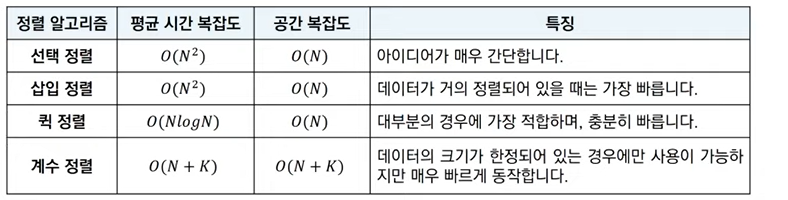
정렬 알고리즘
: 데이터를 특정 기준에 따라 순서대로 나열
일반적으로 문제 상황에 따라 적절한 정렬 알고리즘이 공식처럼 사용됨
표준 정렬 라이브러리는 최악의 경우에도 O(NlogN)을 보장
정렬 알고리즘 비교 테이블
선택 정렬
처리되지 않은 데이터 중 가장 작은 데이터를 선택해 맨 앞 데이터와 바꾸기 반복
동작 예시
처리되지 않은 데이터 중 가장 작은 데이터는 2이므로, 맨 앞 데이터인 9와 자리를 변경
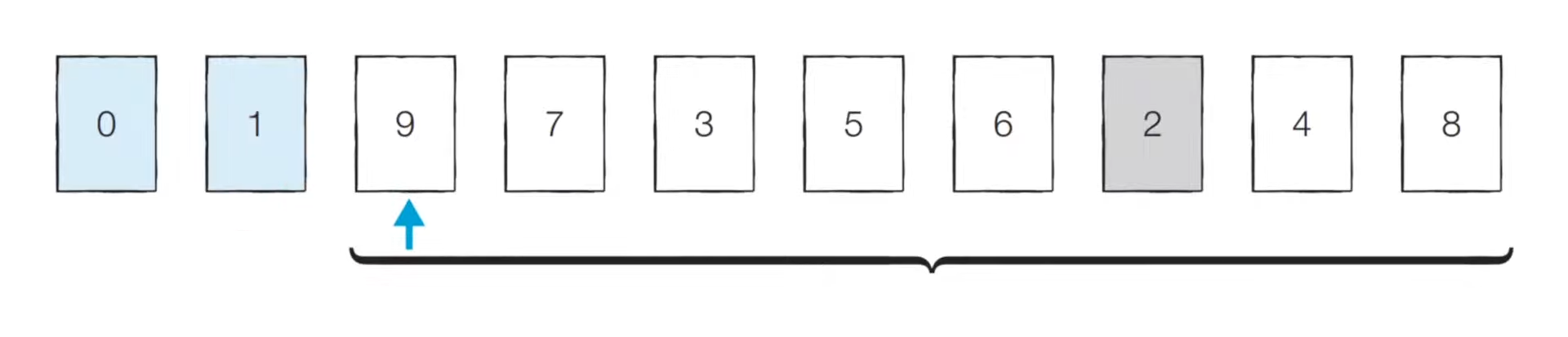
→ 0 1 2 7 3 5 6 9 4 8로 정렬되고, 같은 방식으로 정렬 반복
맨 마지막은 처리 안 해도 자동으로 정렬됨
탐색 범위는 반복 시마다 줄어들고, 매번 가장 작은 데이터를 찾기 위해 탐색 범위만큼 데이터를 하나씩 확인하는 것으로, 즉 매번 선형 탐색을 수행하게 됨
이중 반복문으로 구현 가능
시간 복잡도
소스코드
a = [7, 5, 9, 0, 3, 1, 6, 2, 4, 8]
for i in range(len(a)):
min_idx = i
for j in range(i+1, len(a)):
if a[min_idx] > a[j]:
min_idx = j
a[i], a[min_idx] = a[min_idx], a[i] # 스왑- 파이썬은 마지막 줄처럼 별도의 함수 없이도 한 줄로 스왑 가능 (자바는 temp 써먹던 거)
삽입 정렬
처리되지 않은 데이터에서 하나씩 골라 적절한 위치에 삽입
앞쪽에 있는 원소들은 이미 정렬되어 있다고 가정, 뒤쪽의 원소가 그 앞쪽 데이터 중 적절한 위치로 들어가는 것
들어갈 수 있는 자리는 왼쪽의 데이터의 왼쪽, 오른쪽뿐으로,
차례대로 왼쪽의 데이터와 비교해서 자신이 왼쪽 데이터보다 작으면 그 데이터의 왼쪽으로 위치 바꿔가면서 자기 자리를 찾아가게 됨
동작 예시

첫 번째 데이터인 7은 그자체로 정렬이 되어 있다고 판단하고 두 번째 데이터인 5의 위치를 판단하는데, 7의 왼쪽/오른쪽 중 들어갈 수 있는 자리는 왼쪽이므로
5 7 9 0 .. 으로 정렬됨

0의 경우 왼쪽의 데이터에 대해서 차례로 왼쪽/오른쪽 중 들어갈 수 있는 자리를 탐색해 9의 왼쪽, 7의 왼쪽, 5의 왼쪽까지 위치하게 됨
시간 복잡도
이중 반복문으로 구현되므로 시간 복잡도는 이지만, 현재 리스트가 거의 정렬되어 있는 최선의 경우라면 의 시간 복잡도를 가질 수 있음
소스코드
a = [7, 5, 9, 0, 3, 1, 6, 2, 4, 8]
for i in range(1, len(a)): # 두 번째 원소부터
