
설계
네이버 API를 활용, 검색엔진 키워드로 하여금 아침마다 원하는 탑 뉴스를 슬랙에 자동 전송하는 간단한 툴
슬랙 봇 Create
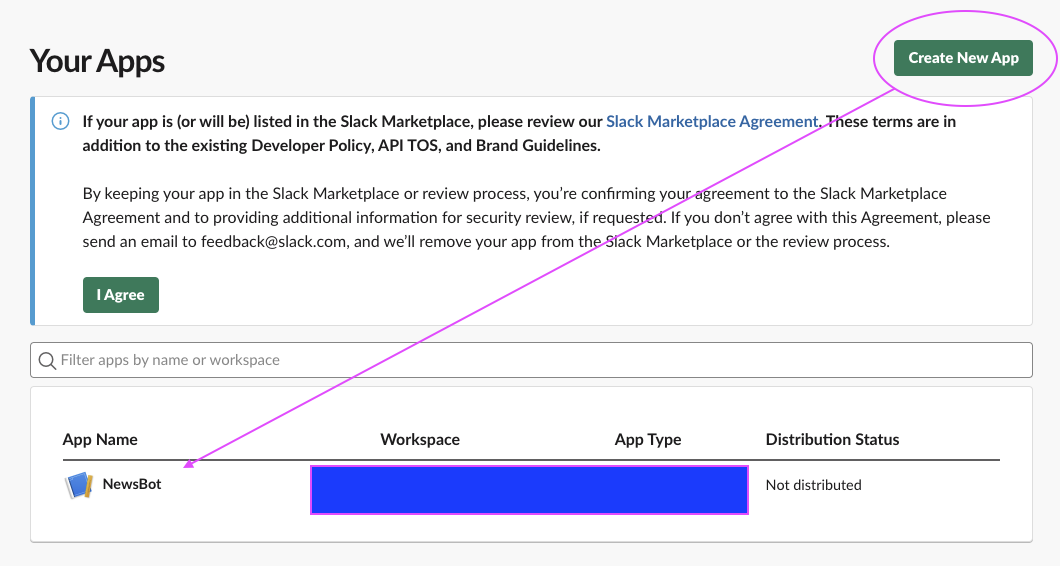
Create New App을 통해 앱을 만들고 만든 앱에 접근
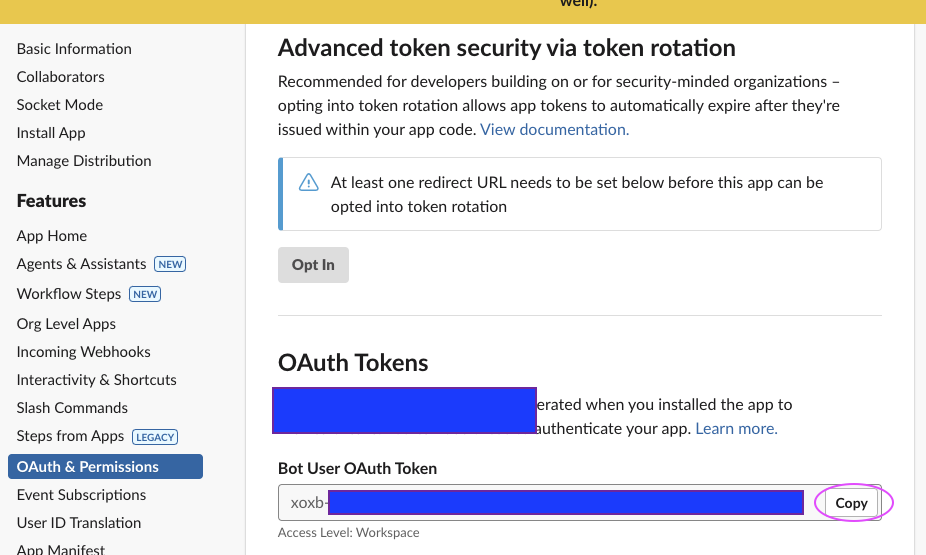
OAuthToken값을 잘 기억하기.
