
1학년 (골드 5)
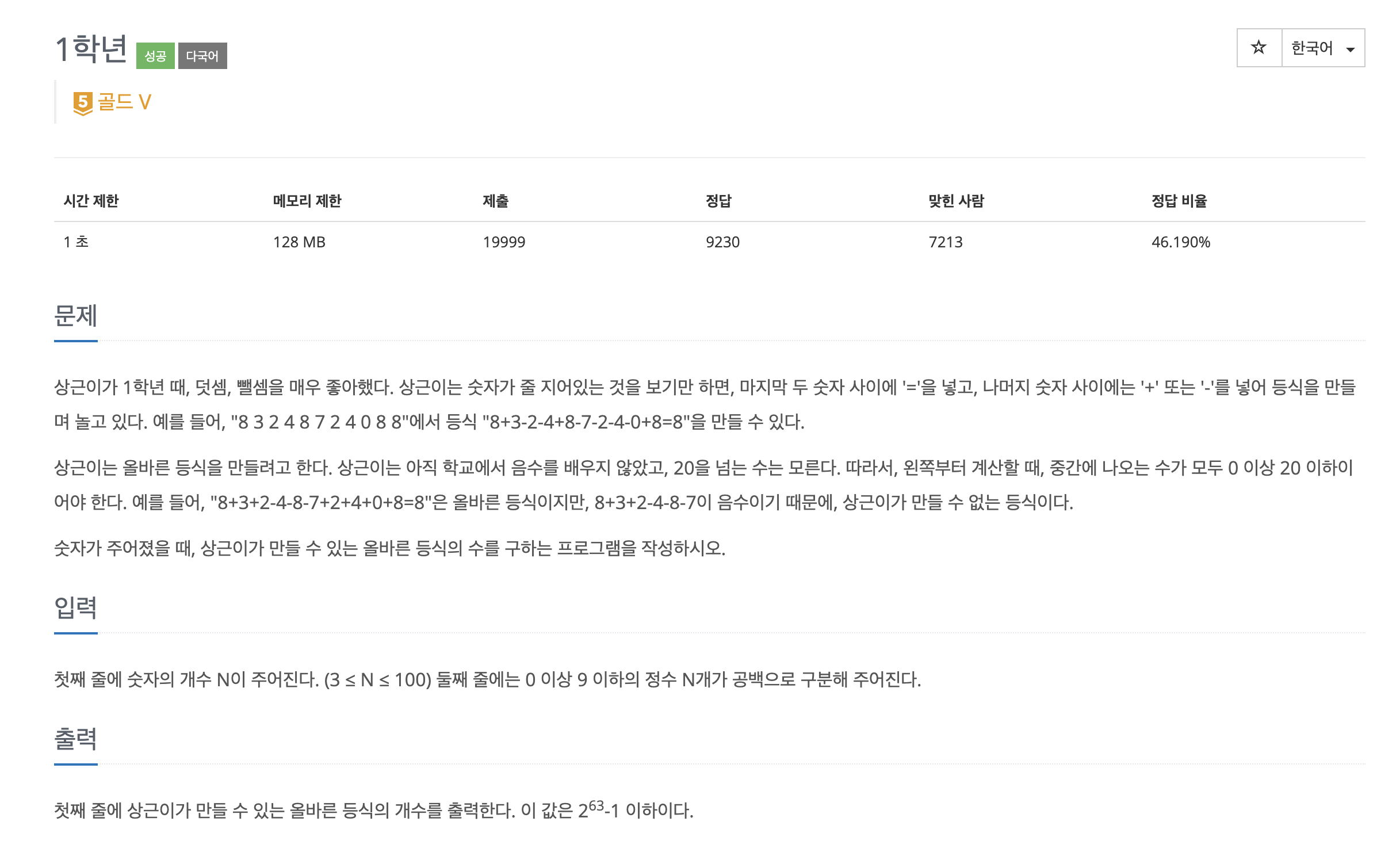
주어진 숫자조합은 순서가 분명히 의미가 있다. 왜냐하면 중간계산 결과가 0이상 20이하여야 한다는 조건 때문이다.
8
11 5
13 9 7 3
17 9 13 5 11 3 7
....
그래서 일단 코딩을 했다. 0 <= 중간ans <= 20 이니까 메모리에 들어오지 않는 것들이 있을 것이다. 또한 이전 계산을 담고있어 중복계산을 지웠다는 생각도 했다. 하지만 출력으로 주어진 범위가 너무 컸다.
처음 예시인
11
8 3 2 4 8 7 2 4 0 8 8
이 입력 조차 마지막 메모리에서는 많은 숫자들을 저장했다. 예제 입력2를 넣어보니 시간이 어마무시하게 오래걸렸다.