for j in range(i, 0, -1): # 왼쪽에 있는 데이터에 대해서
if a[j] < a[j-1]: # 자기보다 큰 원소가 있으면
a[j], a[j-1] = a[j-1], a[j] # 스왑(왼쪽으로 이동)
else:
break
퀵 정렬
기준 데이터(pivot) 설정 → 그 기준보다 큰 데이터와 작은 데이터 위치 바꾸기
일반적인 상황에서 가장 많이 사용되는 정렬로, 병합 정렬과 더불어 대부분의 프로그래밍 언어에서 표준 정렬 라이브러리의 근간이 되는 알고리즘임
가장 기본적인 퀵 정렬: 첫 번째 데이터 값을 pivot으로 설정
동작 예시
1) 현재 피벗: 5

왼쪽에서부터 5보다 큰 데이터를 선택하므로 7이 선택되고,
오른쪽에서부터 5보다 작은 데이터를 선택하므로 4가 선택되어
7과 4의 위치가 서로 변경 됨
2) 현재 피벗: 5

왼쪽에서부터 5보다 큰 데이터를 선택하므로 9가 선택되고,
오른쪽에서부터 5보다 작은 데이터를 선택하므로 2가 선택되어
9와 2의 위치가 서로 변경 됨
3) 현재 피벗: 5

왼쪽에서부터 5보다 큰 데이터를 선택하므로 6이 선택되고,
오른쪽에서부터 5보다 작은 데이터를 선택하므로 1이 선택되는데,
이처럼 위치가 엇갈리는 경우에는 피벗과 작은 데이터의 위치를 서로 변경하게 되므로
5와 1의 위치가 서로 변경됨
4) 분할 완료

피벗인 5의 왼쪽에 있는 데이터는 모두 5보다 작고, 오른쪽에 있는 데이터는 모두 5보다 커짐
→ 피벗을 기준으로 데이터 묶음을 나누는 작업을 분할이라고 함
5) 왼쪽 데이터 묶음(배열)에 대해 퀵 정렬 수행, 오른쪽 데이터 묶음(배열)에 대해 퀵 정렬 수행
⇒ 재귀적으로 수행되고, 수행될 때마다 정렬을 위한 범위가 점점 좁아짐
퀵 정렬이 빠른 이유
이상적인 경우 분할이 절반씩 일어난다면 (한 번 분할될 때마다 데이터의 범위를 절반에 가깝게 분할할 수 있다면)
전체 연산 횟수로 을 기대할 수 있음 (밑이 2인 로그)
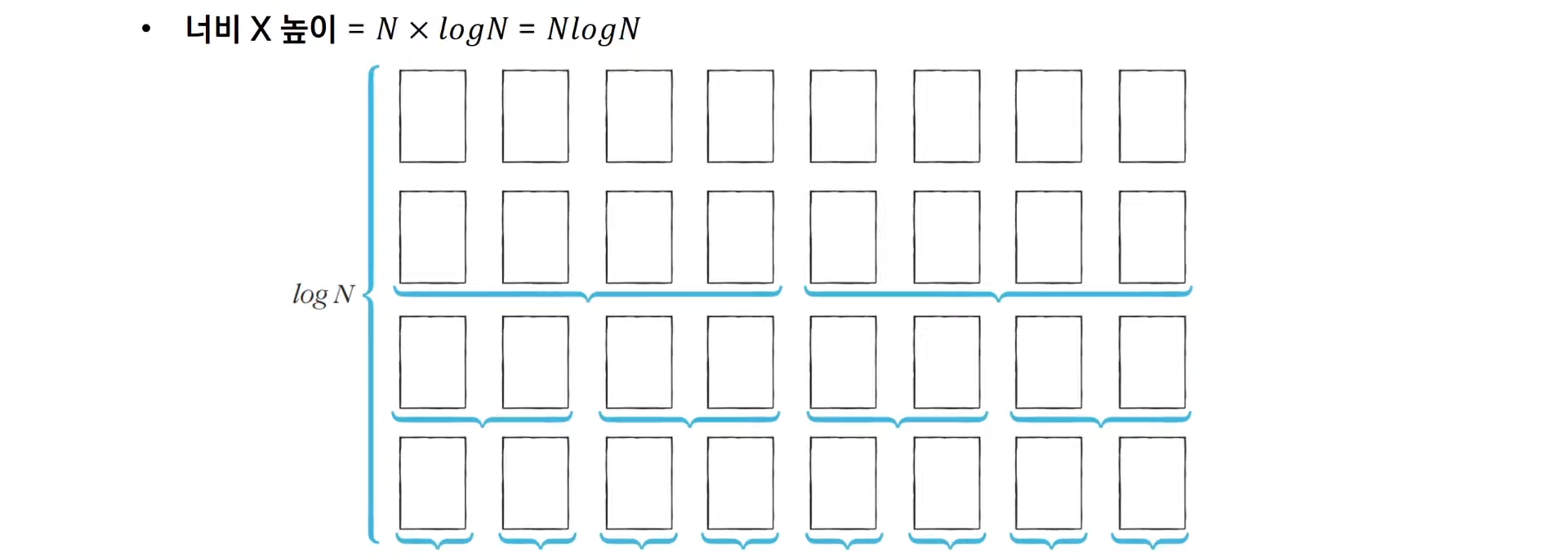
퀵 정렬의 시간 복잡도
-
평균:
-
최악의 경우: 이미 정렬된 리스트일 때 첫 번째 원소를 피벗으로 삼는다면 계속 오른쪽 데이터 묶음만 남게 되므로
-
단, 표준 라이브러리 사용하면 기본적으로 O(NlogN)을 보장해줌
일반적인 소스코드
a = [5, 7, 9, 0, 3, 1, 6, 2, 4, 8]
def quick_sort(array, start, end):
if start >= end: # 원소가 1개인 경우 종료
return