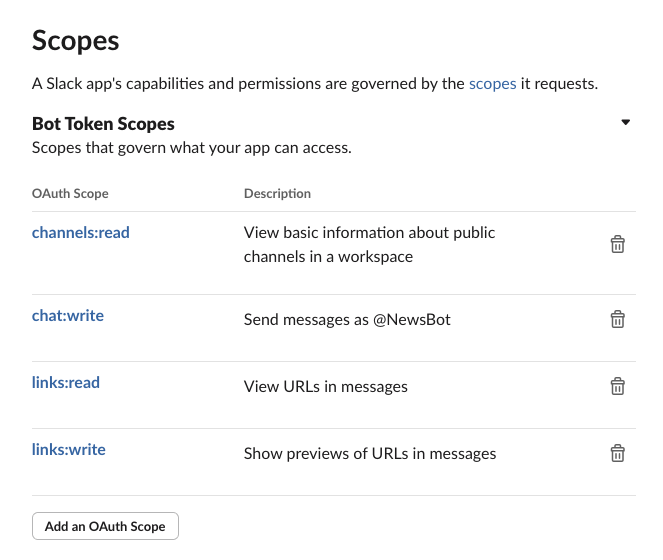
OAuth Scopes 권한 다음과 같이 주기.
슬랙 어플리케이션 켜서 앱 추가해주기.
SpringBoot Starter
라이브러리 Lombok만 선택해서 부트 생성
//build.gradle
dependencies {
compileOnly 'org.projectlombok:lombok'
annotationProcessor 'org.projectlombok:lombok'
testImplementation 'org.springframework.boot:spring-boot-starter-test'
testRuntimeOnly 'org.junit.platform:junit-platform-launcher'
//slackBot
implementation("com.slack.api:bolt:1.44.1")
implementation("com.slack.api:bolt-servlet:1.44.1")
implementation("com.slack.api:bolt-jetty:1.44.1")
implementation("org.slf4j:slf4j-simple:1.7.36")
//테스트에서 lombok 사용
testCompileOnly 'org.projectlombok:lombok'
testAnnotationProcessor 'org.projectlombok:lombok'
}위 처럼 테스트 롬복 사용, slackBot 관련 gradle 설정 추가
slackBot 버전의 경우 슬랙 버전 참고해서 최신으로 셋팅
application.properties 사용해도 되는데 .yml로 함.(본인 편한대로 아래 예시는 .yml기준)
slack:
token: xoxb-.... slack OAuth 토큰 기입구현
스케줄링 만들기
@RequiredArgsConstructor
@EnableScheduling
@Configuration
public class SlackBatch {
private final NewsService newsService;
private final UtilService utilService;
private final NaverAPI naverAPI;
@Scheduled(cron = "0 0/1 * * * *") // every 1 minutes
public void batchTest() {
utilService.sendSlackMessage("테스트: 1분 간격 message 전송", SlackChannelCostant.NEWS_CHANNEL);
List<NaverNewsApiDto> response = naverAPI.fetchNews();
for (NaverNewsApiDto naverNewsApiDto : response) {
utilService.sendSlackMessage(naverNewsApiDto.getOriginallink(), SlackChannelCostant.NEWS_CHANNEL);
}
}
}테스트 환경이라 1분마다 뉴스 정보 슬랙에 쏘도록 만듬. 다 만들면 (매일 오전 9시로 수정)
