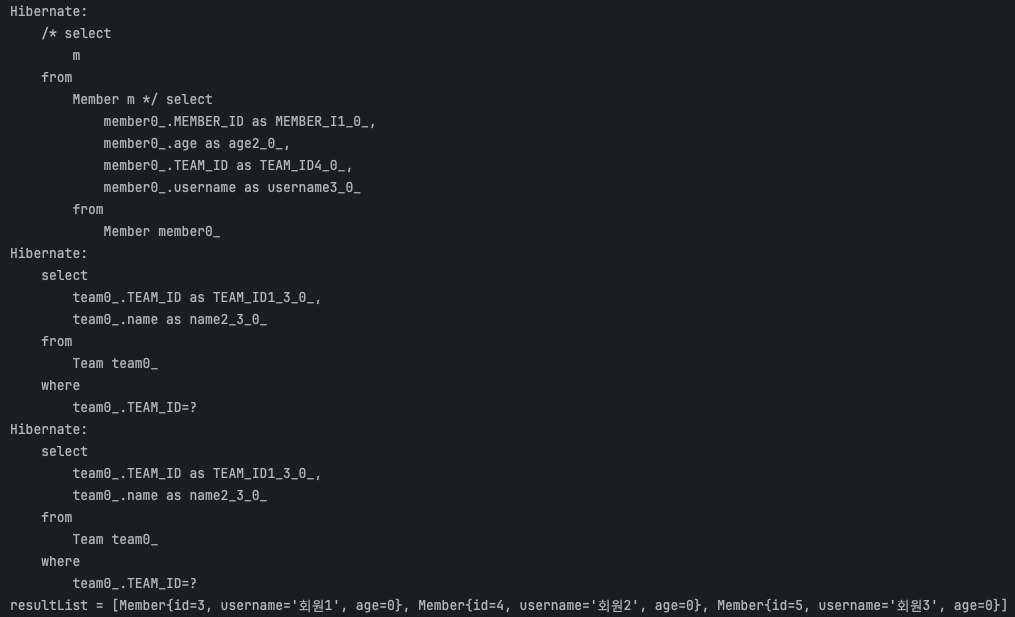 총 3번의 쿼리가 나갔다. 처음에 멤버를 조회했을 때 연관된 team까지 모두 조회되었기 때문이다. 즉시로딩이 된 것이다.
총 3번의 쿼리가 나갔다. 처음에 멤버를 조회했을 때 연관된 team까지 모두 조회되었기 때문이다. 즉시로딩이 된 것이다.
@Entity
public class Member {
@Id
private Long id;
private String name;
@ManyToOne(fetch = FetchType.LAZY)
private Team team;
}우리는 연관필드에 대해 "LAZY를 사용하자"라는 내용을 기억하고 있다. 이를 통해 그물망처럼 딸려나오게 되는 N+1문제의 비효율을 막을 수 있었다.
