모니터링 툴
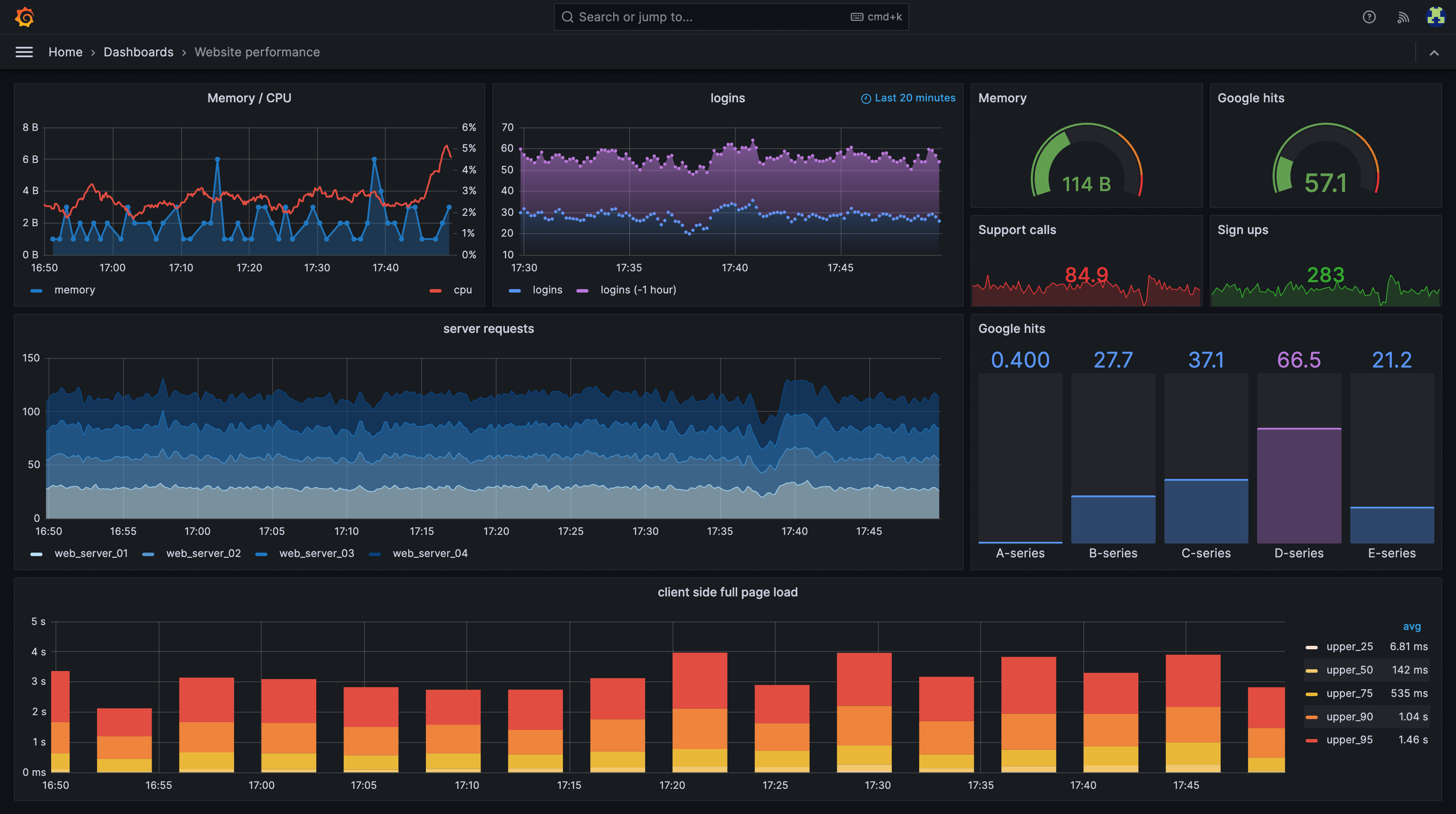 스프링을 학습하며 가장 눈이 즐거울 학습이 될 것이다. 학습의 궁극적 목표는 항상 서버기술에 대한 것이므로 웹 실습에서 UI는 단순화하고 내부 기술에 집중한다. 그에 따라 실습 결과물의 외모는 최악이다. 예쁘고 전문적으로 보이는 대시보드 UI는 항상 사막속 오아시스처럼 여겨진다.