네이버 API 요청 결과 json 형식 확인
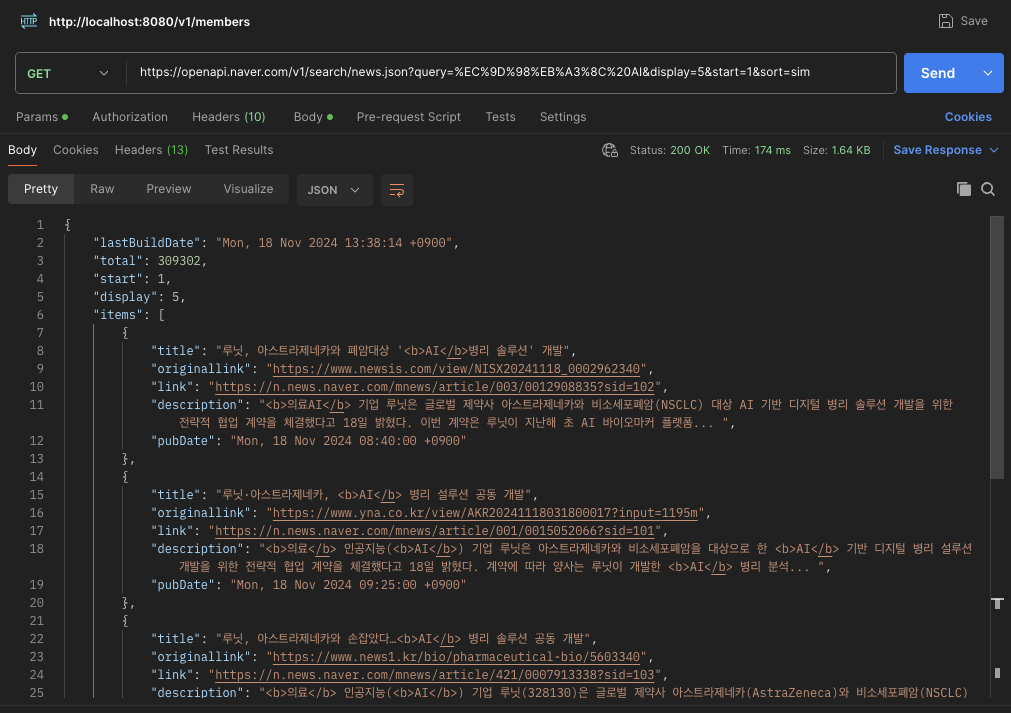
위의 요청 경로로 헤더에 X-Naver-Client-Id, X-Naver-Client-Secret 넣으면 된다.(네이버 API 어플리케이션 등록하면 발급가능)
// 네이버 API 이용을 위한 상수 클래스
public class NaverConstant {
public final static String XNaverClientId = ID값 기입하세요;
public final static String XNaverClientSecret = Secret값 기입하세요.;
public final static String searchName = "증권";
public final static int displayCount = 5;
}위에 맞추어 DTO 제작
@Data
public class NaverNewsApiReponseDto {
private String lastBuildDate;
private int total;
private int start;
private int display;
private List<NaverNewsApiDto> items;
}
////
@Data
public class NaverNewsApiDto {
private String title;
private String originallink;
private String link;
private String description;
private String pubDate;
}NaverNewsApiReponseDto로 받아와서 NaverNewsApiDto로 활용할 것
API 요청용 RestTemplate 코드 작성
public List<NaverNewsApiDto> fetchNews() {
String url = "https://openapi.naver.com/v1/search/news.json?query=" +
NaverConstant.searchName +
"&display=" +
NaverConstant.displayCount +
"&start=1&sort=sim";
// 헤더 설정
HttpEntity<String> entity = getEntity();
// API 요청
RestTemplate restTemplate = new RestTemplate();
ResponseEntity<NaverNewsApiReponseDto> response = restTemplate.exchange(
url,
org.springframework.http.HttpMethod.GET,
entity,
NaverNewsApiReponseDto.class
);
// 반환된 뉴스 리스트 반환
return response.getBody().getItems();
}발견된 문제 :: 중복 주제 뉴스
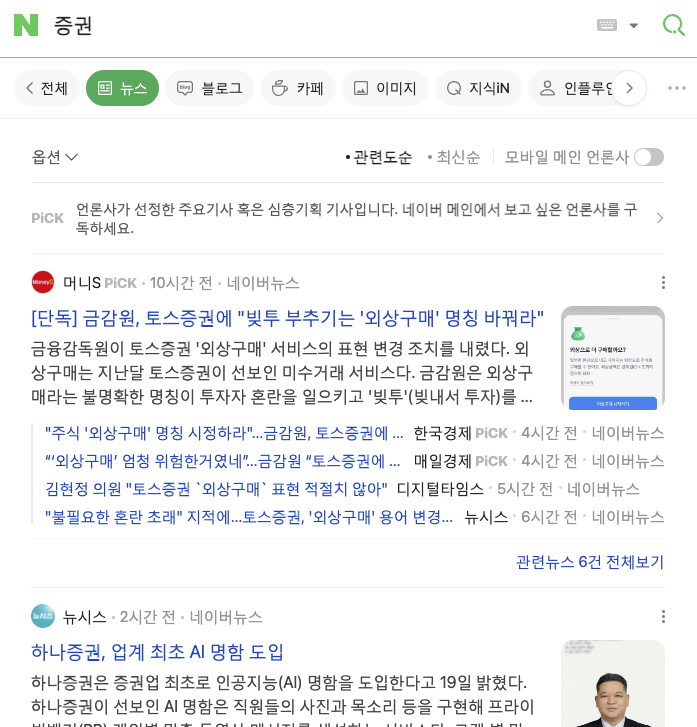 네이버 뉴스는 비슷한 주제를 합쳐서 하나의 카드에서 다른 언론들을 포함해서 보여주고 있으나 API로 가져올 경우 탑5 뉴스는 모두 위에서 보듯 "토스증권" 이슈로 동일한 5개가 추출 된다.
