사전 훈련된 신경망
사전 훈련된 신경망은 주어진 입력에 대한 출력을 만드는 프로그램이다. 이 프로그램의 동작 방식은 신경망의 아키텍처와 훈련 과정에서 사용된 데이터가 결정한다. 이번 장에서는 세 가지의 사전 훈련된 인기 모델을 다룬다.
- 이미지를 이해하고 레이블을 달아주는 모델
- 진짜 이미지로부터 새로운 이미지를 만들어내는 모델
- 그리고 이미지의 내용을 문법에 맞게 영어 문장으로 설명하는 모델
또한 사전 훈련된 모델을 일관된 인터페이스를 통해 공통으로 사용할 수 있게 만드는 도구들이 모여 있는 파이토치 허브도 알아본다.
이미지를 인식하는 사전 훈련된 신경망
TorchVision Project
여기에서는 AlexNet, ResNet, Inceptionv3 같은 컴퓨터 비전용 고성능 신경망 아키텍처를 볼 수 있다. 또한 이미지넷 같은 데이터셋에도 쉽게 접근할 수 있으며, 파이토치로 컴퓨터 비전 애플리케이션을 빠르게 만들 수 있는 유틸리티도 제공한다.
사전 훈련된 모델은 torchvision.models에 있다.
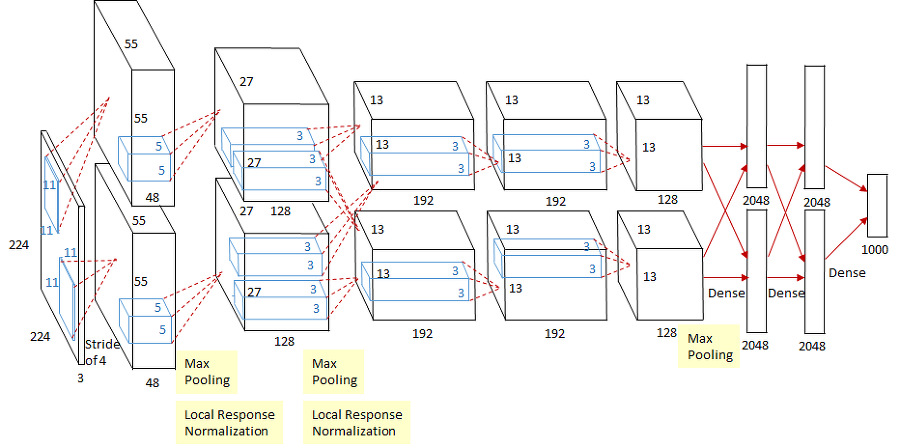
AlexNet
알렉스넷(AlexNet)은 2012년 ILSVRC에서 큰 격차로 우승했으며, 정답 레이블이 출력값에서 상위 5위 클래스 안에 들어 있어야 하는 '상위 5개 테스트'에서 15.4%의 오차율을 보였다. 2위와는 약 10%의 차이를 보였고, 커뮤니티의 모든 이가 비전에 대한 딥러닝 가능성을 깨닫기 시작한 순간이었다.
알렉스넷은 소규모 신경망으로 상대적으로 작지만, 실제 동작하는 신경망을 가볍게 살펴보고 새 이미지를 사전 훈련된 모델에 넣어보기에 최적이다.