 이것은 처음 예시에서 최종 결과 도출을 위해 만들어진 배열이다. 이걸 보고 바로 생각이 들었다. 여기 안의 수는 모두 0과 20사이이며, 중복이 엄청 발생하겠구나 라는 것을 그래서 dp를 0~20수의 범주화로 dp[0]*21로 해서 만약 중간 계산에서 18짜리가 100개 존재한다면 우리는 18에 다음 수를 더하거나 뺀 두개의 수를 index=다음수에 업데이트하면 되겠구나로 풀었다.
이것은 처음 예시에서 최종 결과 도출을 위해 만들어진 배열이다. 이걸 보고 바로 생각이 들었다. 여기 안의 수는 모두 0과 20사이이며, 중복이 엄청 발생하겠구나 라는 것을 그래서 dp를 0~20수의 범주화로 dp[0]*21로 해서 만약 중간 계산에서 18짜리가 100개 존재한다면 우리는 18에 다음 수를 더하거나 뺀 두개의 수를 index=다음수에 업데이트하면 되겠구나로 풀었다.
from sys import stdin
n = int(stdin.readline())
n_lst = list(map(int, stdin.readline().split()))
ans = n_lst.pop()
def new_dp_maker(dp, next_num):
new = [0] * 21
for idx, i in enumerate(dp):
if i > 0:
one = idx + next_num
two = idx - next_num
if 0 <= one <= 20:
new[one] += i
if 0 <= two <= 20:
new[two] += i
return new
start = n_lst[0]
dp = [0] * 21
dp[start] = 1
for idx, i in enumerate(n_lst):
if idx == 0:
pass
else:
dp = new_dp_maker(dp, i)
print(dp[ans])
dp풀이의 핵심은 경험을 기반한 힌트찾기라고 생각한다. 일단 하드코딩을 해보며 문제의 핵심에 다가가야할 것 같다.
최소 힙 (실버 2)
 파이썬으로 풀기에는 너무 쉬운 문제이다. 라이브러리로 풀면 되니, 풀이는 금방인데 힙을 언제쓰는지, 힙 공부할겸 문제도 풀었다. 힙 같은 경우 우선순위 큐에서 사용되는 도구이므로 잘 이해해놓도록 하자. 느슨한 정렬을 가진다. heapify_up, down에 대한 개념이 중요하다.
파이썬으로 풀기에는 너무 쉬운 문제이다. 라이브러리로 풀면 되니, 풀이는 금방인데 힙을 언제쓰는지, 힙 공부할겸 문제도 풀었다. 힙 같은 경우 우선순위 큐에서 사용되는 도구이므로 잘 이해해놓도록 하자. 느슨한 정렬을 가진다. heapify_up, down에 대한 개념이 중요하다.
heapify_up의 경우 힙에 데이터가 들어왔을 때 트리기준 가장 아랫단에, 배열기준 가장 오른쪽에 추가되는데 이때 부모노드와 비교하여 부모노드와의 교환이 계속해서 일어난다. 최소 힙이므로, 만약 자식노드가 더 작다면 교환이 일어난다. 교환이 일어날 경우 교환이 일어난 부모노드 위치가 다시 자식노드가 되어 위로 전파된다.
heapify_down의 경우 힙에서 pop()을 수행했을 때 일어난다. 보통 값을 삭제할 때, heap[0]의 삭제만 허용되며 이 값은 최소 힙에서는 최솟값을 의미한다. 값이 삭제되면 맨 아래의, 가장 멀리있는 요소가 꼭대기 노드에 옮겨 들어오게 되고 이때부터 heapifiy_down이 일어난다. 자식노드와 옮겨 들어오게 된 부모노드와의 비교이며, 자식노드 둘중 하나라도 더 작은 수를 가진 노드가 있다면 가장 작은 수를 가진 자식노드와 교환이 일어난다. 그리고 교환된 자식노드에 대해 동일한 로직으로 아래로 전파된다.
from sys import stdin
import heapq
n = int(stdin.readline())
heap = []
for _ in range(n):
order = int(stdin.readline())
if order == 0:
if len(heap) == 0:
print(0)
else:
value = heapq.heappop(heap)
print(value)
else:
heapq.heappush(heap, order)PriorityQueue vs heapq
결국 우선순위 큐를 이해하고 사용하기 위해 heapq를 보고 이해했는데, 사실 파이썬에서는 queue 라이브러리에서 우선순위 큐를 제공한다.(from queue import PriorityQueue) 하지만 이 라이브러리는 멀티스레딩 환경에서 안전하게 사용가능하므로, 우선순위 큐를 구현하기 위해서는 heapq의 사용이 권장된다.