네이버 뉴스는 비슷한 주제를 합쳐서 하나의 카드에서 다른 언론들을 포함해서 보여주고 있으나 API로 가져올 경우 탑5 뉴스는 모두 위에서 보듯 "토스증권" 이슈로 동일한 5개가 추출 된다.
유사도 알고리즘을 활용하여 중복에 해당하는 뉴스들을 리스트에서 지우고 유사도가 낮은 다음 우선순위의 뉴스를 반환할 뉴스 리스트에 넣는 기능을 설계하기로 했다.
활용한 데이터는 뉴스의 제목(title)과 뉴스의 요약(description) 제목에 가중치 0.7, 내용에 0.3으로 가중치 평균 값을 JaccardSimilarity 유사도 측정 알고리즘를 활용하여 추출한다.
기존에는 상단 뉴스 5개를 가져왔지만 이를 50개로 늘림. 가장 첫번째 기사를 유사도 분석 기준으로 삼음 + 리턴 뉴스 리스트에 Add
유사도Value가 0.1(threshold) 이상일 경우 삭제대상, 이하일 경우 리턴후보대상으로 두고
기존 파싱 뉴스 리스트에 대해 첫번째 기사 기준 유사도 분석이 끝나면 리턴 후보대상중 첫번째 기사를 유사도 분석 기준으로 교체, 리턴 뉴스 리스트에 Add한다.
리턴 뉴스 리스트의 size가 5가 될때까지 위 과정 반복한다.
최종 필터링된 리턴 뉴스 리스트로 슬랙 봇에 sendMessage()로 하여금 링크 전달한다.
문제 해결


의료 AI 키워드로 진행, 루닛이 작성 시점 근처로 아스트라제네카랑 좋은 소식이 있어 상한가까지 가서 윗 뉴스가 루닛으로 도배되어 단순히 API로 탑5뉴스 가져오면 모두 루닛 뉴스였다.
유사도 로직으로 하여금 다른 뉴스들이 포함될 수 있도록 하였다.
@Service
@Slf4j
public class NewsSelector {
private static final double TITLE_WEIGHT = 0.7; // 가중치: title
private static final double DESCRIPTION_WEIGHT = 0.3; // 가중치: description
private static final double THRESHOLD = 0.1; // 유사도 임계값
//getTopNews 에서 사용되는 값
private final List<NaverNewsApiDto> topNews = new ArrayList<>();
private NaverNewsApiDto index = new NaverNewsApiDto();
private double calculateWeightedSimilarity(NaverNewsApiDto news1, NaverNewsApiDto news2) {
double titleSimilarity = calculate(news1.getTitle(), news2.getTitle());
double descriptionSimilarity = calculate(news1.getDescription(), news2.getDescription());
// 평균 가중치 유사도 계산
double weightedSimilarity = (titleSimilarity * TITLE_WEIGHT) + (descriptionSimilarity * DESCRIPTION_WEIGHT);
// 유사도 계산 로깅
// log.info("Comparing News1: [{}] with News2: [{}]", news1.getTitle(), news2.getTitle());
// log.info("Title Similarity: {}, Description Similarity: {}, Weighted Similarity: {}",
// titleSimilarity, descriptionSimilarity, weightedSimilarity);
return weightedSimilarity;
}
public List<NaverNewsApiDto> getTopNews(List<NaverNewsApiDto> newsList, int count) {
if (newsList.isEmpty()) {
throw new IllegalStateException("파싱된 뉴스가 없습니다. 네이버 API Parsing 기능 이상");
}
topNews.add(newsList.get(0));
index = newsList.get(0);
List<Integer> removeTmp = new ArrayList<>();
filtering(newsList, count, removeTmp);
return topNews;
}
private void filtering(List<NaverNewsApiDto> newsList, int count, List<Integer> removeTmp) {
while (topNews.size() != count) {