이렇게 다시 main을 실행하면
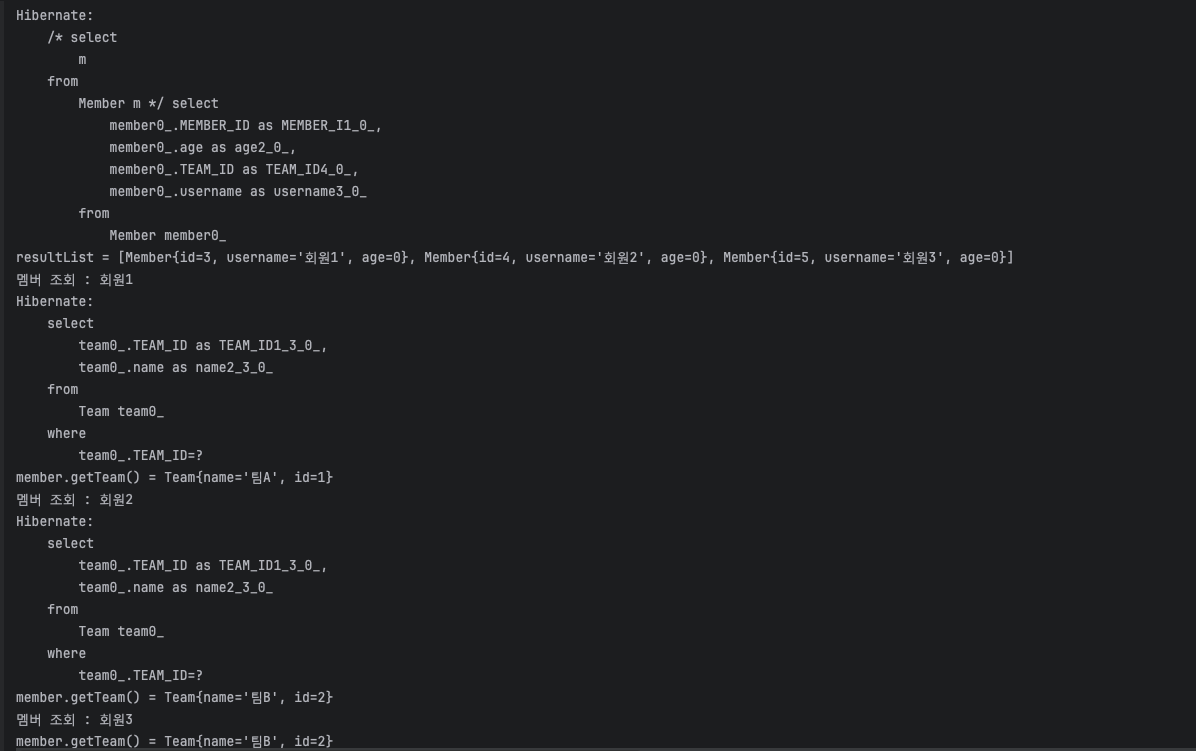 Member 조회 후 조회를 시도할 때 해당 Team이 영속성 컨텍스트에 없다면 DB에 쿼리를 날려 Team을 가져온다.
Member 조회 후 조회를 시도할 때 해당 Team이 영속성 컨텍스트에 없다면 DB에 쿼리를 날려 Team을 가져온다.
LAZY의 단점은 연관 필드인 Team객체를 가져올 때마다 하나의 Member 엔티티마다 하나의 쿼리가 나간다는 것이다. 만약 어떠한 기능에서 Member를 전체조회하고 전체 조회한 Member에 대해서 하나하나 연관된 Team을 가져와야 하는 로직이라면 이럴때만 EAGER의 로직을 쓰고 싶을 것이다. 그렇다고 Entity를 수정해서 EAGER로 만들수도 없는 노릇이다.
이럴때 사용가능한 것이 fetch join이다.
그냥 JOIN 하면 안되나?
em.createQuery("select m from Member m join m.team t", Member.class)이렇게 가져오면 즉시로딩처럼 되지 않을까 싶지만 그렇지 않다. 지연로딩 설정때문에 단순한 join은 묵살당한다. 마치 "join을 하긴했지만 일단 너가 부른건 Member니까 team을 부를때 쿼리를 날려줄게"와 같은 메세지를 jpa가 우리에게 준다고 보면 된다.
EAGER 세팅은 항상 대형 김치찌개를 준다면 fetch join은 개인마다 원하는 만큼 푹 퍼서 가져올 수 있는 것이다.
select m from Member m join fetch m.team t위의 jpql의 경우 Member 엔티티(연관필드 LAZY 설정)들을 모두 조회하면서 team도 같이 가져오는 것이다.