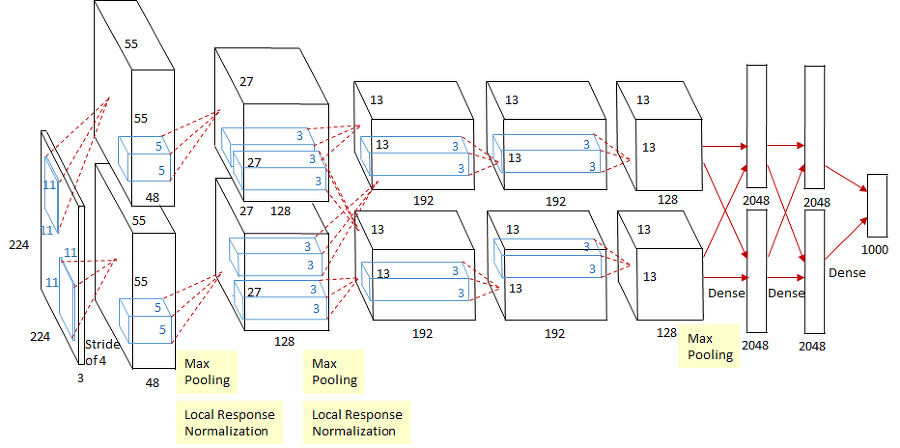
알렉스넷의 구조에서 몇 가지 특징을 확인 가능하다. 먼저 각 블럭이 여러 개의 곱셈과 덧셈으로 이뤄져 있고, 각각을 하나의 필터라고 생각할 수 있으며, 한 개 혹은 그 이상의 이미지를 입력으로 받고 다른 형태의 이미지로 변환하여 출력하는 함수이다. 중간 단계의 데이터 변환부가 각 예제와 기대값을 사옹한 훈련을 통해 만들어진다.
정확한 크기의 입력 데이터를 alexnet에 넣으면 신경망에서 순방향 전파를 수행가능하다. 적절한 타입의 input 객체가 있다면 output = alexnet(input)으로 순방향 전파가 가능하다.
하지만 신경망은 초기화되지 않았기 때문에 입력은 신경망을 지나면서 엉뚱한 결과로 나타난다. 즉 가중치들이 현재 훈련되어 있지 않기 때문이다.
resnet
resnet101 함수를 사용하여 계층 수가 101개인 컨볼루션 신경망을 만들어볼 것이다. 계층수가 이렇게 많은 경우는 잔차 신경망이 만들어지기 전까지 훈련에 어려움이 있었다. 내려받은 resnet101모델을 확인해보면 신경망 구조의 세부를 알 수 있다. 코드의 각 줄에서 흔히 층, layer라고 부르는 modules를 사용하고 있음을 볼 수 있다.
이미지는 우선적으로 전처리가 필요하고 동일한 숫자 범위 안에 색상값이 들어올 수 있도록 크기 조정이 필요하다.
from torchvision import transforms
