JAVA
Collections Framework (Container)
ArrayList
한 번 정해진 배열의 크기를 변경할 수 없는 단점을 보완.
add시킨 값을 가져올 때 그 값을 원래의 데이터타입으로 형변환을 해줘야한다.
-> 좀 별로. so, ArrayList< String> 이라고 적기.
중복 허용 / 순서대로 저장
배열의 경우, 값의 개수를 구할 때 .length를 사용, 인덱스 번호를 사용.
for(int i=0; i<arrayObj.length; i++){
System.out.println(arrayObj[i]);ArrayList의 경우, 메소드 size를 사용, get(인덱스 번호)를 사용.
for(int i=0; i<al.size(); i++){
System.out.println(al.get(i));제너릭을 사용하면 사용할 데이터 타입을 인스턴스를 생성할 때 지정할 수 있기 때문에, 데이터를 꺼낼 때 (String val = al.get(i);) 형변환을 하지 않아도 된다.
ArrayList al = new ArrayList();
al.add("one");
al.add("two");
al.add("three");
for(int i=0; i<al.size(); i++){
System.out.println(al.get(i));
}HashSet
중복 허용X / 순서 보장X
각각은 고유하다.
집합.
public static void main(String[] args) {
HashSet<Integer> A = new HashSet<Integer>();
A.add(1);
A.add(2);
A.add(3);
HashSet<Integer> B = new HashSet<Integer>();
B.add(3);
B.add(4);
B.add(5);
HashSet<Integer> C = new HashSet<Integer>();
C.add(1);
C.add(2);
System.out.println(A.containsAll(B)); // A는 B를 포함하고 있니? // false
System.out.println(A.containsAll(C)); // A는 C를 포함하고 있니? // true 응. C는 A의 부분집합이야.
//A + B
//A.addAll(B); // B의 전체를 A에 add한다. A와 B의 합집합.
//A와 B의 교집합
//A.retainAll(B); // A에도 있고 B에도 있는 것만 A에 담겠다. A와 B의 교집합.
//A - B
//A.removeAll(B); // A에 있는 것 중에 B에 있는 걸 뺄게. A에서 B를 뺀 차집합.HashMap
key - 중복허용X / value를 얻어오기 위한 열쇠
value - 중복허용 (한 key에 두개 이상 value가 가능한 것이 아니고, 각각의 key에 중복된(동일한) value 가능)
key를 바꿔주면 그에 상응하는 value가 덮어써짐.
HashMap<String, Integer> a = new HashMap<String, Integer>();
// List,Set 에서는 value값만 정해주면 되니까, 형태를 하나만 지정하면 되는데,
Map은 Key가 포함됨. So, <key형태, value형태> 이렇게 지정해줘야함.맵에 저장된 데이터를 열거하는 방법 두가지
맵 자체는 이터레이션 기능이 없기 때문에, 맵의 데이터를 가지고 있는 셋을 만들었고,
셋에 들어가있는 데이터 타입은 Map.Entry.
각각의 key는 getKey()로 알아내고, 각각늬 value는 getValue()로 알아낸다.
iteratorUsingForEach(a);
static void iteratorUsingForEach(HashMap map){
Set<Map.Entry<String, Integer>> entries = map.entrySet();
for (Map.Entry<String, Integer> entry : entries) {
System.out.println(entry.getKey() + " : " + entry.getValue());
}
}엔트리셋을 이용해서 맵에 대응되는 셋을 엔트리스에 담았고, 엔트리스는 셋이기 때문에 이터레이터를 통해서 값을 반복할 수 있는 반복자를 얻어낼 수 있음.
그걸 i라는 변수에 담음. 그 다음 i.hasNext()을 하면 이터레이터 안에 조회할 데이터가 존재하는지 체크, 반복문이 돌아감.
i.next()를 하게되면 이터레이터 안에 저장되어있는 조회할 값들을 하나하나 꺼내게 되고, 꺼내진 값은 맵엔트리라는 데이터타입을 가지고 있고 맵엔트리는 겟키와 겟벨류를 가지고 있기 때문에 이 두개의 api를 이용해서 우리가 원하는 값들을 키와 벨류의 값을 조회할 수 있게 됨.
iteratorUsingIterator(a);
static void iteratorUsingIterator(HashMap map){
Set<Map.Entry<String, Integer>> entries = map.entrySet();
Iterator<Map.Entry<String, Integer>> i = entries.iterator();
while(i.hasNext()){
Map.Entry<String, Integer> entry = i.next();
System.out.println(entry.getKey()+" : "+entry.getValue());
}
}컬렉션을 사용하는 이유 중의 하나는 정렬과 같은 데이터와 관련된 작업을 하기 위해서다.
정렬
Collections.sort(computers); // Collections가 가진 클래스 메소드 중
sort(List의 정렬을 수행함)를 이용해서 정렬을 수행하라.