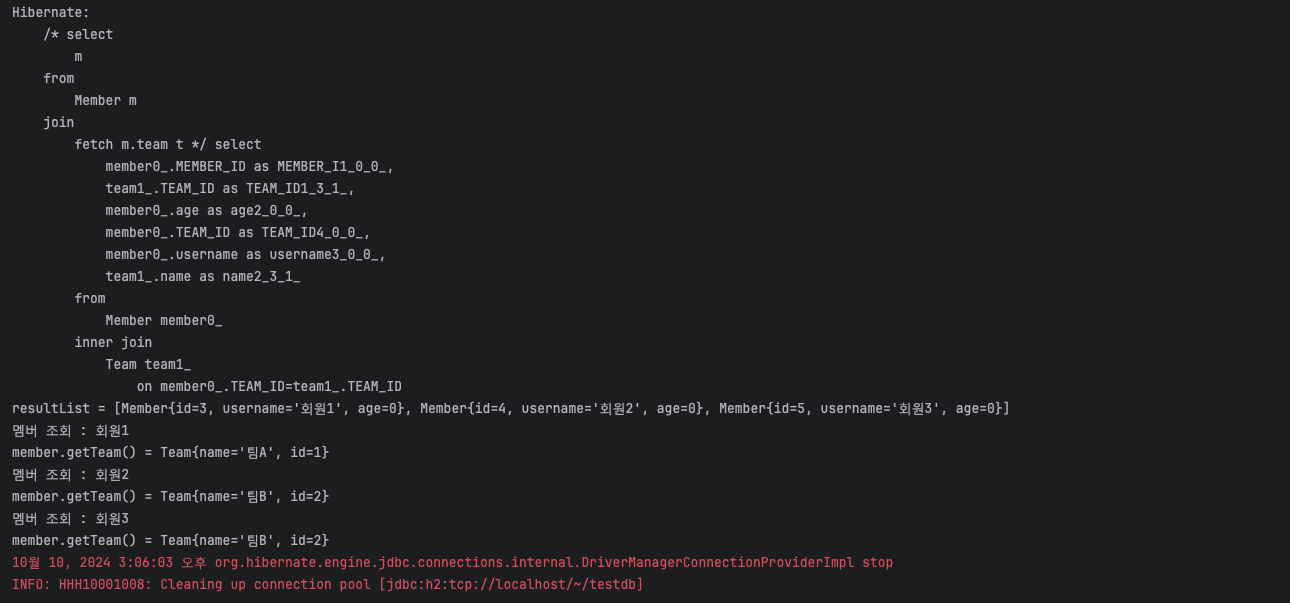 LAZY이지만 Team이 이미 Member 조회 시점에 영속성 컨텍스트에 들어와 있기에 쿼리를 날리지 않고 Member의 연관 team을 바로 사용할 수 있도록 최적화된 것이다.
LAZY이지만 Team이 이미 Member 조회 시점에 영속성 컨텍스트에 들어와 있기에 쿼리를 날리지 않고 Member의 연관 team을 바로 사용할 수 있도록 최적화된 것이다.
일대다, collection fetch join
양방향 매핑에 대해 Team에서 member를 조회하는 방식에서는 fetch join이 어떻게 사용될 수 있는지 알아보자.
