22일차
오늘의 목표

정규표현식

로그인의 역사
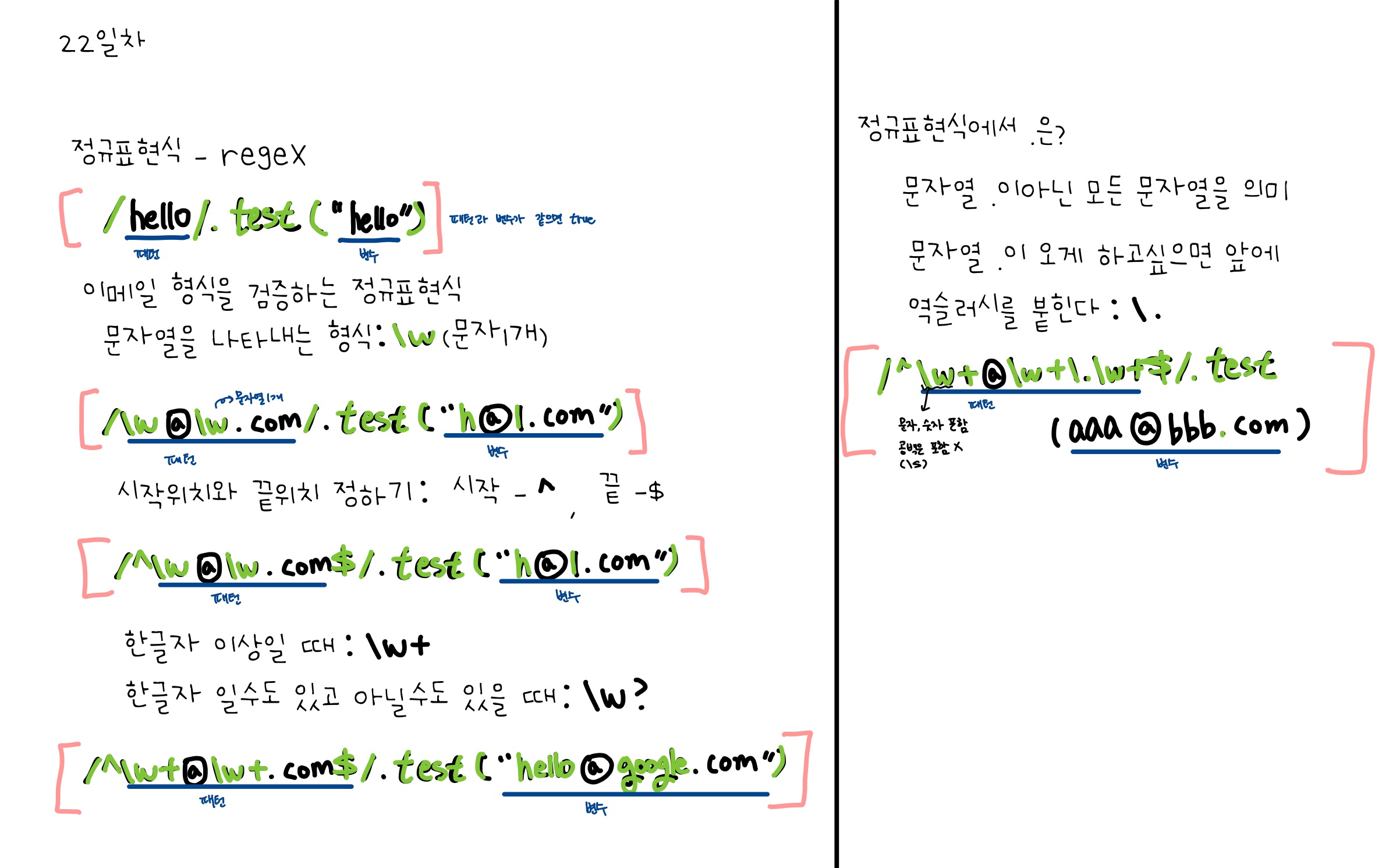
첫번째 로그인
브라우저에서 특정 email과 password를 가지고 로그인을 하게되면 백엔드로 loginAPI 요청이 날라가게 되고, 백엔드에서는 해당 유저가 있는지 DB에 확인 후 있으면 session에 저장해두게 됩니다.