스프링을 학습하며 가장 눈이 즐거울 학습이 될 것이다. 학습의 궁극적 목표는 항상 서버기술에 대한 것이므로 웹 실습에서 UI는 단순화하고 내부 기술에 집중한다. 그에 따라 실습 결과물의 외모는 최악이다. 예쁘고 전문적으로 보이는 대시보드 UI는 항상 사막속 오아시스처럼 여겨진다.
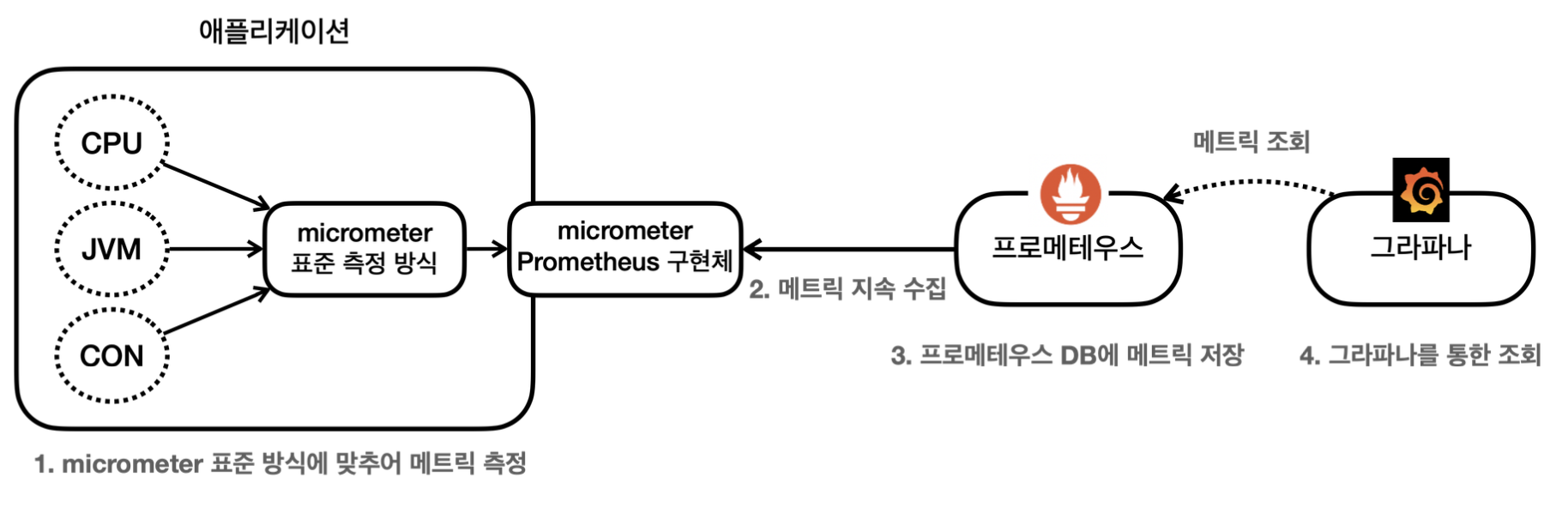
위의 짤은 그라파나로 대시보드 툴이다. 설치해서 사용해야하며 스프링 서버 어플리케이션에서 데이터를 보내주어야한다.(정확히 말하자면 대시보드 툴이 데이터를 적당한 시간간격을 두고 채취해간다.)
더 자세히 따져보자면 어플리케이션에서 곧바로 그라파나로 데이터(액츄에이터의 매트릭 정보)가 가는 것이 아니라 프로메테우스라는 모니터링용, DB비슷한 중간 매개체가 존재한다. 프로메테우스 또한 하나의 포트, 프로세스로 실행해야하는 서버 성격의 존재이다. 프로메테우스는 일정한 시간 간격으로 어플리케이션의 액츄에이터 매트릭을 http통신 등으로 가져간다. 프로메테우스에서도 데이터를 그래프로 하여금 관찰이 가능하지만, 대시보드를 구성할 수 있는 등의 기능적 자유도가 높지 못하다. 그렇기에 그라파나까지 연결하는 것이다.
유지보수 관리의 절차를 생각해보자. 우리는 백엔드 서버의 성능적 문제, 예상치 못한 트러블 이벤트를 인식하고 이에 맞추어 코드를 다시 짜거나 서버를 늘린다던가 문제를 해결한다.
유지보수 관리의 첫번째는 문제 인식이다. 문제 인식에도 절차가 존재할 것이다. 가장 보편적으로 사용될 수 있는 인식법은 문제를 보편적으로 관찰하다가 세부적으로 좁혀가는 것이다.(넓게넓게 보다가 시스템 흐름이 이상하다싶은 지점을 자세히 탐색하는 것으로 문제 인식에 대한 이해를 높여나간다.)