pivot = start # 첫 번째 원소로 피벗 설정
left = start + 1
right = end
while(left <= right):
# 왼쪽: 피벗보다 큰 데이터 찾을 때까지 반복
while(left <= end and array[left] <= array[pivot]):
left += 1
# 오른쪽: 피벗보다 작은 데이터 찾을 때까지 반복
while(right > start and array[right] >= array[pivot]):
right += 1
# 엇갈렸다면 작은 데이터 <-> 피벗
if(left > right):
array[right], array[pivot] = array[pivot], array[right]
# 엇갈리지 않았다면 작은 데이터 <-> 큰 데이터
else:
array[right], array[left] = array[left], array[right]
# 분할 이후 왼쪽 부분과 오른쪽 부분에서 각각 정렬 수행
quick_sort(array, start, right-1)
quick_sort(array, right+1, end)
quick_sort(a, 0, len(a)-1)
간결한 소스코드
: 파이썬의 리스트 슬라이싱 & 컴프리헨션 이용
a = [5, 7, 9, 0, 3, 1, 6, 2, 4, 8]
def quick_sort(array):
if len(array) <= 1:
return array
pivot = array[0]
tail = array[1:] # 피벗을 제외한 리스트
left_side = [x for x in tail if x <= pivot] # 분할된 왼쪽 부분
right_side = [x for x in tail if x > pivot] # 분할된 오른쪽 부분
# 분할 이후 왼쪽 부분과 오른쪽 부분에서 각각 정렬 수행하고, 전체 리스트 반환
return quick_sort(left_side) + [pivot] + quick_sort(right_side)
quick_sort(a)
계수 정렬
특정한 조건이 부합할 때 == 데이터의 크기 범위 제한되어 정수 형태로 표현할 수 있을 때만 사용 가능하지만, 조건만 부합한다면 매우 빠르게 동작함
⇒ 데이터 개, 데이터(양수) 중 최댓값 일 때 최악의 경우에도 보장
동작 예시
정렬할 데이터: 7 5 9 0 3 1 6 2 9 1 4 8 0 5 2
가장 작은 데이터(0)부터 가장 큰 데이터(9)까지의 범위가 모두 담길 수 있도록 리스트 생성

데이터에 0~9 까지 있으니까 길이 10의 리스트가 생성되고,