select t from Team t
- Team만 우선 조회됨
- Team에서 Member 리스트 조회시 team_id에 해당하는 Member 조회 쿼리 나감
select t from Team t join (fetch) t.members
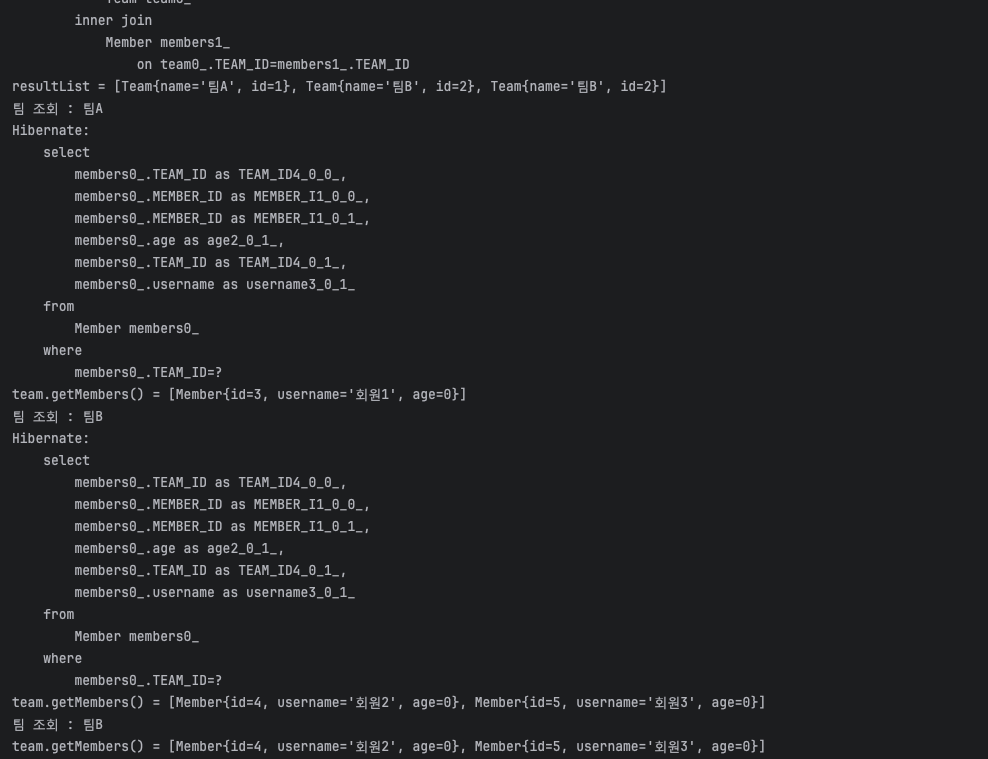 일반 join시에 특이한 현상이 발생한다.
일반 join시에 특이한 현상이 발생한다.
Team B의 경우 Member 두명이 이에 해당하는데 두번의 중복된 결과가 나타나는 것이다. 이러한 이유는
Member를 조회할 때랑 달리 join에 의해 Team에 대해 inner join으로 Member가 붙게 된다.
Team이 1이고 Member가 N이므로 DB에서는 당연히 Member를 기준으로 행이 생성된다. 즉
- member1 TeamA
- member2 TeamB
- member3 TeamB
으로 db에서 먼저 join이 되고 3개의 데이터가 그대로 날아오게 되는 것이다. 이가 문제가 되는 이유는
결국 영속성 컨텍스트에서는 위의 3개의 행에 대해서List<Team>으로 받게 되기 때문에 TeamB가 중복되어 들어오게 되는 것이다.
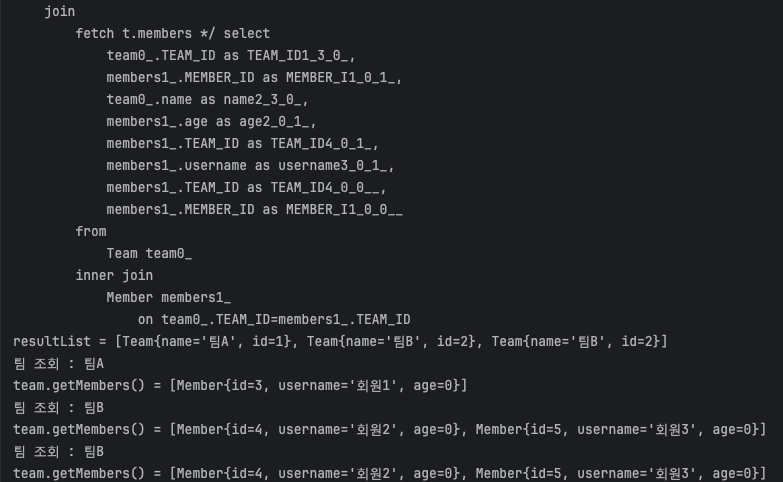
fetch join을 사용하더라도 이 중복 문제는 피할 수 없다. fetch join은 단순히 처음 조회시 join을 통해 뭉텅이로 가져와줄 뿐이기 때문이다.