우리 어플리케이션을 가장 넓게 보기위해 그라파나(Grafana)를 사용한다.
마이크로미터
모니터링 툴에는 그라파나 외에도 여러가지가 존재하는 듯, 중간 매개체인 프로메테우스또한 다른 여러 툴이 존재한다. 여기서 중요한 점은 각 중간 매개체마다 데이터를 받는 형식이 다르다는 것이다.(json처럼 통일된 형식이 존재하지 않는다.) 아래의 사진은 프로메테우스가 스프링에서 데이터를 가져오기위해 스프링 데이터를 프로메테우스의 수신 형식으로 바꾼 결과물이다.
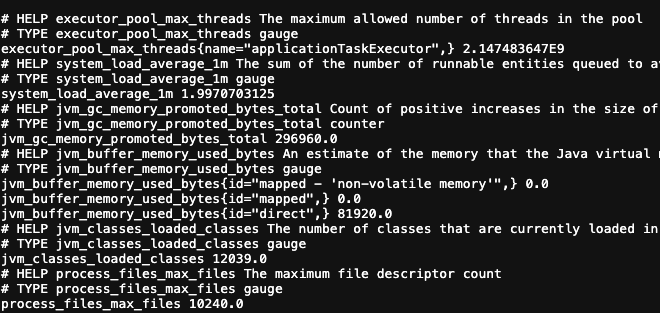
마이크로미터(Micrometer)는 매트릭 데이터 변환을 위한 스프링 인터페이스이다. 여기에 프로메테우스 변환기등 여러 구현체를 꼽을 수 있다. 우리는 build.gradle에 프로메테우스 레지스트리만 추가해주면 스프링은 알아서 프로메테우스 형식으로 서버 데이터를 넘겨버린다.
프로메테우스의 형식에서 몇 가지 문법적 특징은 다음과 같다.
-
jvm.info->jvm_info: 프로메테우스는.대신에_포멧을 사용한다. -
만약
http.server.requests가 count, sum, max 정보를 가진다면 다음 3가지로 분리된다. -
http_server_requests_seconds_count: 요청 수
-
http_server_requests_seconds_sum: 시간 합(요청수의 시간을 합함)
-
http_server_requests_seconds_max: 최대 시간(가장 오래걸린 요청 수)
프로메테우스 연결 방법(in MAC)
프로메테우스를 설치하고 prometheus.exe 실행한다. 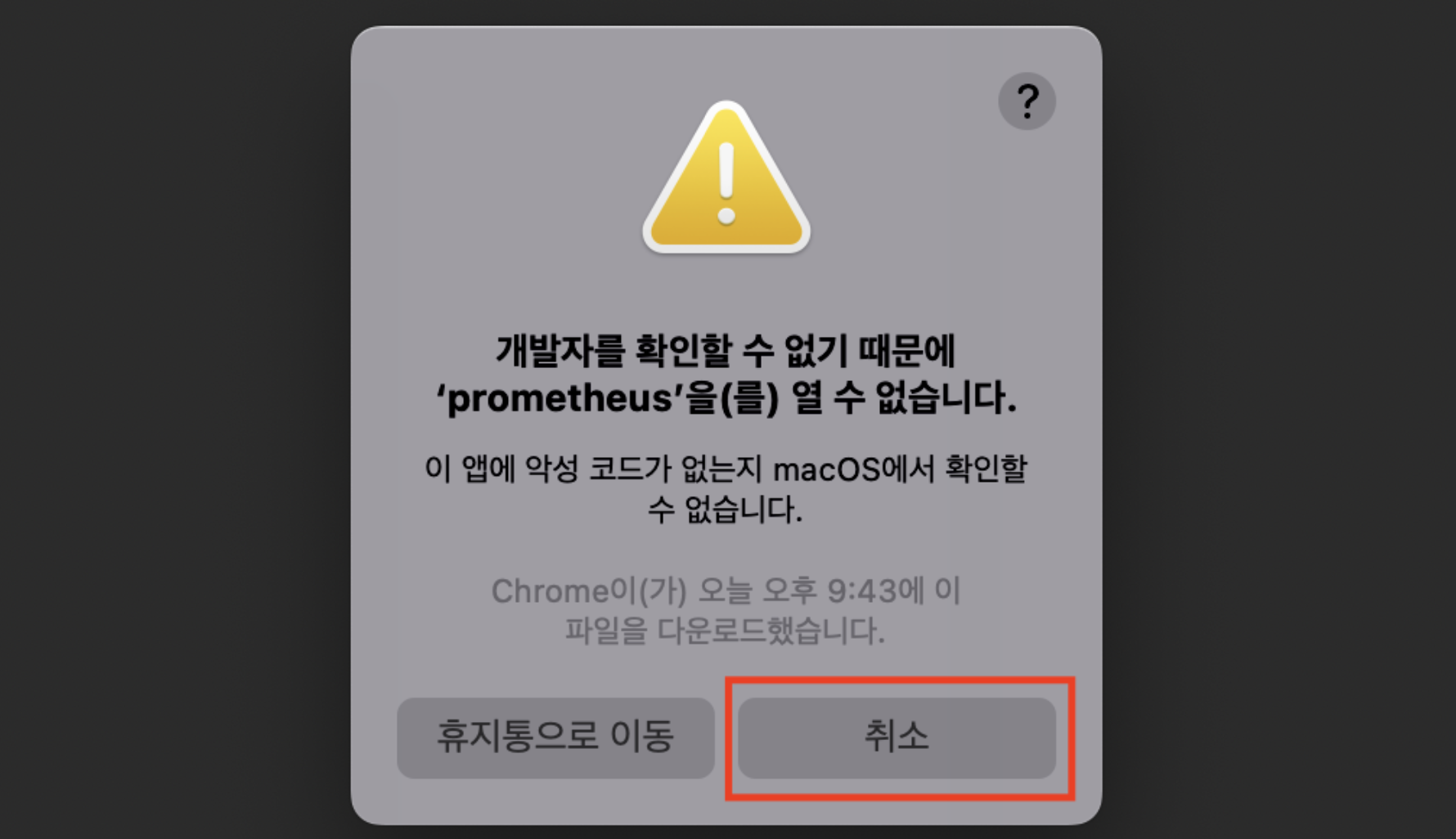 위와 같은 문제가 발생할 것이고 시스템 환경설정, 보안 및 개인 정보 보호, 일반 순으로 들어가서
위와 같은 문제가 발생할 것이고 시스템 환경설정, 보안 및 개인 정보 보호, 일반 순으로 들어가서 확인 없이 허용을 클릭하여 MAC의 보안 문제를 해결해준다.