센서 (골드 5)
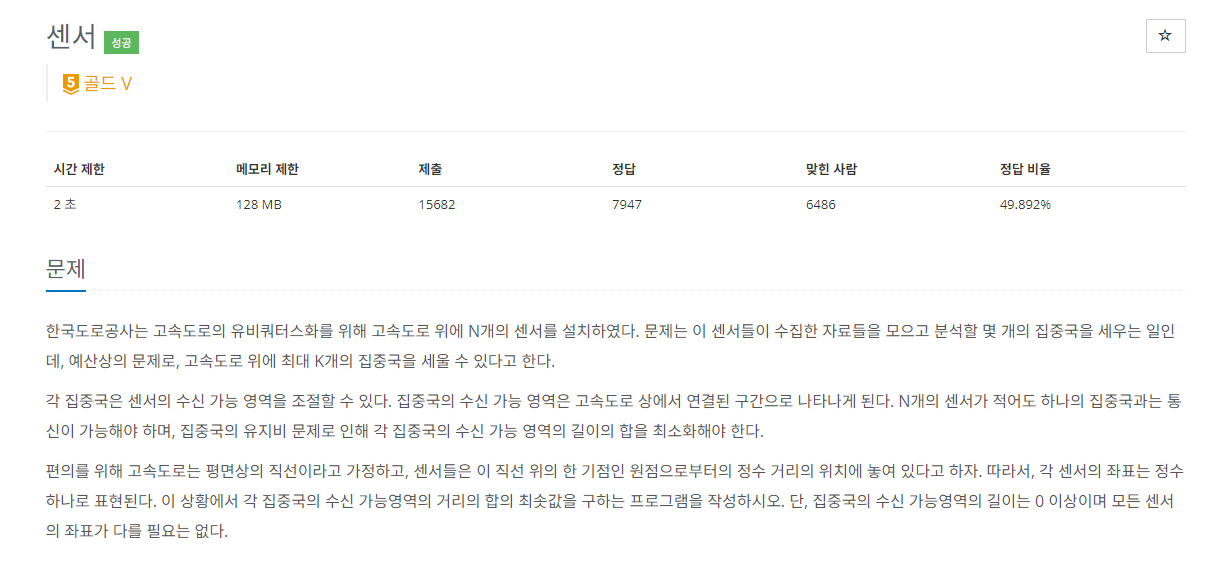 문제의 이해가 어려우므로, 예시를 직접 그려보며 이해하는 것이 빠르다.
문제의 이해가 어려우므로, 예시를 직접 그려보며 이해하는 것이 빠르다.
 예시1의 모식도이다. 집중국의 범위를 구하라는 것이지만 결국 어떻게 센서를 n개의 최적의 범위의 묶음으로 묶을 수 있을까에 대한 문제이다.
예시1의 모식도이다. 집중국의 범위를 구하라는 것이지만 결국 어떻게 센서를 n개의 최적의 범위의 묶음으로 묶을 수 있을까에 대한 문제이다.
결국 센서간의 거리를 어떻게 다루느냐에 대한 문제이므로 각 센서들의 거리만 가져와보자.
2, 3, 1, 2 이다. 여기서 만약 위의 그림처럼 자르게 된다면 3을 무시할 수 있다. 2개의 집중국은 한번의 칼질을 제공하며, 그 칼질은 가장 높은 수를 자르게 되었다.
두번째 예시로 직감을 로직으로 확정할 수 있었다. 거리를 모두 나열하고 집중국개수 - 1번의 max거리값 칼질로 두번째 예시도 구할 수 있다. 만약 중복이 된다면? max거리값이 2인데 2가 여러개라면? 잘 생각해보면 상관이 없다.
from sys import stdin
n_sensor = int(stdin.readline())
n_house = int(stdin.readline())
sensor_lst = list(map(int, stdin.readline().split()))
# 중복제거
sensor_lst = list(set(sensor_lst))
# 정렬
sensor_lst.sort()
dist_lst = []
for idx, i in enumerate(sensor_lst):
if idx + 1 < len(sensor_lst):
dist = sensor_lst[idx + 1] - i
dist_lst.append(dist)
for i in range(n_house - 1):
if len(dist_lst) > 0:
dist_lst.remove(max(dist_lst))
print(sum(dist_lst))
아래의 for문에서 if len(dist_lst) > 0: 를 추가하지 않아서 ValueError가 처음 제출 때 발생했다. 이는, 만약 집중국 개수가 넘쳐흐를 때 만약 칼질이 무제한이라면 우리는 dist_lst에 요소도 없는데 .remove를 돌린다는 것이다. .remove(1) 인데 1이 없다면 에러가 뜨기에 if문으로 처리했다.
for i in range(n_house - 1):
if len(dist_lst) > 0:
dist_lst.remove(max(dist_lst)) 