데이터 값과 동일한 인덱스의 count를 1씩 증가 → 각 인덱스의 count 값만큼 반복해서 출력
정렬 후 데이터: 0 0 1 1 2 2 3 4 5 5 6 7 8 9 9
⇒ 공간 복잡도가 높지만 조건만 만족한다면 퀵보다 훨씬 빠르게 동작 가능
시간 복잡도
-
시간, 공간 복잡도 모두
-
때에 따라 심각한 비효울성 초래 가능
ex) 데이터가 0, 999999 두 개만 있으면 → 0~999999 까지 리스트 생성해야 하므로
-
동일한 값을 가지는 데이터가 여러 개 등장할 때 효과적
ex) 성적의 경우, 100점을 맞은 학생이 여러 명일 수 있으므로 계수 정렬 효과적
소스코드
# 모든 원소의 값이 0보다 크거나 같을 때(인덱스로 사용할 거니까)
a = [7, 5, 9, 0, 3, 1, 6, 2, 9, 1, 4, 8, 0, 5, 2]
# 모든 범위를 포함하는 리스트 선언, 값은 0으로 초기화
count = [0] * (max(a) + 1)
for i in range(len(a)):
count[a[i]] += 1 # 각 데이터에 해당하는 인덱스의 값 증가
# 리스트에 기록된 정렬 정보 확인해 출력
for i in range(len(count)):
for j in range(count[i]): # 인덱스마다의 개수만큼
print(i, end=' ') # 인덱스 출력정렬 알고리즘 예제: 두 배열의 원소 교체
문제
동빈이는 두 개의 배열 A와 B를 가지고 있다. 두 배열은 N개의 원소로 구성되어 있으며, 배열의 원소는 모두 자연수이다
동빈이는 최대 K 번의 바꿔치기 연산을 수행할 수 있는데, 바꿔치기 연산이란 배열 A에 있는 원소 하나와 배열 B에 있는 원소 하나를 골라서 두 원소를 서로 바꾸는 것을 말한다
동빈이의 최종 목표는 배열 A의 모든 원소의 합이 최대가 되도록 하는 것이며, 여러분은 동빈이를 도와야한다
N, K, 그리고 배열 A와 B의 정보가 주어졌을 때, 최대 K 번의 바꿔치기 연산을 수행하여 만들 수 있는 배열 A의 모든 원소의 합의 최댓값을 출력하는 프로그램을 작성하라
예를 들어 N = 5, K = 3이고, 배열 A와 B가 다음과 같다고 해보자
배열 A = [1, 2, 5, 4, 3]
배열 B = [5, 5, 6, 6, 5]이 경우, 다음과 같이 세 번의 연산을 수행할 수 있다
-
연산 1) 배열 A의 원소 '1'과 배열 B의 원소 '6'을 바꾸기
-
연산 2) 배열 A의 원소 '2'와 배열 B의 원소 '6'을 바꾸기
-
연산 3) 배열 A의 원소 '3'과 배열 B의 원소 '5'를 바꾸기
세 번의 연산 이후 배열 A와 배열 B의 상태는 다음과 같이 구성될 것이다