실행하면 기본적으로 9090포트에 할당되어 프로그램이 실행된다.
스프링 프로젝트의 build.gradle에 implementation 'io.micrometer:micrometer-registry-prometheus를 추가해주고 설치한 프로메테우스 디렉터리에서 프로메테우스 폴더에 있는 prometheus.yml 파일을 다음처럼 수정해주어야 한다.
#추가
- job_name: "spring-actuator"
metrics_path: '/actuator/prometheus'
scrape_interval: 1s
static_configs:
- targets: ['localhost:8080']프로메테우스 설정 정보에 스프링 어플리케이션 정보를 넣어주고, 스프링 어플리케이션에는 프로메테우스 연결을 위해 build.gradle에 정보를 넣어준다.
이럼 끝이다. 프로메테우스는 scrape_interval의 간격으로 데이터를 수집한다. 보통은 10, 15, 60s를 사용하는 것이 일반적이지만 실습의 속도를 위해 1s로 진행한다.
프로메테우스 접근 및 간단한 사용
http://localhost:9090으로 접근하고 Status에서 Configuration을 확인하면 다음과 같이 스프링 어플리케이션 연결을 확인할 수 있다.
그리고 쿼리문을 작성해서 테이블, 그래프 형식으로 과거 기록부터의 흐름을 알 수 있다.
 위와 같이 프로메테우스는 자유도가 높고 여러 정보가 직관적인 대시보드라기엔 부족함이 있다. 그렇기에 그라파나로 하여금 프로메테우스가 받는 정보들을 표시할 수 있다. 즉 그라파나는 예쁘고 조립이 자유로운 껍데기 역할이다.
위와 같이 프로메테우스는 자유도가 높고 여러 정보가 직관적인 대시보드라기엔 부족함이 있다. 그렇기에 그라파나로 하여금 프로메테우스가 받는 정보들을 표시할 수 있다. 즉 그라파나는 예쁘고 조립이 자유로운 껍데기 역할이다.
매트릭
액츄에이터의 매트릭은 게이지(Gauge), 카운터(Counter)로 크게 두 가지로 구분된다.