# 전처리
preprocess = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]
)
])
# 예제 코드는 입력 이미지의 크기를 256 x 256으로 조정
# 중심으로부터 224 x 224로 잘라냄
# 텐서로 자료구조 전환
# 그리고 지정된 평균과 표준편차를 가지도록 RGB를 정규화from PIL import Image
# bobby.jpg 입력으로 넣기 위해 불러오기
img = Image.open(".../bobby.jpeg")
img_t = preprocess(img) # 위에 만든 전처리 객체에 이미지를 넣어 전처리
batch_t = torch.unsqeeze(img_t, 0) # 3,4장에서 다시 볼 것
# shape를 보니 입력데이터의 수를 나타내는 첫번째 size요소를 부여한 것 같다.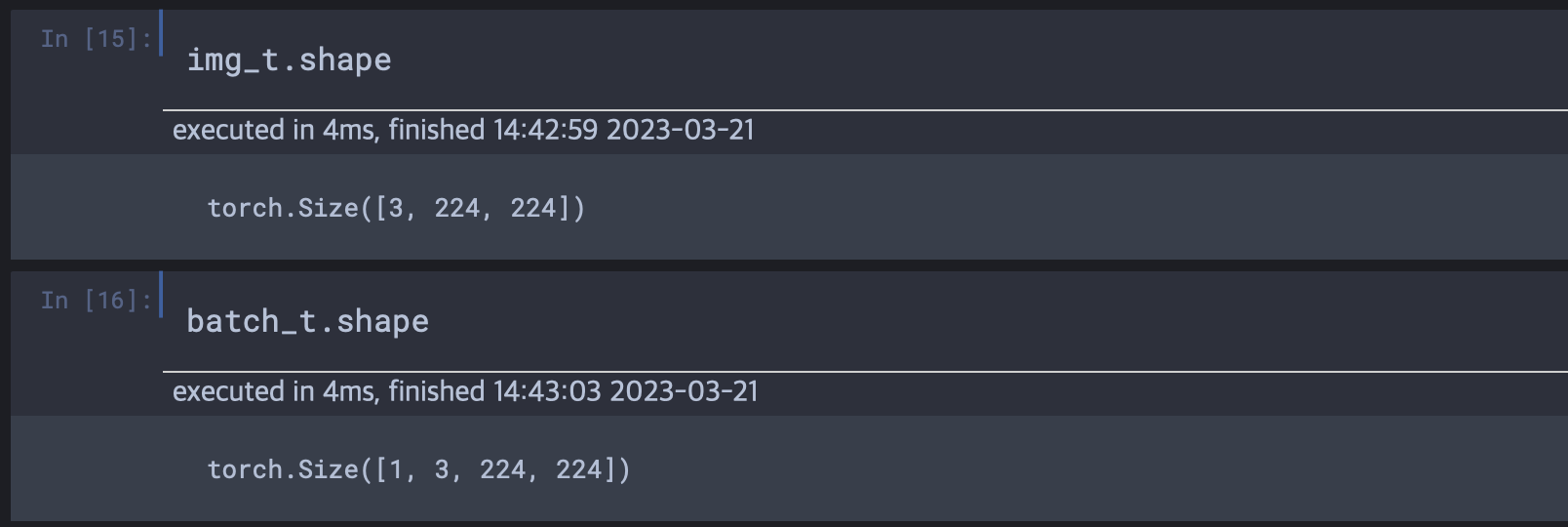
실행
딥러닝 사이클에서 훈련된 모델에 새로운 데이터를 넣어 결과를 보는 과정을 추론(inference)이라고 한다. 추론을 수행하기 위해서는 신경망을 eval 모드로 설정해야한다.
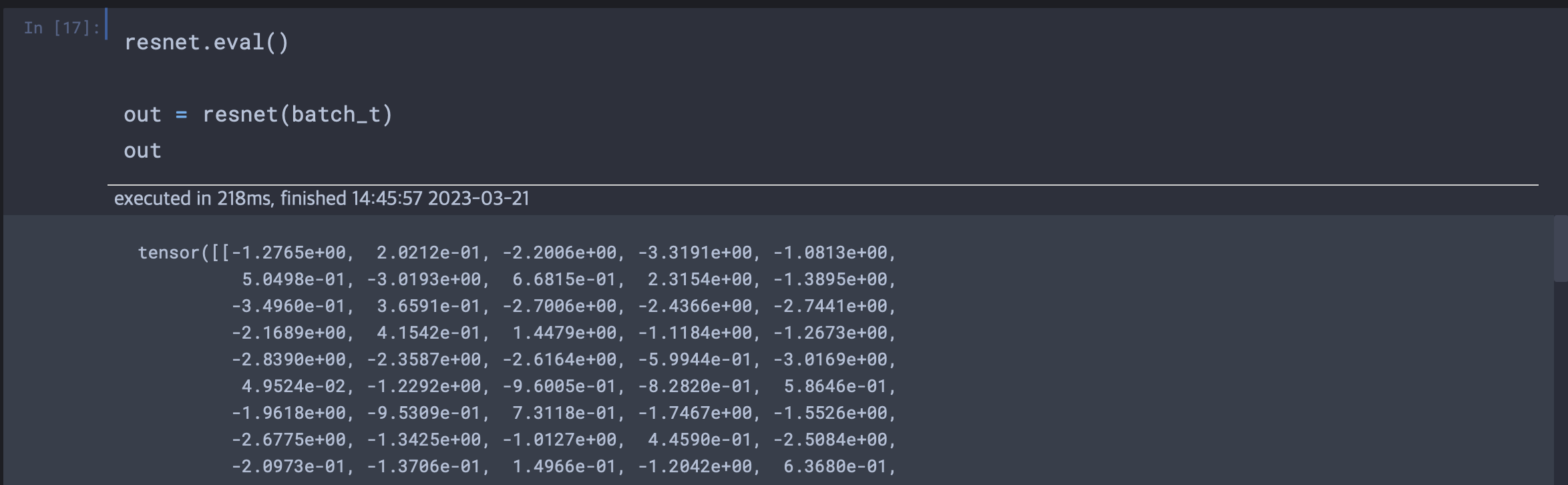
4,450만 개에 이르는 파라미터에 관련된 연산이 실행되어 1,000개의 스코어를 만들어 냈고 점수 하나 하나는 이미지넷 클래스에 각각 대응된다. 이제 점수가 가장 높은 클래스의 레이블만 찾으면 된다. 레이블은 모델이 이미지에서 무엇을 봤는지를 우리에게 알려준다.