DISTINCT
sql의 distinct는 완전히 중복된 결과를 제거한다. 이를 활용하면 될까 싶지만 결국 db에서는 join을 하더라도 같은 team이지만 Member들이 달라 중복으로 여기지 않는다.
JPQL의 DISTINCT는 그래서 두 가지 기능을 제공한다.
1. SQL에 DISTINCT를 추가
2. 애플리케이션에서 엔티티 중복 제거
List<Team> resultList = em.createQuery("select distinct t from Team t join fetch t.members", Team.class).getResultList();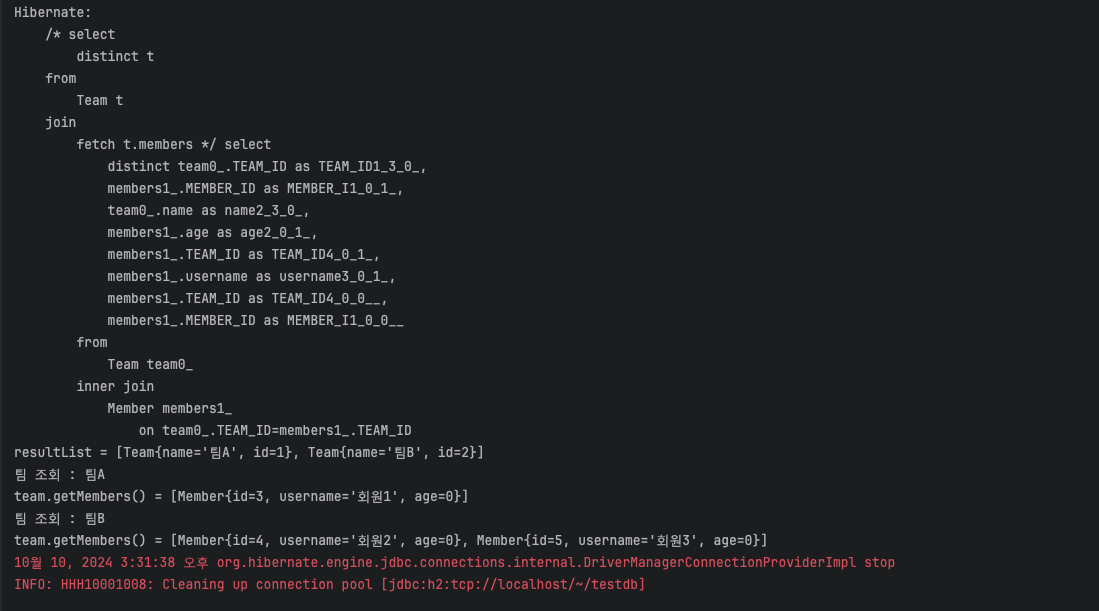 팀B에 대한 중복이 사라진 모습을 볼 수 있다.
팀B에 대한 중복이 사라진 모습을 볼 수 있다.
하이버네이트6 부터는 distinct를 쓰지 않더라도 중복이 제거된다고 한다.(위에 열심히 공부한 보람이 사라진다.)
fetch join의 한계
패치 조인 대상에는 별칭을 줄 수 없다.
사실 하이버네이트 기준으로는 별칭을 줄 수 있지만...
alias를 준다는 것은 이를 통해 좀 더 필터링을 한다던지 추가적인 조작을 할 것이라는 것인데, 이런 방식의 접근은 지양해야한다.