게이지는 오르고 내릴 수 있는 값이다. 카운터는 단순히 쌓이는 값이다. 즉 CPU 사용량은 게이지이며, 로그 발생 수는 카운터이다.(이해가 애매하다면 내릴 수 있다는 개념으로 구분하면 좋을 것 같다.)
게이지 값은 시간에 대해 그대로 사용하면 될 것이다.(주식 그래프를 생각해보자. 시간(x)과 주식 가격(y) 값만 사용하면 곧바로 그래프를 그릴 수 있다.)
카운터 값은 그대로 보여주기에 문제가 존재한다.
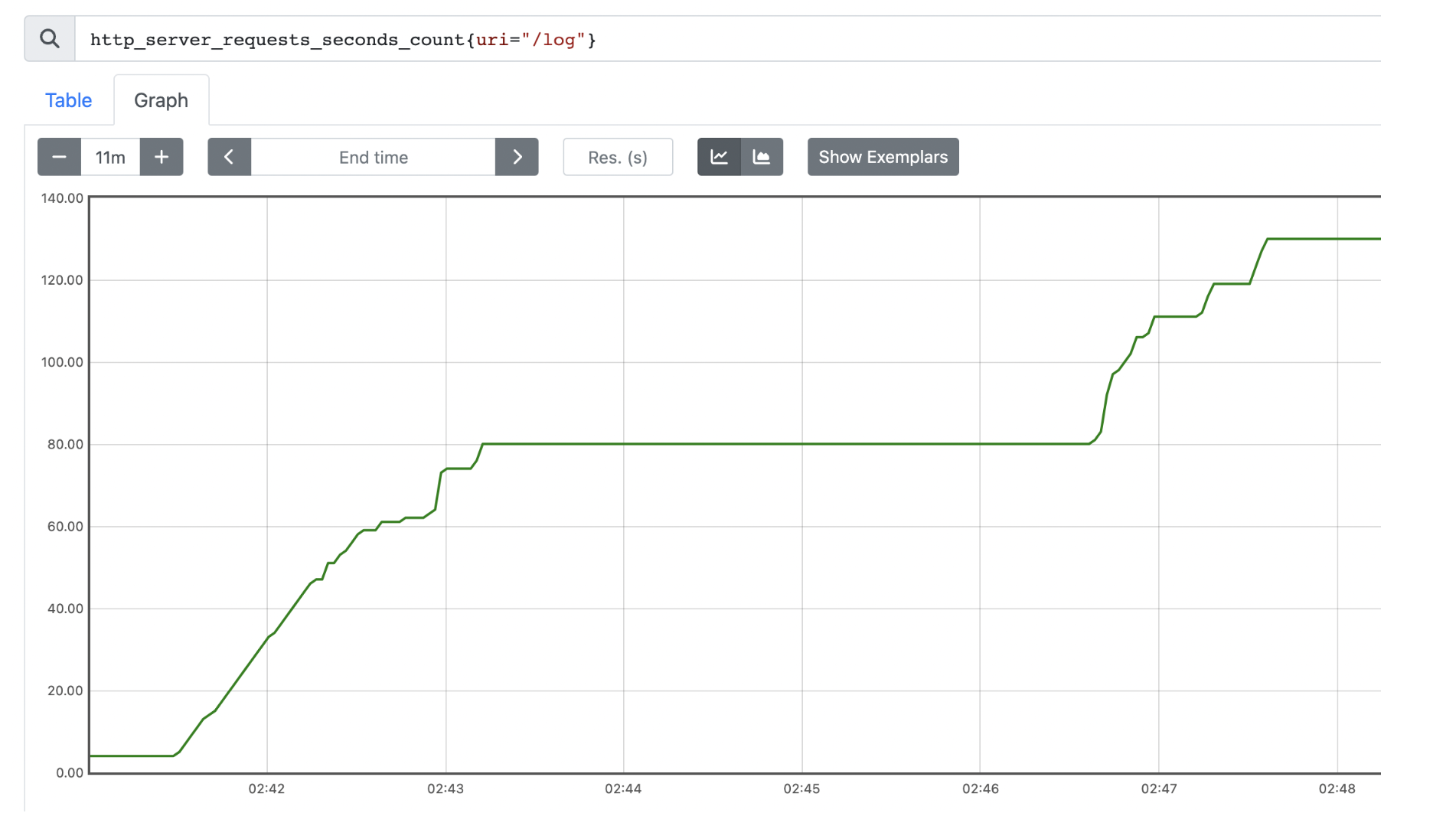 우리가 위 로그 카운터 그래프를 보며 관심이 있는 부분은 어느 시점에 로그가 증가하느냐, 얼마나 증가하느냐에 대한 부분이다. 미분, 적분, 통계에 대한 개념이 있다면 저 그래프를 개선할 동기가 생길지도 모른다.