책과 다르게 구글 이미지의 치와와 사진을 이용하였으며, 책과 달랐던 부분은 index의 첫번째가 아닌 두번째요소에 index정보가 담겨있었다. 그러므로 코드를 약간 수정하여 반영하였다.

with open('.../imagenet_classes.txt') as f:
labels = [line.strip() for line in f.readlines()]
# imagenet_classes.txt의 본인의 파일 경로를 넣어야 함.
index = torch.max(out, 1)
# 1000개의 레이블중 최상위 점수에 해당하는 레이블정보를 index변수에 담기
percentage = torch.nn.functional.softmax(out, dim=1)[0] * 100
labels[index[1]], percentage[index[1]].item()
# 해당하는 레이블과, 그에 대한 확률을 나타냄

torch.sort로 하여금 인덱스의 점수순 정렬을 하여 배열에서 값을 기준으로 오름차순이나 내림차순으로 정렬한 후 값과 인덱스를 볼 수 있다.
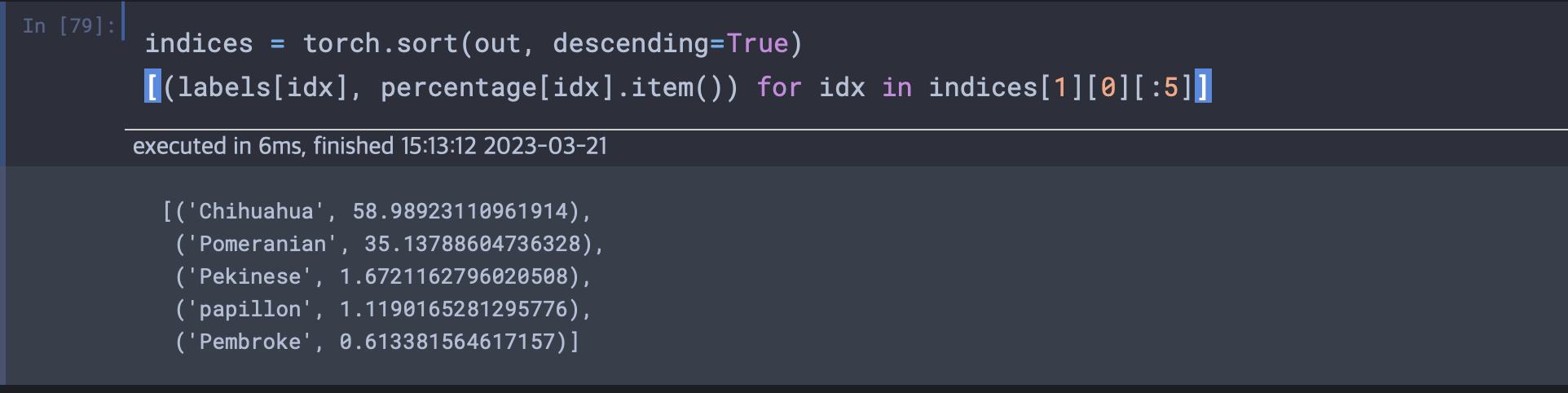
책의 실습에서는 리트리버사진을 활용한 결과 4번째 순위까지는 강아지가 나왔는데, 다섯번째 결과는 테니스공이었다. 인간과는 다른 관점임을 이런 순위를 통해 확인 가능하며, 나의 실습 결과에서는 그래도 모두 강아지가 나타났다.
