
프롬프트 엔지니어링(Prompt Engineering)
NLP 모델이 내가 원하는 작업을 하도록 최적의 프롬프트를 설계하는 방법론.
1. OpenAI 프롬프트 엔지니어링 가이드라인
1-1 명확한 명령 작성하기
- 쿼리를 구체적으로 작성
(ex. 누가 대통령인가요? → 2004년 대한민국의 대통령의 이름을 알려주세요.) - 페르소나 채택
(ex. 수학 문제를 풀다가 도움을 요청하면 답을 제공하지 않고, 해설과 함께 틀린 부분을 알려야한다.) - 구분자(Delimeter)를 사용해 입력의 특정 부분을 명확히 구분
(ex. '''A''' ← 따옴표 세개로 구성된 부분에 대해 영어로 번역) - 테스크를 완료하는데 필요한 단계 지정
(ex. step 1 ..., step 2, ...) - 예시 제공
(ex. few shot learning) - 원하는 출력 길이 지정 (단, 단어 길이가 아닌, 단락, 글머리 기호 기준으로)
(ex. 두 개의 단락으로 요약)
1-2 참조 텍스트 제공하기
- 참조 텍스트 기반 답변 지시.
(ex. '''기사''' 제공된 기사를 세 개의 따옴표로 구분하여 질문에 답합니다. ...) - 참조 텍스트의 인용으로 답변하도록 지시하기.
(ex. 당신의 임무는 제공된 문서만 사용하여 질문에 답하고 질문에 답하는 데 사용된 문서의 구절을 인용하는 것입니다.)
1-3 복잡한 작업을 더 간단한 하위 작업으로 분할하기
- 의도 분류 후 적합 명령 식별
(ex. 카테고리 분류) - 긴 대화가 필요한 대화 어플리케이션에서 이전 대화를 요약하거나 필터링한다.
- 긴 문서 요약 후 재귀적 작성
1-4 모델에게 "생각"할 시간을 주기
- 결론을 내리기 전에 모델이 자체 해결책을 제시하도록 지시한다.
(ex. 수학 문제 풀이가 맞다 틀리다를 판단할 때, 직접 문제를 풀어보고 판단하라고 하기) - 내부 독백 또는 일련의 쿼리를 사용해 모델의 추론 과정 숨기기.
(ex. 수학 문제 풀이에서 모든 솔루션을 알려주는게 아닌, 틀린 부분에 힌트를 주기. 즉, 출력을 사용자에게 제시하기전, 출력의 일부만 표시하도록 정제하기) - 이전 답변에서 놓친 부분이 있는지 모델에게 묻기.
(ex. 내용을 나열한 대화의 후속 쿼리에서 놓친 부분이 있는지 물어봐서 스스로 놓친 부분이 있는지 확인하게 한다.)
1-5 외부 도구 사용하기
- 임베딩 기반 검색을 사용한 효율적 지식 검색 구현.
(ex. RAG. 외부 정보 소스를 활용한 최신 정보 응답) - 코드로 정확한 계산 수행 혹은 외부 API 호출
(ex. 언어 모델이 산술을 정확하게 하기 어렵기 때문에 Python 코드로 작성한 후 코드 실행을 위한 외부 API 호출.) - 모델에게 외부 특정 기능(fuctions)에 대한 액세스 권한 부여
1-6 변경 사항을 체계적으로 테스트하기
- 최적 답변 참조 모델 출력 평가
(ex. 통계적 검정)
2. ChatGPT 및 거대언어모델의 추론 능력 향상을 위한 프롬프트 엔지니어링 방법론 및 연구 현황 분석
박상언, 강주영. (2023). ChatGPT 및 거대언어모델의 추론 능력 향상을 위한 프롬프트 엔지니어링 방법론 및 연구 현황 분석. 지능정보연구, 29(4), 287-308.