우리가 위 로그 카운터 그래프를 보며 관심이 있는 부분은 어느 시점에 로그가 증가하느냐, 얼마나 증가하느냐에 대한 부분이다. 미분, 적분, 통계에 대한 개념이 있다면 저 그래프를 개선할 동기가 생길지도 모른다.
우리는 위 그래프를 보며 2차적인 연산을 해야한다. 02:46 ~ 02:48 경에 증가한 흐름에 대해 우린 뺄셈을 통해 로그가 얼마나 증가했는지 정도를 알 수 있다. 이 그래프를 미분한 형태의 그래프로 본다면 더욱 직관적으로 그래프를 이해하기 편할 것이다.
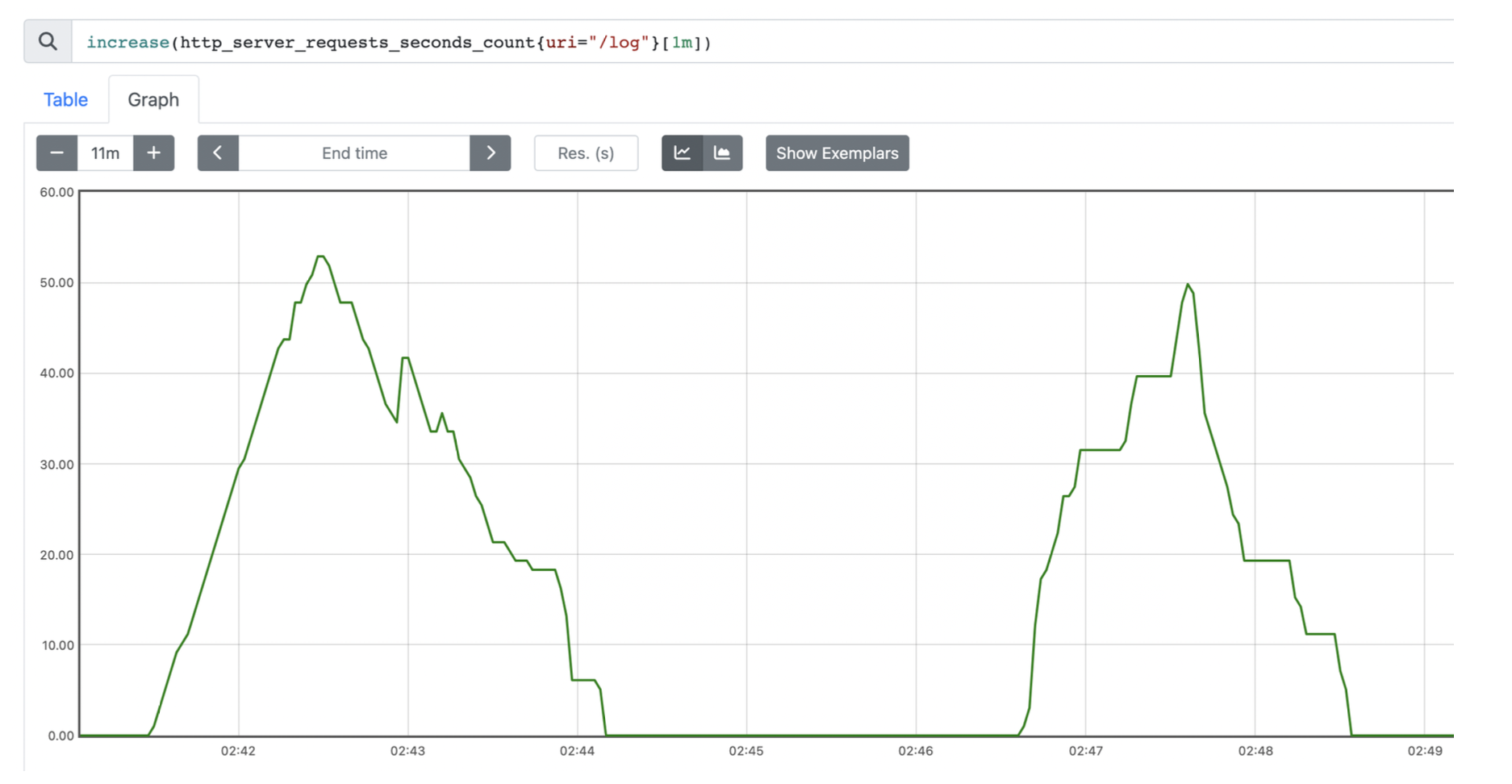 프로메테우스 쿼리에
프로메테우스 쿼리에increase()를 활용하여 1분간 쌓인 로그의 양을 시간에 대한 그래프로 바꿔낼 수 있다. 꼭짓점이 보이기 때문에 변화의 "정도"를 쉽게 파악할 수 있다. rate()를 통해 형태는 같지만 정말로 변화율 그래프를 보이게 할 수도 있다. 하지만 increase()가 가장 일반적으로 활용하기 좋다고 생각한다.
