문제 상황
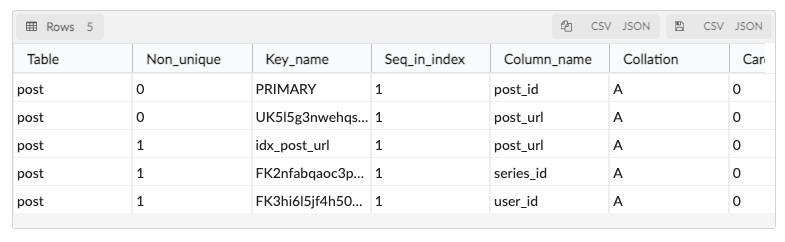
post_url에 대한 key가 두개나 뜨는 것을 볼 수 있었다.
@Entity
@Table(
indexes = @Index(name = "idx_post_url", columnList = "postUrl")
)
public class Post extends BaseEntity {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "post_id")
private Long id;
...
@Column(unique = true, nullable = false)
private String postUrl;세컨더리 인덱스로 지정하기 위해 @Index를 사용한 것과 유니크성을 확보하기 위해 @Column에 unique=true 설정을 준 것이 내부동작 이해를 제대로하지 못하여 키가 두개가 생성된 문제이다.

확인 해본 결과 @Index는 유니크는 보장하지 않는 Btree 인덱스를 생성하며,
unique=true 설정은 유니크를 보장하는 Btree 인덱스를 생성한다.
해결
unique = true만 사용하도록 코드 수정
@Entity
public class Post extends BaseEntity {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "post_id")
private Long id;
...
@Column(unique = true, nullable = false)
private String postUrl; 정리: unique = true vs @Index vs @UniqueConstraint(추가 조사)
🚀 unique = true와 @Index의 차이점
@Index는 B-Tree 인덱스를 생성하여 검색 성능을 향상시키지만, 중복을 허용한다.unique = true는 B-Tree 인덱스를 생성하면서 동시에 유니크(Unique) 제약 조건을 부여하여 중복을 방지한다.
무엇을 사용해야 할까?
- 중복을 방지하면서 검색 성능도 향상시키려면 →
unique = true를 사용한다. - 중복이 허용되면서 검색 성능만 최적화하려면 →
@Index를 사용한다. - 두 개 이상의 컬럼을 조합하여 유니크 조건을 걸고 싶다면 →
@UniqueConstraint를 사용한다.
@UniqueConstraint란?
unique = true와 동일하게 유니크 제약 조건을 적용하지만, 두 개 이상의 컬럼을 조합하여 유니크 제약을 걸 수 있는 점이 다르다.- 복합 유니크 키를 만들 때 유용하다.
📌 예제: username과 email을 조합하여 유니크 조건 설정
@Entity
@Table(
uniqueConstraints = { @UniqueConstraint(name = "UK_username_email", columnNames = {"username", "email"}) }
)
public class User {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(nullable = false, length = 50)
private String username;
@Column(nullable = false, length = 100)
private String email;
}- 이렇게 설정하면
username + email의 조합이 중복되지 않도록 보장된다. - 단일 컬럼이라면
unique = true를, 여러 컬럼을 조합하려면@UniqueConstraint를 사용하면 된다.
🚀 최종 정리
| 구분 | @Column(unique = true) | @Index | @UniqueConstraint |
|---|---|---|---|
| 중복 방지 여부 | ✅ O (중복 불가) | ❌ X (중복 허용) | ✅ O (중복 불가) |
| 검색 성능 향상 여부 | ✅ O (B-Tree 인덱스 자동 생성) | ✅ O (B-Tree 인덱스 생성) | ✅ O (B-Tree 인덱스 생성) |
| 단일 컬럼 적용 가능 여부 | ✅ O | ✅ O | ✅ O |
| 두 개 이상의 컬럼 조합 가능 여부 | ❌ X | ✅ O (단순 인덱스) | ✅ O (복합 유니크 키) |
결론
- 유니크하면서 검색 속도를 높이고 싶다면? →
unique = true사용 - 검색 속도만 높이고 싶다면? →
@Index사용 - 두 개 이상의 컬럼을 조합하여 유니크 키를 설정하고 싶다면? →
@UniqueConstraint사용
**즉, 중복을 방지하면서도 검색 성능을 향상시키고 싶다면 unique = true를 선택하자.

자바집사의 거북이 수련법