2-1 프롬프트 엔지니어링 기법 정리
| 프롬프팅 기법 | 내용 | 문제점 | 자동 여부 |
|---|---|---|---|
| Few-shot Learning | 다수 예제를 통해 간단한 추론 가능 | 복잡한 추론 불가 | No |
| Generated Knowledge Prompting(GKP) | 추론을 위해 필요한 지식을 생성하는 단계를 중간에 추가 | 복잡한 추론 불가 | Yes |
| Chain of Thought(CoT) | 추론 단계를 답변에 추가함으로써 비교적 복잡한 추론 가능 | 사람이 추론 단계를 추가해야 한다. | No |
| Self-Consistency | CoT에서 다양한 답변을 생성하고 일관성이 높은 답변을 선택함으로써 CoT보다 높은 성능을 보인다. | 사람이 추론 단계를 추가해야한다. | No |
| Zero-shot CoT | Zero-shot으로 추론 과정예제를 언어모델이 생성하게 함으로써 추론 단계 추가가 불필요 하다. | CoT 보다 낮은 성능 | Yes |
| Auto-CoT | Few-Shot + Zero-shot CoT. 문제 집합을 군집화하고 주어진 문제에 대해 각 군집에서 하나씩의 문제를 선별해서 예제 집합을 구성. 선별 과정에서 Zero-shot CoT 적용. | 답변과 추론 과정이 잘못된 예제 추가 가능성 | Yes |
| Active | Self-Consistency + Zero-shot CoT. Zero-shot Learning으로 추론과정 예제를 다양하게 생성하고, 답변의 불확실성이 높은 예제를 사람이 만든 예제로 교체. 답변 선택에도 자기 일관성을 적용한다. | 일부 문제에 대해 사람이 추론 단계를 추가해야한다. | Mix |
| Tree of Thought(ToT) | 트리 형태의 단계적 자기 일관성 + 상태 평가를 통한 휴리스틱 탐색. 문제 해결 과정을 여러 개의 사고로 분해하고 트리 형태로 사고를 생성하여 평가한 후 문제 해결까지의 다양한 경로를 탐색. 가장 높은 수준의 추론 성능을 달성. | 문제 유형에 따라 사람이 적절한 프레임워크를 설계해야한다. | No |
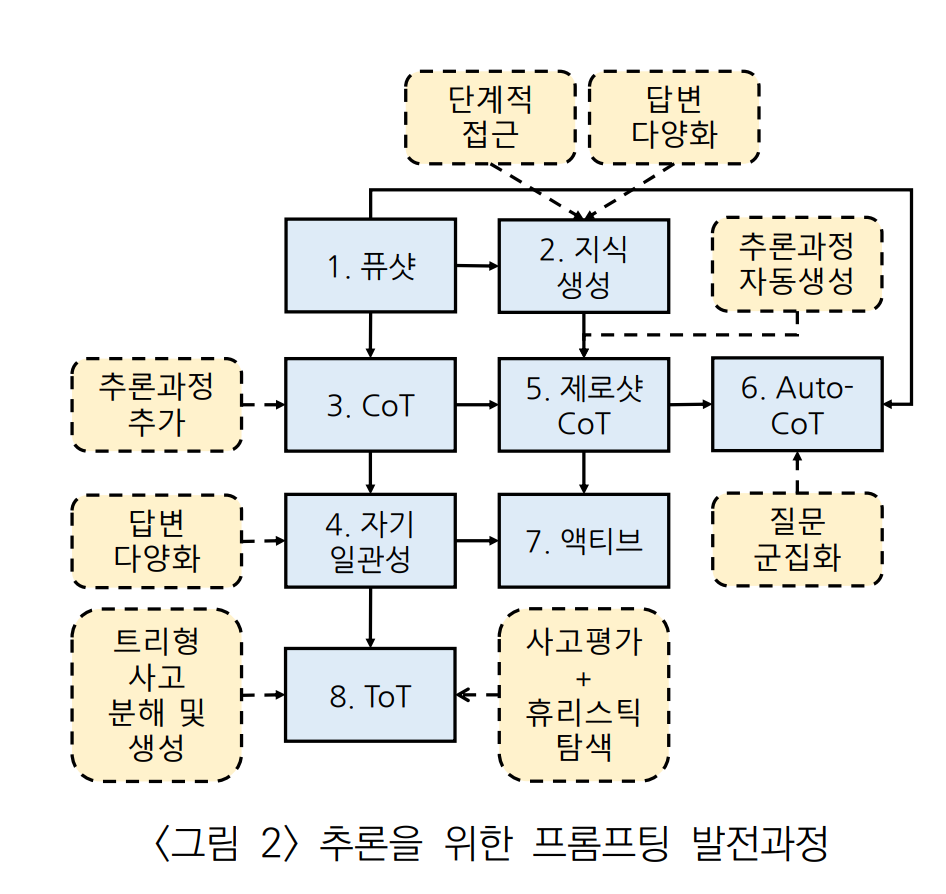
2-2. 프롬프트 엔지니어링의 개요
1) 문맥 내 학습(In-Context Learing; ICL)
언어 모델이 하나의 입력 시퀀스를 읽어 들이는 동안 그 안에 있는 서브 테스크들에 대해서도 학습이 일어나는 것을 발견하고, 이와 같이 입력 시퀀스의 내부 루프에서 발생하는 학습이다.
문맥 내 학습은 사용되는 예제의 수에 따라 퓨샷러닝, 원샷러닝, 제로샷 러닝으로 구분된다.