if (newsList.isEmpty()) {
log.info("소스 부족");
break;
}
List<Integer> canTopNewsIndex = new ArrayList<>();
for (int i = 0; i < newsList.size(); i++) {
double similarityValue = calculateWeightedSimilarity(index, newsList.get(i));
if (similarityValue > THRESHOLD) {
removeTmp.add(i);
} else {
canTopNewsIndex.add(i);
}
}
Integer topNewsSourceIndex = canTopNewsIndex.get(0);
NaverNewsApiDto topNewsSource = newsList.get(topNewsSourceIndex);
topNews.add(topNewsSource);
index = topNewsSource;
newsList = removeIndices(newsList, removeTmp);
removeTmp.clear();
}
}
public static <T> List<T> removeIndices(List<T> list, List<Integer> indices) {
return IntStream.range(0, list.size())
.filter(i -> !indices.contains(i))
.mapToObj(list::get)
.collect(Collectors.toList());
}
}
////
public class JaccardSimilarity {
public static double calculate(String text1, String text2) {
Set<String> set1 = new HashSet<>(Arrays.asList(text1.split(" ")));
Set<String> set2 = new HashSet<>(Arrays.asList(text2.split(" ")));
Set<String> intersection = new HashSet<>(set1);
intersection.retainAll(set2);
Set<String> union = new HashSet<>(set1);
union.addAll(set2);
return (double) intersection.size() / union.size();
}
}유사도 필터링 로직은 3ms로 좀더 최적화할 수 있을 것 같지만 그럴 이유가 없다고 판단해서(API Parsing 과정이 300~500ms)생각나는대로 구현하고 끝내었다.
SlackBot 전달
@Service
@Slf4j
public class UtilService {
@Value(value = "${slack.token}")
String slackToken;
public void sendSlackMessage(String message, String channel) {
String channelAddress = SlackChannelCostant.NEWS_CHANNEL;
try {
MethodsClient methods = Slack.getInstance().methods(slackToken);
ChatPostMessageRequest request = ChatPostMessageRequest.builder()
.channel(channelAddress)
.text(message)
.unfurlLinks(true)
.unfurlMedia(true)
.build();
methods.chatPostMessage(request);
log.info("Slack " + channel + " 에 메세지 보냄");
} catch (SlackApiException | IOException e) {
log.error(e.getMessage());
}
}
}여기서 application.yml에 넣은 slackBot OAuth 토큰값 활용.
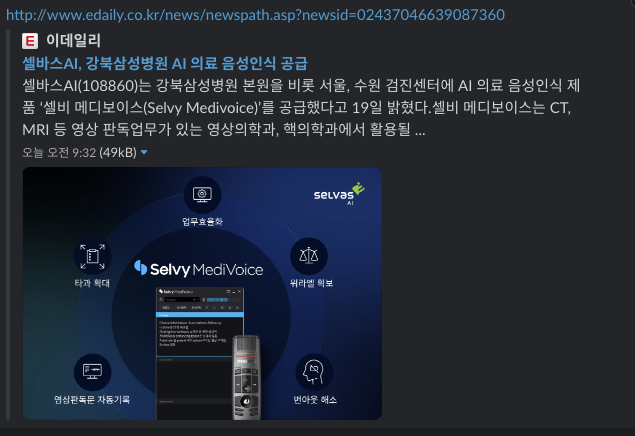
링크 전달시 카드뉴스로 보기 위해 .unfurlLinks(true) .unfurlMedia(true)를 지정해주자.
그렇지않으면 링크만 가기 때문에 클릭하기전에는 무슨 내용인지 알 수없다.
HTML의 <meta> 태그는 웹페이지의 메타데이터를 제공하며, 특히 검색 엔진 최적화(SEO) 및 소셜 미디어 공유 최적화에 중요한 역할을 하는데, 각 뉴스사에서 카드 뉴스 기능을 구현할 때 <meta> 태그를 적절히 구성하면 검색 및 소셜 미디어에서 더 나은 사용자 경험을 제공할 수 있기때문에 meta태그에 OpenGraph 데이터를 채워 제공한다. (아래 처럼 볼 수 있음.)