배열 A = [6, 6, 5, 4, 5]
배열 B = [3, 5, 1, 2, 5]이때 배열 A의 모든 원소의 합은 26이 되며, 이보다 더 합을 크게 만들 수는 없다
문제 조건
시간제한 2초, 메모리 제한 128MB
입력
첫 번째 줄: N, K 가 공백으로 구분되어 입력 (1 <= N <= 100,000, 0 <= K <= N)
두 번째 줄: 배열 A의 원소들이 공백으로 구분되어 입력 (원소 a < 10,000,000인 자연수)
세 번째 줄: 배열 B의 원소들이 공백으로 구분되어 입력 (원소 b < 10,000,000인 자연수)
5 3
1 2 5 4 3
5 5 6 6 5
출력
최대 K번 바꿔치기 연산을 수행해서 가장 최대의 합을 갖는 A의 모든 원소 값의 합을 출력
입력 예시
26
문제 해결 아이디어
내가 시도한 방법
a와 b를 정렬한 뒤, a에서 앞쪽(작은) 데이터와 b에서의 뒤쪽(큰) 데이터를 교환하면 a에는 b의 큰 수들이 들어오므로 합이 최대가 될 것
n, k = map(int, input().split())
a = list(map(int, input().split()))
b = list(map(int, input().split()))
a.sort()
b.sort()
for i in range(k):
a[i], b[n-i-1] = b[n-i-1], a[i]
print(sum(a))-
방식은 맞았지만, 최대 k번인 건데 무조건 k번이라고 생각해서 단순 스왑만 해줬음
-
바꿔치기 횟수가 k번보다 작아도 되므로, 바꿀 차례인 a의 원소 >= b의 원소라면 안 바꾸고 반복문 탈출해야 함
-
인덱스 편하게 하려면 그냥 b를 내림차순
강의에서 소개된 핵심 아이디어
매번 배열 a에서 가장 작은 원소를 골라서 배열 b에서 가장 큰 원소와 교체
-
a를 오름차순, b를 내림차순 정렬
→ 두 배열 원소가 최대 10만 개까지 입력될 수 있으므로 최악의 경우 O(NlogN)을 보장하는 정렬 알고리즘 이용
-
첫 번째 인덱스부터 확인하면서 a의 원소가 b의 원소보다 작을 때만 교체 수행
코드
n, k = map(int, input().split())
a = list(map(int, input().split()))
b = list(map(int, input().split()))
a.sort()
b.sort(reverse=True)
for i in range(k):
if a[i] < b[i]:
a[i], b[i] = b[i], a[i]
else:
break
print(sum(a))Source
이코테 2021 강의 몰아보기