-
퓨삿 러닝(Few-shot Learning)
질문-대답 쌍의 여러 개의 예제를 통한 패턴을 학습시키고 마지막에 질문을 하는 형태이다. -
원샷 러닝(One-shot Learning)
한 개의 예제와 자연어로 기술된 작업 설명을 입력을 사용한다. -
제로샷 러닝(Zero-shot Learning)
원샷 러닝에서 예제를 빼고 작업에 대한 자연어 설명만을 입력으로 사용한다.
하나의 예제만을 사용하는 원샷 프롬프팅과 다수의 예제를 사용하는 퓨샷 프롬프팅은, 정확도가 각각 45% 정도와 65% 정도로 20%p 가량의 차이가 났다.
2) 프롬프트(Prompt)와 프롬프트 엔지니어링(Prompt Engineering)
프롬프트(Prompt)
퓨샷 러닝, 원샷 러닝, 제로 샷 러닝에서 답변을 이끌어 내기 위한 텍스트 입력 전체를 의미한다.
프롬프트 엔지니어링(Prompt Engineering)
어떤 식으로 프롬프트를 작성하는가에 따라 답변의 정확도가 바뀔 수 있으며, 보다 정확한 답변을 얻기 위해 프롬프트를 설계하는 것이다.
프롬프트의 구성요소
- 지시
- 질문
- 문맥
- 입력
- 예제
- 답변
3) Fine-tuning 과 In-Context Learning의 장단점
Fine-tuning 대비 In-Context Learning 의 장점
- 적은 데이터로도 좋은 성과를 낸다.
- 기존의 학습되지 않은 새로운 데이터셋을 학습시키지 않고 쉽게 활용할 수 있다.
- 하나의 LLM에 대해 작업에 맞는 프롬프트를 이용해 모든 작업 수행 가능하다.
Fine-tuning 대비 In-Context Learning 의 단점
- In-Context Learning의 학습은 가중치를 변경하지 않기 때문에 영구적 학습 유지가 안된다.
- 예제를 입력에 포함해야 하므로 입력 크기가 커진다.
- 특정 작업에서 성능이 떨어질 수 있다.
2-3 프롬프트 엔지니어링 기법들
1) 생성된 지식 프롬프팅 (Generated Knowledge Prompting; GKP)
LLM에서 일반적인 상식 추론의 성능을 높이기 위해 제안한 방법이다.
Few-shot Learning을 통해 문제 해결을 위한 지식 생성 → 생성된 지식과 문제를 다시 LLM에 입력
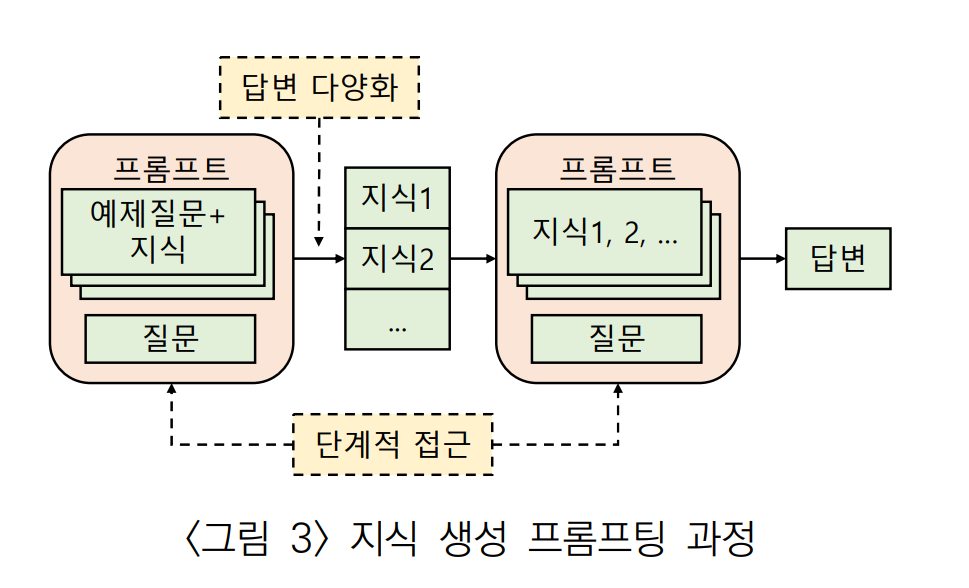
상식 추론 문제에서 지식을 사용한 경우(지식 생성) 81%, 사용하지 않은 경우(Few-shot) 72%로 9%p 높은 정확도를 보였다.
2) CoT(Chain of Thought) 프롬프팅
Few-shot Learning의 상식 추론 문제점을 개선하기 위한 목적으로 제안되었다.