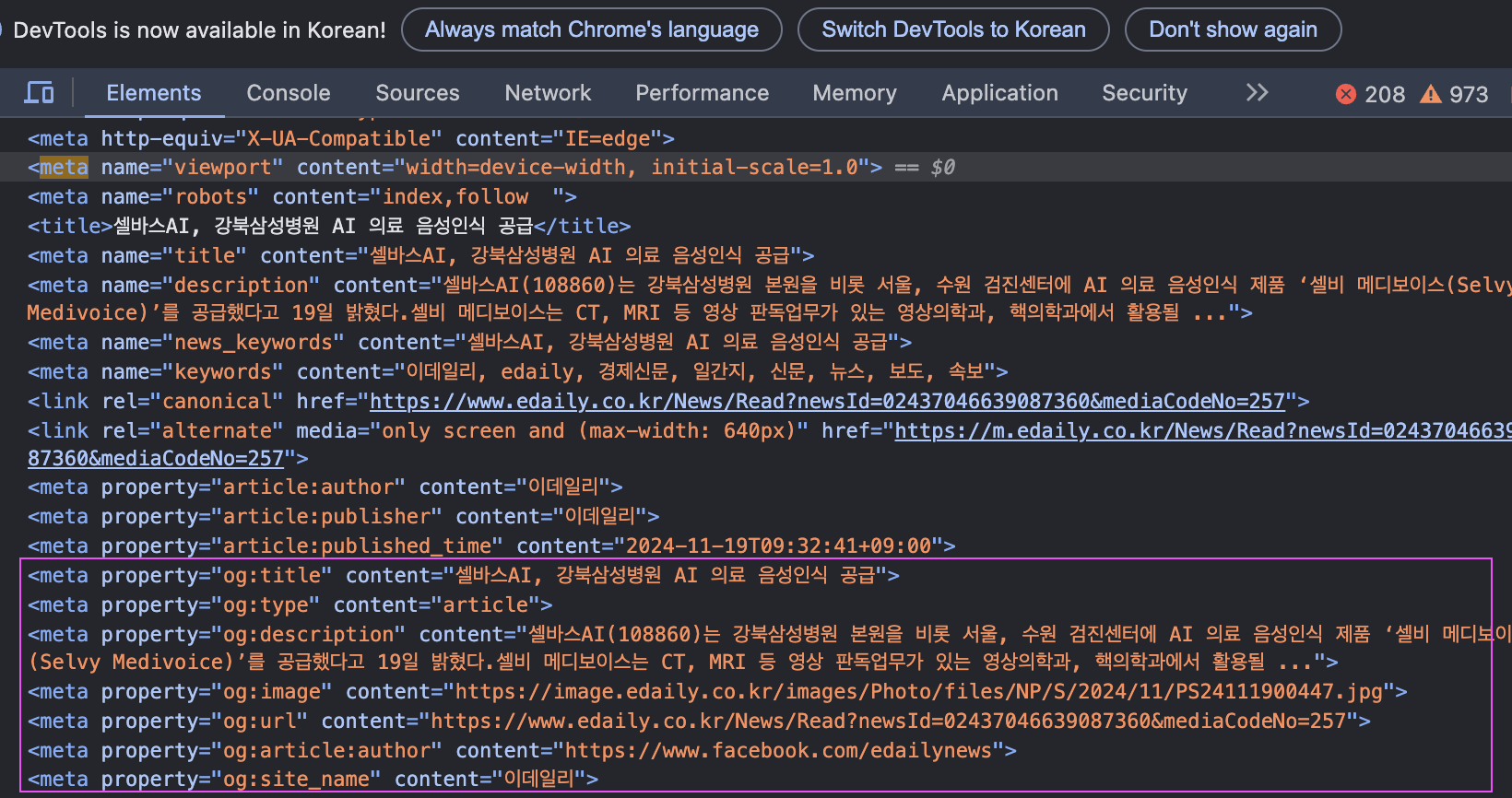
슬랙은 이를 인식하여 자동으로 카드뉴스 처리를 해주기 때문에 .unfurlLinks(true) .unfurlMedia(true) 이 기능을 잘 켜주고 슬랙 봇 OAuth Scopes 권한에서 links:read, links:write를 허용시켜주어야 한다.