그라파나
그라파나 또한 설치후 bin폴더에서 grafana-server.exe 실행해준다. 권한이 막혀있다면 위의 경우(프로메테우스 실행)처럼 해결해주도록 하자. 우리의 모니터링의 모든 과정은 아래와 같다.
그라파나의 Configuration에 Add data source하여 Prometheous, url:http://localhost:9090를 선택해주면 연결이 끝이 난다.
대시보드 오픈소스
대시보드를 직접 만들어도 좋지만 인기있게 사용되는 이미 잘 구축한 스프링용 오픈소스 대시보드들이 존재한다.(그라파나 오픈소스 대시보드) 여기서 Id(ex.11378)를 카피해와서 대시보드를 만들때 Import를 선택해서 Id를 넣고 Prometheous로 데이터소스를 선택한뒤 Import 해준다.
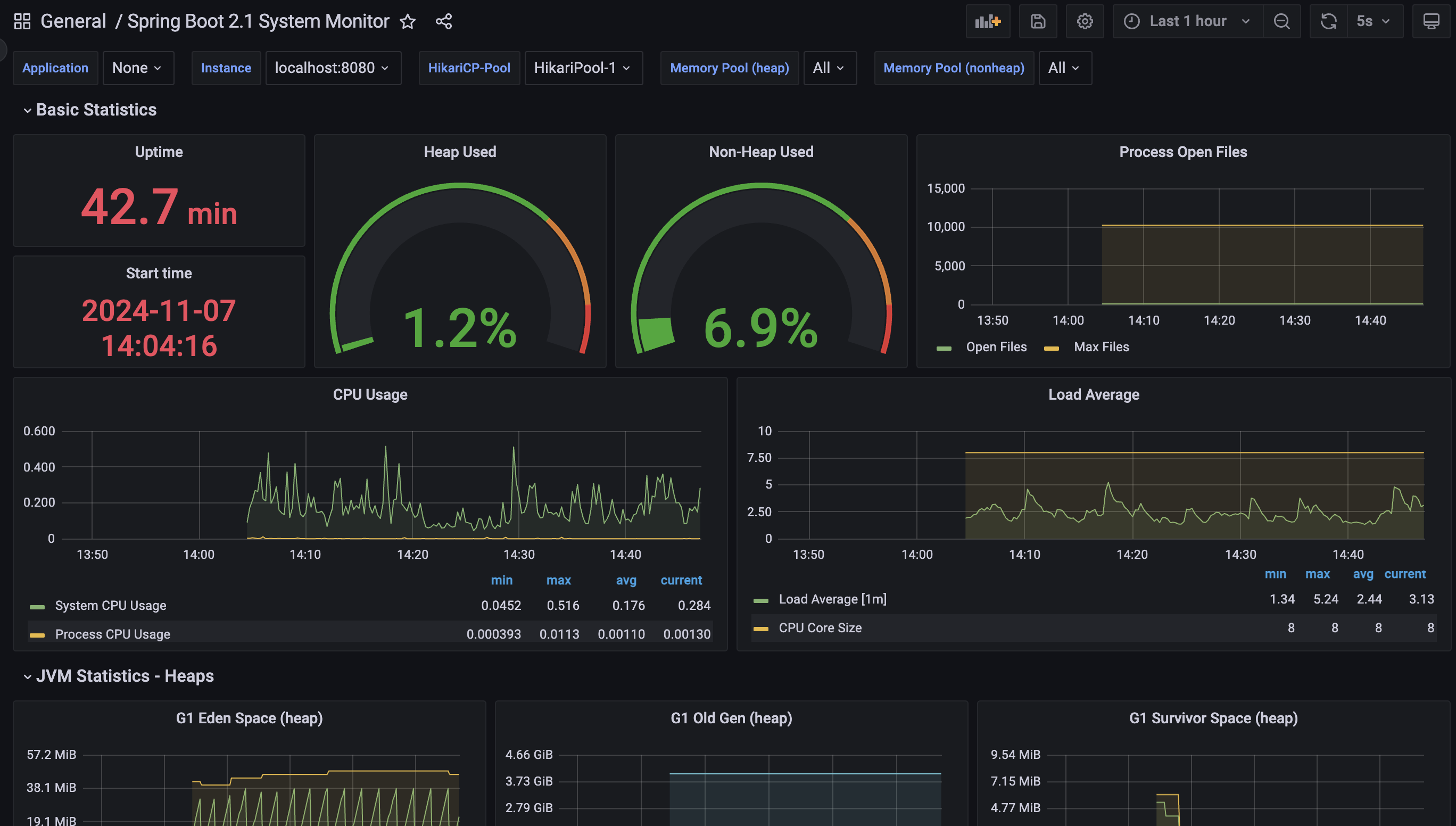 매우 예쁜 어플리케이션 관리를 위한 모니터링 화면이 나타난다! JVM에 대한 현황, 하드웨어 사용량 정보, 쓰레드 풀 상황등 많은 정보들을 관찰할 수 있다.