가짜 이미지를 만드는 사전 훈련된 모델
우리가 유명한 예술가의 잃어버린 작품에 대해 위조품을 만들어 파는 사기꾼이라 가정할 때, 우리가 만든 초기의 위조품은 모조품인 것이 쉽게 들통날 것이다. 전문가의 피드백을 받아 명호가하게 방향을 잡아 위조품 제작의 결과를 계속 개선해나간다면, 언젠가는 우리 그림과 진짜 그림을 구분해내지 못할 것이다.
GAN 게임
위에 설명한 내용은 딥러닝 분야에서는 GAN 게임으로 알려져 있다. GAN은 생성적 적대 신경망(Generative Adversarial Network)의 약자로 용어대로 만들어지고, 경쟁하는 신경망이다. 우리의 중요한 목표는 원본과 구별할 수 없는 합성된 그림을 만들어 내는 것이다.
이 과정에서 화가 역할을 하는 것이 생성자 신경망이며 임의의 입력에 대해 사실같은 이미지를 만들어내는 작업을 수행한다. 식별자신경망은 도덕성을 갖추지 않는 미술 작품 감별사가 되어 생성자가 조작한 이미지인지 실제 이미지인지 판별해주는 역할이다.
생성자의 궁극적 목표는 진짜와 가짜 이미지를 구분 불가능하게 식별자를 속이는 일이며, 우선 생성자는 렘브란트 초상화와는 전혀 닮지 않은 눈이 세 개 달린 괴물을 하나 만들어 낸다. 식별자는 쉽게 구분하게 된다. 훈련 과정이 진행되며 식별자로부터 얻은 정보를 토대로 생성자는 점점 개선된다. 훈련이 끝날 즈음이면 생성자는 그럴싸한 가짜 이미지를 생성해낸다. 식별자는 더 이상 진짜와 가짜를 구별할 수 없다.
