Transformer 요약
RNN의 문제점
- 타임스텝이 길어짐에 따라서 초기정보가 제대로 전달되지 못한다.
- 타입스텝을 따라서 순차적 계산이 이루어져서 병렬처리를 하지 못한다.
- 인코더에서 디코더로 정보전달시에 병목으로인한 정보전달의 어려움이 있다.
트렌스포머는 이와같은 문제들을 해결한다.
Self-Attention
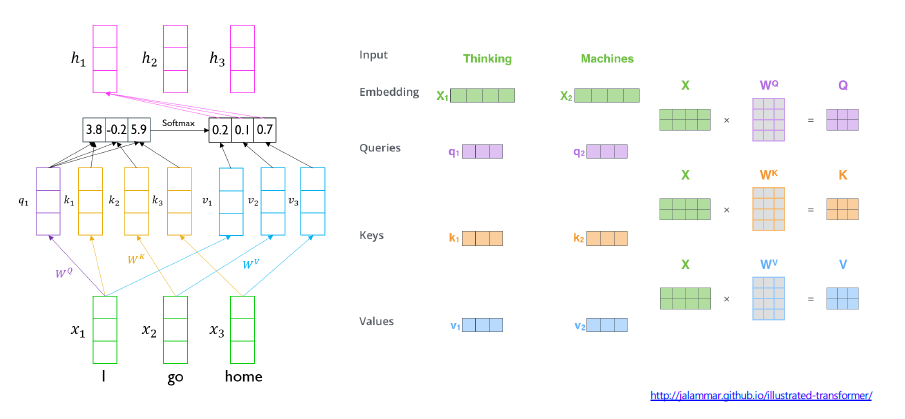
위의 이미지는 하나의 단어 'I'에 대해서 어떻게 self-attention이 이루어 지는지 보여준다.
- 해당 단어 'I'는 query벡터로 사용이되며, 'I', 'go', 'home'각각의 단어가 다시 key벡터, value 벡터로 사용된다.
- 각 단어에 대한 벡터들이 각 query, key, value 가중치 행렬과 곱함으로써 선형변환이 된다.
- 먼저 query 벡터와 key벡터간의 내적을 통해 유사도를 취한다.
- 그후 softmax를 통해 확률 분포를 구한다.
- 다시 이 확률분포와 value 벡터간의 가중평균을 통해서 해당 'I'에 대한 인코딩값을 구하게 된다.
이러한 계산을 하나의 단어에서 확장하여 모든 단어에 대해서 적용하게 되면 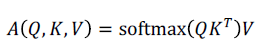
이러한 수식을 얻을수 있다.
여기서 차원이 커짐에따라 분산값이 커지는것을 막고자 스케일링을 추가하면 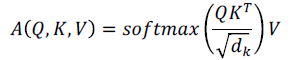
라는 최종 수식을 얻게 된다.
Multi-Head Attention
이러한 self-attention을 여러번 사용하는 기법이 바로 Multi-Head Attention이다.
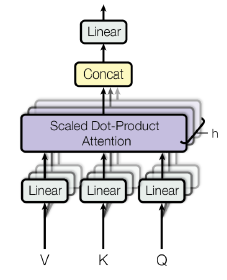
Attention을 통해 얻은 값들을 concat후에 선형변환 함으로써 Multi-Head Attention 값을 얻을수 있다.
인코더내의 이외 연산들
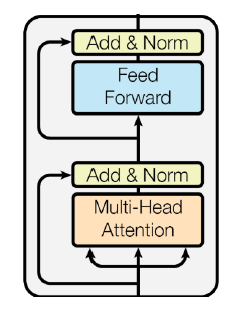
이후 Residual Connection, Layer Normalization등을 통한후, FC layer를 통과한후 다시 Residual Connection, Layer Normalization을 한다.
Positional Encoding
Self-Attention이 각 벡터들에 대한 순서정보를 가지지 못하기 때문에 이를 해결하고자 사용하는 방법이다.
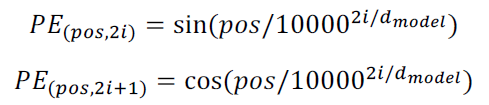
Sine, Cosine함수를 이용해서 각 벡터의 고유 위치정보를 갖게금 한다.