매우 예쁜 어플리케이션 관리를 위한 모니터링 화면이 나타난다! JVM에 대한 현황, 하드웨어 사용량 정보, 쓰레드 풀 상황등 많은 정보들을 관찰할 수 있다.
커스텀 매트릭
@Counted
private AtomicInteger stock = new AtomicInteger(100);
@Counted("my.order")
@Override
public void order() {
log.info("주문");
stock.decrementAndGet();
}
@Counted("my.order")
@Override
public void cancel() {
log.info("취소");
stock.incrementAndGet();
}위의 코드는 재고가 100개일 때 order를 넣으면 stock이 1이 떨어지고 취소를 할 경우 stock이 1이 오르는 아주 단순한 주문, 취소 기능 예제이다.
@Counted로 하여금 order가 몇번 실행되었는지, cancel이 몇번 실행되었는지에 대한 매트릭을 프로메테우스로 넘기게 된다.
커스텀 게이지 매트릭
Gauge의 경우 Counter처럼 AOP를 지원하지는 않는다. 위의 stock을 게이지로 나타낸다면 다음과 같이 Config에 등록할 수 있을 것이다.
@Bean
public MeterBinder stockSize(OrderService orderService) {
return registry -> Gauge.builder("my.stock", orderService, service -> {
log.info("stock gauge call");
return service.getStock().get();
}).register(registry);
}혹은 GaugeBuilder를 직접 생성해서 필드를 지정해주어도 된다.
@Timed
@Timed는 메서드, 클래스 레벨에서 적용가능하며 해당 메서드가 시간 소요에 대한 데이터를 프로메테우스로 보낼 수 있다. (COUNT, TOTAL_TIME, MAX를 제공받는다.)
@Bean
public TimedAspect timedAspect(MeterRegistry registry) {
return new TimedAspect(registry);
}다만 사용을 위해 Config에 TimeAspect에 MeterRegistry를 주입받은 빈 등록이 필요하다.
실무 모니터링 환경 구성 팁
- 전체 모니터링 - 대시보드
- 애플리케이션 추적 - 핀포인트(네이버 오픈소스)
- 로그
처음 서술한 내용처럼 문제 인식의 절차는 점진적으로 좁은 영역으로 가는 것이다. 대시보드로 하여금 전체적인 흐름을 볼 수 있도록 세팅하고 핀포인트에서 세부사항을 흐름 순서로 볼 수 있다. 그리고 로그로 하여금 더욱 세부적인 요소를 관찰할 수 있다.
핀포인트로 하여금 MSA환경에서 모든 모듈이 주고받는 상황을 관찰가능하다.(매우 유용한 오픈소스)
알람 기능
슬랙과 같은 플랫폼을 활용해서 문제에 대한 알람을 받도록 구성하는 것도 좋은 아이디어이며 많이 사용되는 방식일 것이다. 다만 이 기능을 구성할 때에는 "정도"에 대한 판단이 매우 중요하다. 너무 많은 알람이 수신되도록 한다면 중요도가 낮은 알람들이 많을 수 있다. 자연히 이를 무시하는 무의식이 생길 수 있고, 개발자의 삶의 질을 떨어뜨린다.