Cycle GAN
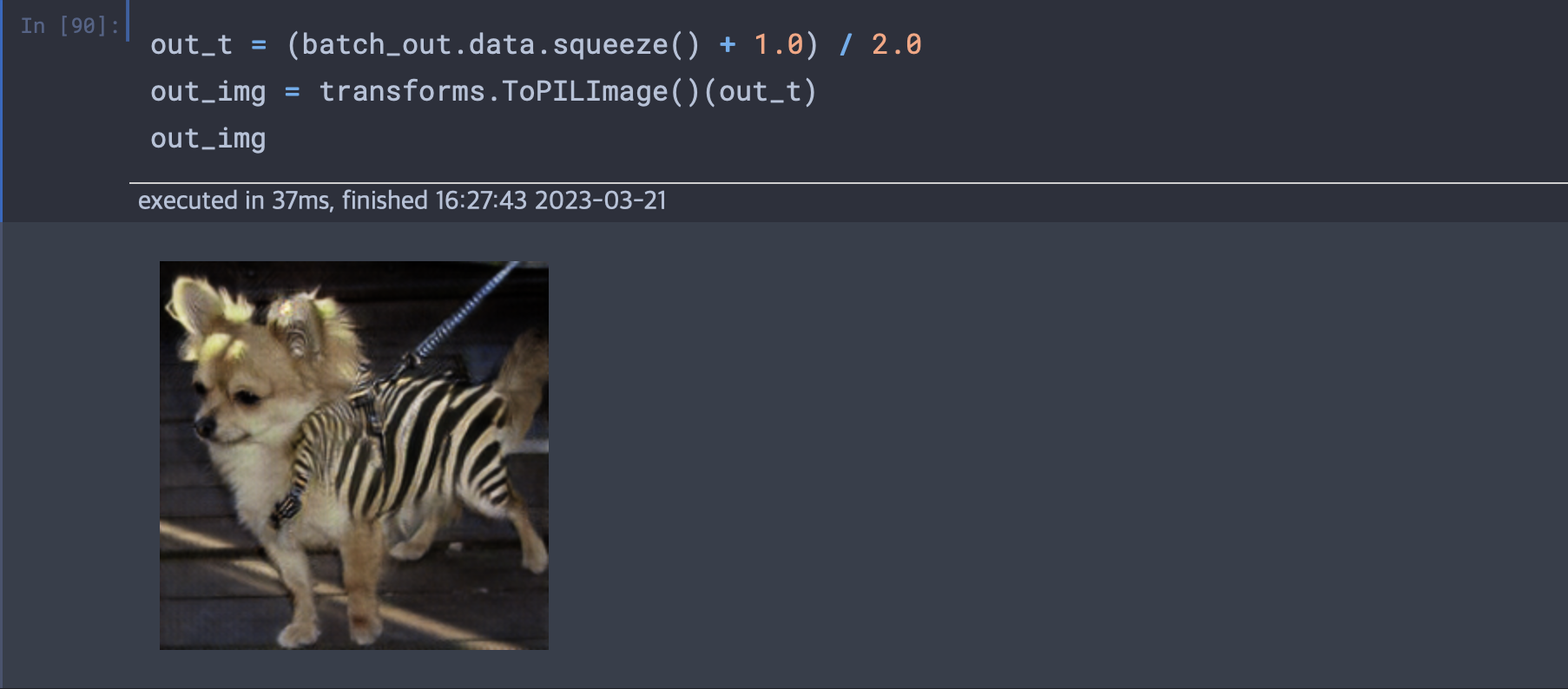
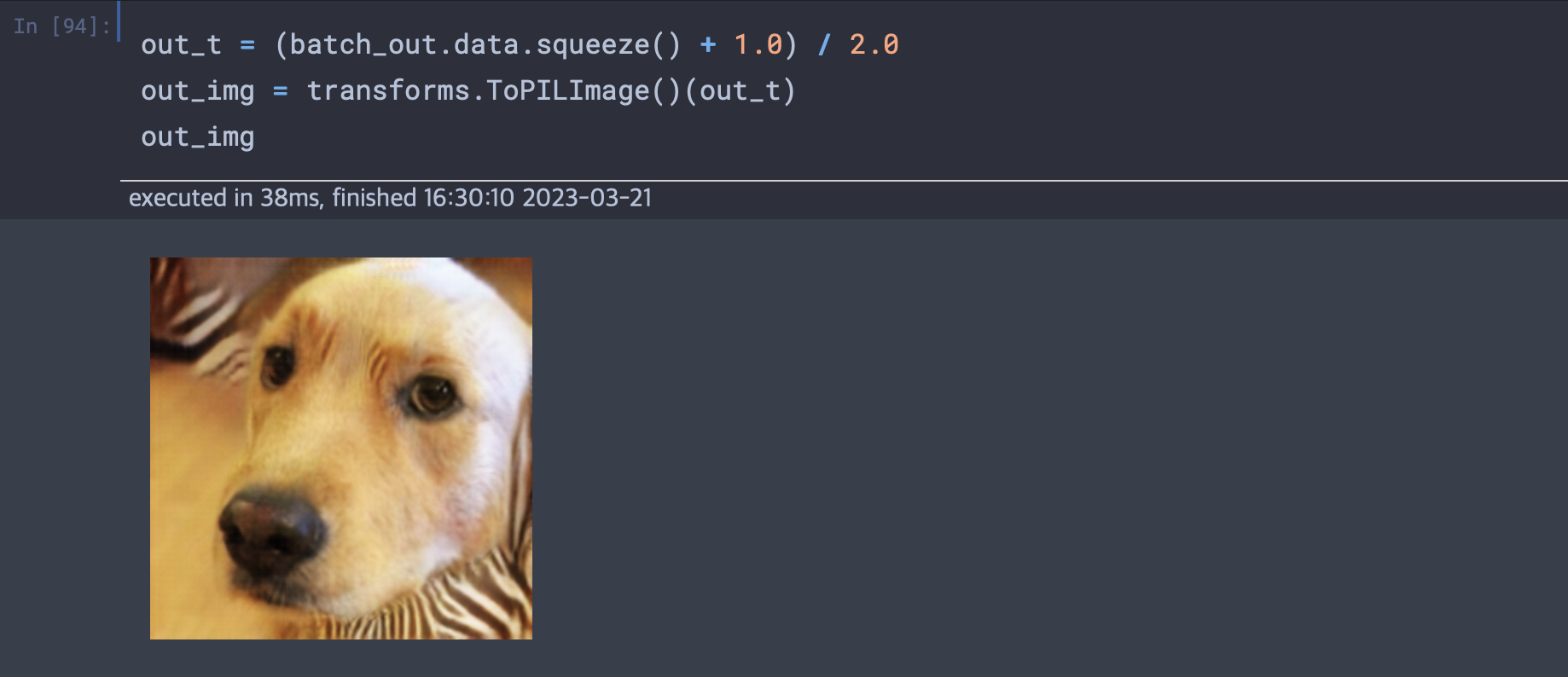
사이클 GAN은 훈련셋에서 매칭된 쌍을 제공하지 않아도 한 도메인에 대한 이미지를 다른 도메인으로 바꿔준다. 말을 얼룩말로 바꾸거나, 얼룩말을 말로 바꾸는 것이 가능하다.
(말, 얼룩말의 사진은 입력으로 주어져야 하지만 사진의 구도등 대응되는 사진끼리 같아야할 요소들이 요구되지 않는다.)

두 개의 개별 생성자 신경망이 있고 마찬가지로 두 개의 개별 식별자 신경망이 있다. 첫 번째 생성자는 말 이미지 분포 값을 가진 그림에서 시작해서 얼룩말 이미지의 분포 값과 일치하는 이미지를 만들도록 학습한다.(식별자가 구분 못할 때 까지) 동시에 만들어진 가짜 얼룩말 사진이 다른 생성자로 전달되어 맞은 편의 식별자가 판별하도록 보내는 사이클이 있다.
- 실습에 이용된 netG모델의 생성자 모델이 이미 horse2zebra데이터셋을 사용해 사전 훈련되어있다.
장면을 설명하는 사전 훈련된 신경망