그 후 특정한 id를 부여해서 브라우저로 보내줍니다.단점 : 한번에 여러명의 정보를 받기엔 한계가 있다. 이를 보완해주기 위해서 백엔드 컴퓨터를 scale-up 해주었다.
scale-up
컴퓨터의 성능(cpu, memory 등)을 올려주는 것
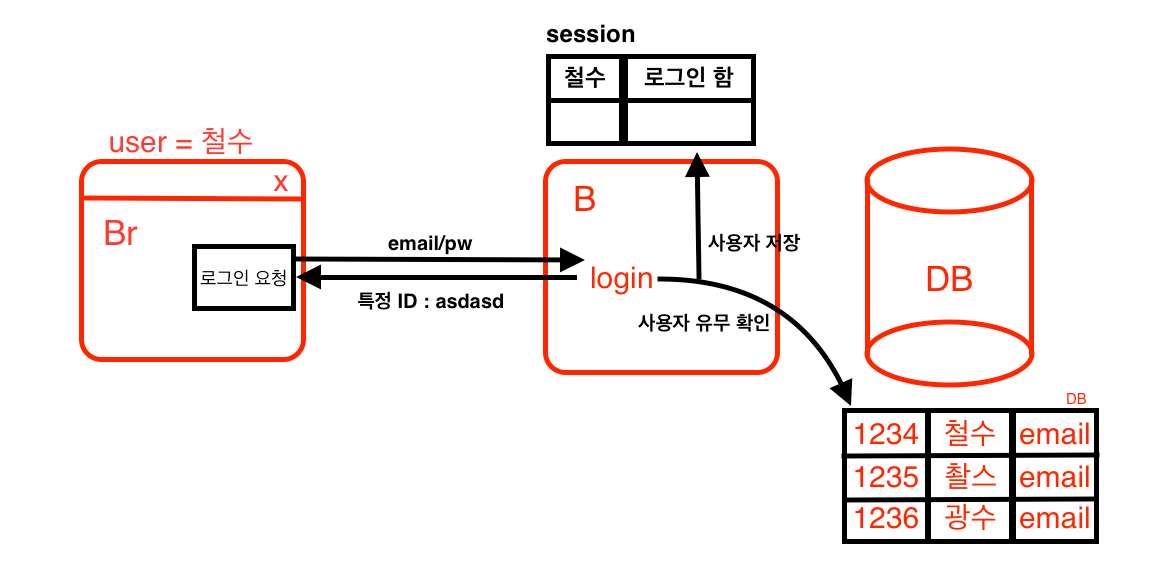
두번째 로그인
백엔드 컴퓨터를 복사하는 방법
이 방법은 유저의 정보가 담기는 백엔드 컴퓨터를 복사해 여러대의 컴퓨터로 서버의 부하를 분산해주었다.단점 : 컴퓨터를 복사할때는 세션까지 scale-out이 안되기때문에 기존의 로그인 정보를 가지고 있던 백엔드 컴퓨터가 아니면, 로그인 정보가 없다.