System.out.println("\nafter");
i = computers.iterator();
while(i.hasNext()){
System.out.println(i.next());
}
제네릭 (Generic)
클래스를 정의할 때는 info의 데이터 타입을 확정하지 않고 인스턴스를 생성할 때 데이터 타입을 지정하는 기능
클래스 내부에서 사용할 데이터 타입을 외부에서 지정하는 기법
메서드 안에서의 매개변수와 비슷하게 작용됨.
제네릭은 생략이 가능함.
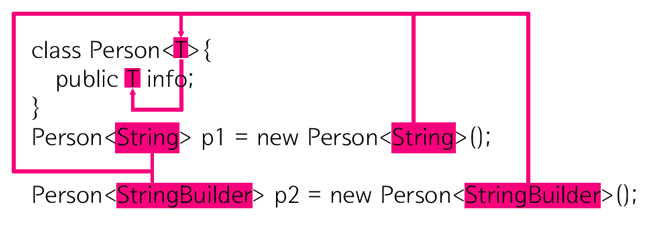
< T>라는 데이터타입은 존재하지 않음.
아래 코드의 <> 안에 지정된 데이터 타입에 의해서 결정됨.
복수의 제너릭을 사용할 때는 < T,S>처럼 콤마를 찍어주고 서로 이름이 달라야함. 보통 관습적으로 Type을 나타내는 T부터 뒤 알파벳
레퍼런스형만 올 수 있음. 참조데이터 타입. 기본데이터타입(int, char, double) 등등은 올 수 없음. -> 기본데이터타입을 객체인 것 처럼 만들 수 있는 객체인 wrapper class을 사용.
class Main {
public static void main(String[] args) {
EmployeeInfo e = new EmployeeInfo(1);
Integer i = new Integer(10); // 숫자 10을 의미하는 하나의 인스턴스를 만듦.
Person<EmployeeInfo, Integer> p1 = new Person<EmployeeInfo, Integer>(e, i); // int를 Integer로 바꿔줌.
System.out.println(p1.id.intValue());
}
}제네릭의 제한
클래스를 정의할 때는 info의 데이터 타입을 확정하지 않고 인스턴스를 생성할 때 데이터 타입을 지정하는 기능 이기 때문에 모든 것이 다 들어올 수 있음.
class Person T extends info{ // extends를 사용해서 Info라는 클래스의 자식들만 T로 올 수 있음.super : extends랑 다르게 부모를 제한.
람다식(Lambda expression)
"식별자 없이 실행 가능한 함수" 즉, 함수의 이름을 따로 정의하지 않아도 곧바로 함수처럼 사용할 수 있는 것 (익명 함수)
-문법이 간결.
-But, 재사용 불가, 비슷한 메소드를 중복되게 생성할 가능성이 있어서 지저분해질 수 있음.
'→'의 의미는 매개변수를 활용하여 {}안에 있는 코드를 실행한다는 것입니다.
[기존의 메소드 형식]
반환타입 메소드이름(매개변수 선언) {
수행 코드 블록
}
[람다식의 형식]
(매개변수 선언) -> {
수행 코드 블록
}:: 이중 콜론 연산자 - 매개변수를 중복해서 사용하고 싶지 않을 때 사용하곤 합니다.
스트림(stream)
- '데이터의 흐름'
- 컬렉션.stream
네트워킹
-
네트워킹(Networking)
- 두 대이상의 컴퓨터를 케이블 또는 인터넷으로 연결하여 네트워크를 구성하는 것을 말합니다.
-
네트워크의 기본적인 개념
- 클라이언트(Client) / 서버(Server) (컴퓨터간의 관계를 역할로 구분)
- 서버 : 서비스를 제공하는 컴퓨터, 요청에 응답하는 컴퓨터
- 클라이언트 : 서비스를 사용하게 되는 컴퓨터, 요청을 하는 컴퓨터
IP 주소
- 컴퓨터를 구별하는데 사용된느 고유한 값으로 인터넷에 연결이 되어있는 모든 컴퓨터는 IP 주소를 갖습니다.
URL(Uniform Resource Locator)
- URL은 인터넷에 존재하는 여러 서버들이 제공하는 자원에 접근할 수 있는 주소를 표현하기 위한 것입니다! (우리가 네이버, 구글을 검색할 때도 URL을 이용하여 접근을 하는 것이죠!)
API(Application Programming Interface)
- 응용 프로그램에서 사용할 수 있도록 운영체제나 프로그래밍 언어가 제공하는 기능을 제어 할 수 있게 해주는 인터페이스를 의미합니다. client-server 관점에서 API는 요청과 응답의 형식에 대한 약속입니다.
객체지향 프로그래밍
객체 : 변수와 메소드를 그룹핑한 것.
Calculator c1 = new Calculator();
:카큘레이터라는 변수를 새로 만들어서 c1이라는 변수에 담았는데, 그 변수는 카큘레이터라고하는 객체를 담을 수 있는 데이터 형식을 가지고 있는 변수여야한다.