자연어와 관련된 모델을 직접 체험하기 위해 뤄티엔 루오가 만든 이미지 캡션 모델을 사용하도록 한다. 캡션 모델은 크게 반으로 나뉜 신경망이 연결되어 있다. 첫 번째는 장면을 숫자로 표현하는 법을 학습하는 신경망이며, 두 번째 신경망의 입력으로 사용한다. 두 번째는 순환 신경망으로 숫자로 기술된 정보로 연관된 문장을 만드는 역할을 한다.
- 두 번째 모델이 "순환"신경망이라 불리우는 이유는 출력을 만드는 방식에서 기인한다. 순방향으로 값이 전달될 때 이전 순방향 전달의 출력값을 함께 넣기 때문이다. 이로 인해 만들어진 단어가 다음 단어에 영향을 줄 수 있다.
토치 허브
딥러닝 초기부터 사람들은 사전 훈련된 모델을 공개해왔다. 토치비전의 경우 인터페이스가 깔끔한 경우이지만 사이클GAN이나 뉴럴토크2에서 본 것처럼 사람들은 저마다 다른 인터페이스를 디자인하기도 한다.
파이토치는 편의를 위해 토치 허브를 소개했다. 제작자가 깃허브에 모델을 공개할 수 있고 가중치의 포함 여부를 선택할 수 있으며 파이토치가 이해하는 인터페이스를 통해 노출하는 형태였다.
torch.hub 모듈을 사용하여 hubconf.py에 정의된 모듈들을 즉시 로딩할 수 있다.
연습문제
책의 실습 코드와 같이 모델을 구축하여 치와와 사진과 리트리버를 넣었을 때 다음과 같이 표현되었다.