Stacking Attention Modules
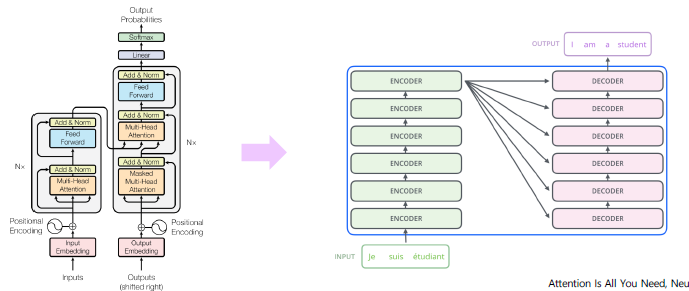
이와같이 Attention모듈들을 깊게 쌓는 방법을 사용할수 있다.
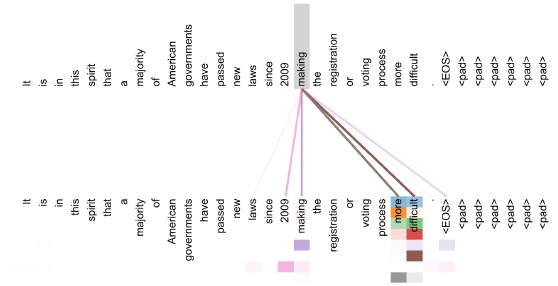
Visualization
이러한 attention사용의 이점중 하나가 바로 해당 모델의 작동을 시각화 할수 있다는데 있다.
Decoder
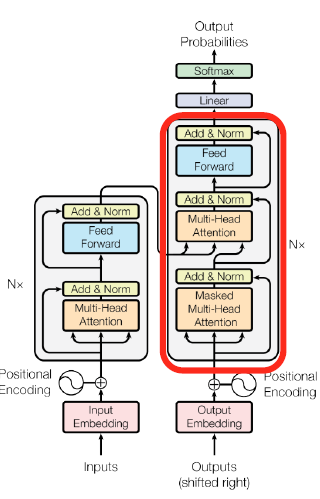
디코더의 작동은 인코더와 거의 유사하다.
차이점은
- Masked Multi-Head Attention을 사용한다.
- Multi-Head Attention에서 Key, Value 행렬을 인코더에서 받아서 사용한다.
- 그후 FC layer, softmax를 통해 classfication을 통해 단어를 생성한다.
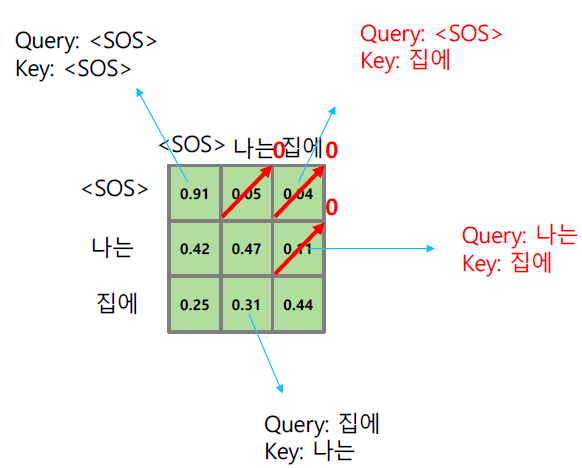
Masked Self-Attention
훈련시에 디코더에서 모델이 아직 생성되지 않은 단어에대한 참조를 수행하지 못하게 하기 위해서 사용한다.
이는 Query, Key의 내적 수행후 softmax시에 아직 생성되지 않은 값들에 대한 확률값을 0으로 만듬으로써 수행한다.
Transformer의 실험 결과
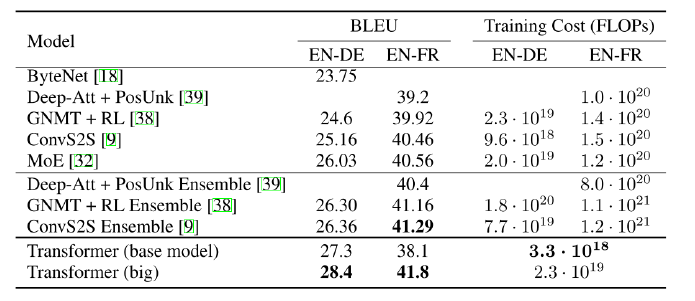
번역에 있어서 기존의 모델들보다 더 좋은 성능을 낸다.