위에서 TeamB의 members에는 두 회원 엔티티가 들어있었다. 이를 추가적인 필터링을 통해 한명만 있게한다던지 할 경우 TeamB에 대한 일관성이 파괴된다. 영속성 컨텍스트 안에서 TeamB가 존재하는데 members의 size가 1인 경우도 2인 경우도 3인 경우도 99인 경우도 존재할 경우 진짜 TeamB는 무엇인가에 대한 일관성이 파괴되기 때문에 패치조인에 대한 필터링은 하지말아야하고 그렇기에 alias 사용을 하지 않는 것이다.
둘 이상의 컬렉션은 패치조인 불가
위에서 일대다의 경우 패치조인시 문제점을 알아보았고 DISTINCT로 해결된다는 것도 보았다. 해결과정에서 예시는 연관필드(N, 컬렉션)가 하나인 경우에 대해 실험해보았었고 DISTINCT로 해결했었다. 그런데 이런 필드가 두 개이상이고 이들을 패치조인으로 해결하는 것은 사실상 불가능하다.
1:N 문제도 데이터 뻥튀기 때문에 DISTINCT로 겨우 해결했는데 만약 두 개이상이라면 1:N:N...이 되버린다. 이럴경우 단순히 DISTINCT로 해결할 수도 없고 어떻게 어떻게 해결한다해도 이 구조 자체를 유지하는 것은 굉장히 복잡할 것이고 문제가 생기기 매우 쉬울 것이기에 이러한 접근방향은 애초에 포기하는 것이 옳다.
컬렉션 패치 조인시 PAGING API 사용 불가
컬렉션 패치 조인의 문제를 해결했던 공간은 DB가 아닌 어플리케이션에서 중복을 제거해냈다. PAGING API는 결국 DB에서 조치가 이루어지는 과정인데 데이터 뻥튀기가 되고 중복이 제거되지 않은 시점에 PAGING을 한다는 것은 PAGING이 아니라 카오스일 것이다. 의도한 PAGING이 완성될 수 없다.
패치 조인 정리
결국 여러 테이블을 조인해서 엔티티가 가진 모양이 아닌 전혀 다른 결과를 내야한다면 일반 조인을 사용하고 필요한 데이터들만 조회해서 DTO로 반환하는 것이 효과적일 것이다.
EAGER가 필요한 상황이지만 EAGER가 너무 글로벌하게 적용되니 현재 사용처에서만 최적화를 위해 EAGER를 쓰고 싶을 때 패치 조인을 사용하도록 한다.
벌크 연산
만약 수만 종류의 재고 데이터가 있고 이 재고들은 각각의 가격을 가진다. 재고가 10개 미만인 레코드들에 대해 모든 상품 가격을 10% 세일해주려면 어떤 아이디어가 존재할까?
먼저 변경감지를 활용한다고 생각해보자. 100건의 변경 감지에 대해 100번의 UPDATE 쿼리가 실행되므로 굉장히 많은 쿼리량이 될 것임을 알 수 있다.
쿼리 한번으로 이러한 목적을 수행하기 위해 executeUpdate()를 활용한 update jpql을 작성할 수 있다.
String qlString = "update Product p " +
"set p.price = p.price * 1.1 " +
"where p.stockAmount < :stockAmount";
int resultCount = em.createQuery(qlString)
.setParameter("stockAmount", 10)
.executeUpdate();벌크 연산은 영속성 컨텍스트를 무시하고 DB에 직접 쿼리한다. 그러므로 벌크 연산 수행후 연산 결과를 조회하더라도 영속성 컨텍스트에 같은 식별자로 존재하는 엔티티들이 벌크 연산 전 상태로 유지되고 있다면 벌크 연산 후 결과를 반영한 엔티티가 보이지 않을 것이다.
그러므로 벌크 연산 후에는 영속성 컨텍스트를 초기화하여 재조회시 DB에서 다시 조회하게끔 만들어야 한다.