scale-out
똑같은 성능의 컴퓨터를 추가하는 것
세번째 로그인
두번째 로그인에서 세션까지 scale-out해오지 못했던 문제점을 보완
현재 많이 사용되는 방법
로그인 정보를 DB에 저장
첫번째 로그인의 역사에서 서버 부하가 일어난 것처럼 DB의 부하가 일어남 -> 데이터를 쪼개면서 해결데이터를 쪼개는 방법
- 수직으로 쪼개는 수직파티셔닝
- 수평으로 쪼개는 수평파티셔닝(샤딩)
단점: : 데이터들이 디스크에 저장됨 -> 안전하지만 느림
scrapping : disk에 저장된 데이터를 추출해 오는 현상(DB를 긁는다)
해결방법 : Redis DB에 저장
Redis
메모리에 저장해두는 임시 데이터 베이스
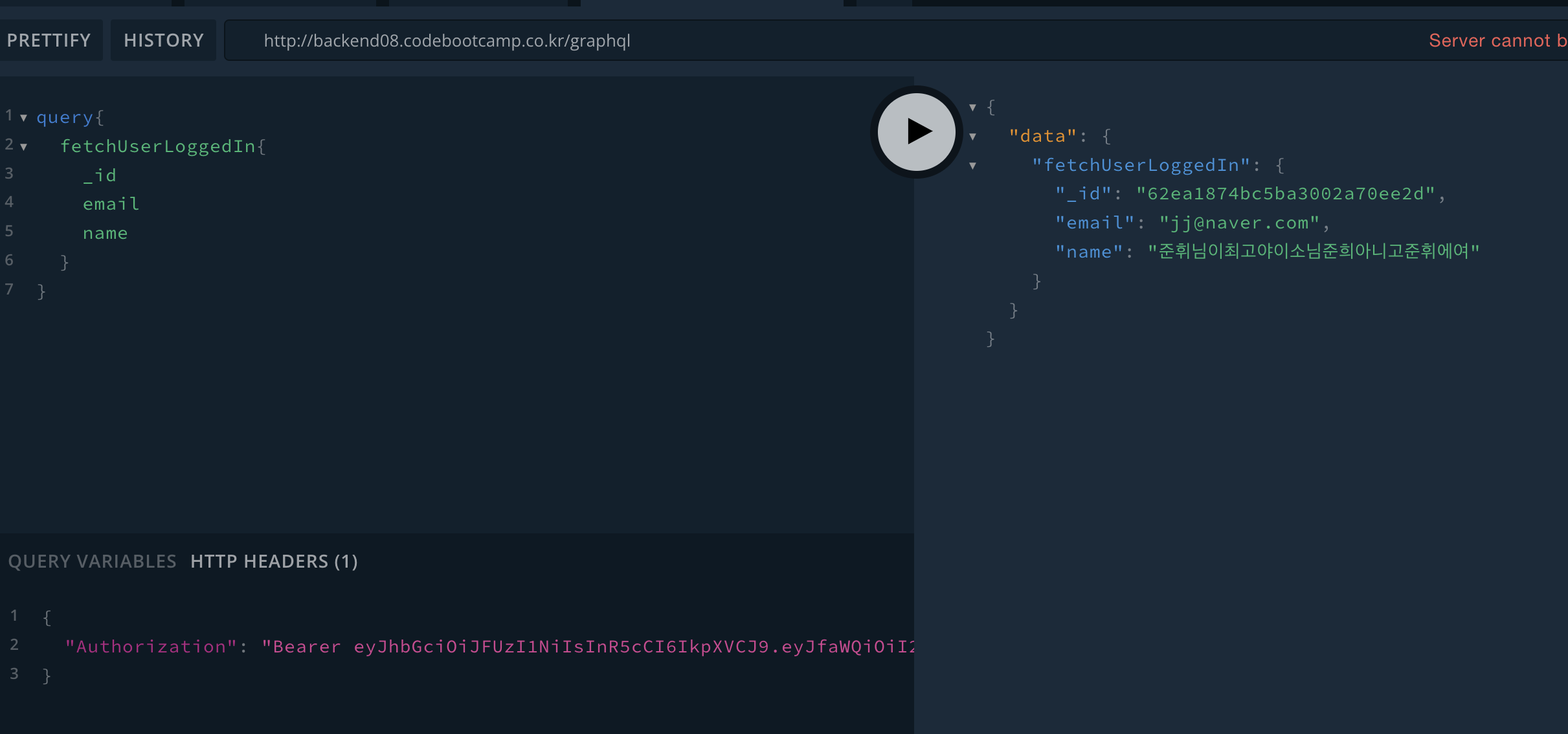
JWT 로그인
네번째 로그인의 역사
인가
토큰 받은걸 전달해서 데이터를 받아오는 과정
응애