답을 도출하는 추론 과정을 예제에 추가한다.
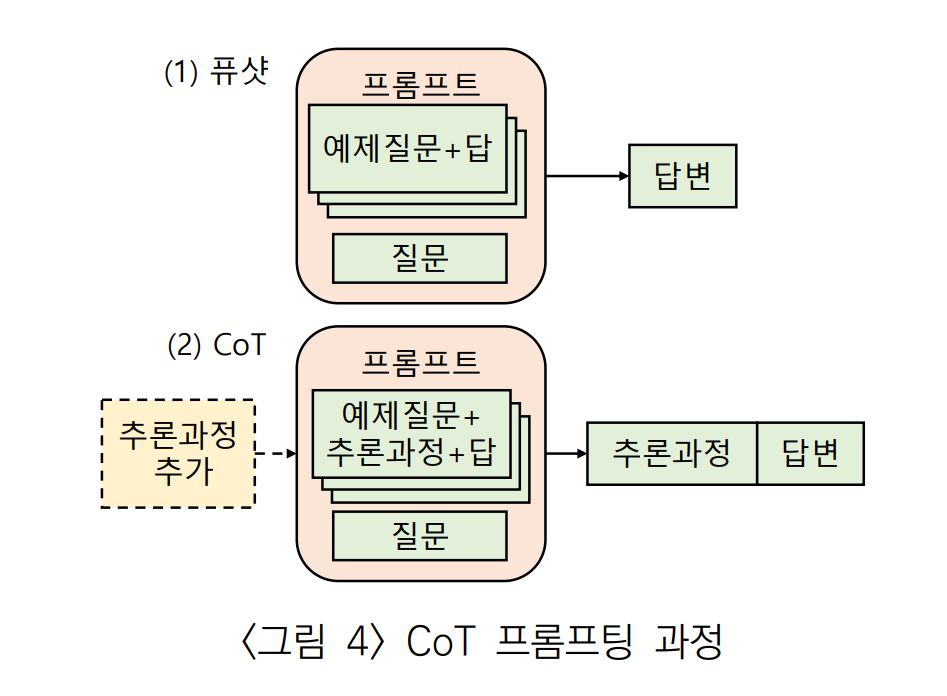

Few-shot Learning 이라면 그냥 '답은 11이다.' 이런 식의 답을 구성해야 하는데, '로저는 5개의 공으로 시작했고, ...' 같은 추론 과정 자체를 넣어준 것이다. 따라서 다음과 같이 답도 추론 과정을 포함해서 출력한다.

3) 자기 일관성 (Self-Consistency) 프롬프팅
Few-shot Learning이 그리디 방식을 이용해 가장 확률이 높은 하나의 답만을 사용하는 것을 보완하기 위해 제안되었다.
CoT 방식에서 다양한 추론 과정을 거치는 여러 개의 답을 샘플링하고, 그 중에서 다수결을 하거나 일관성이 높은 답을 선택한다. Temperature Sampling이나 Top-k Sampling 같은 방법을 사용한다.
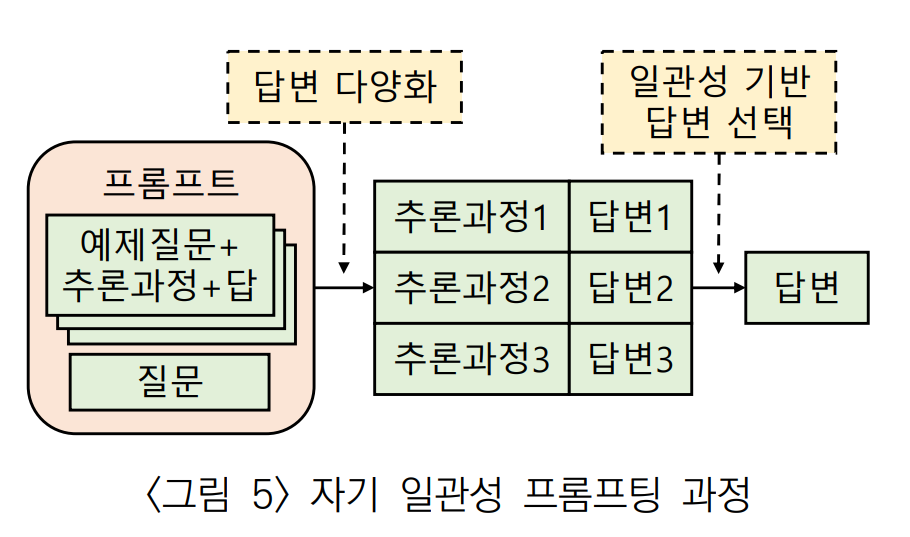
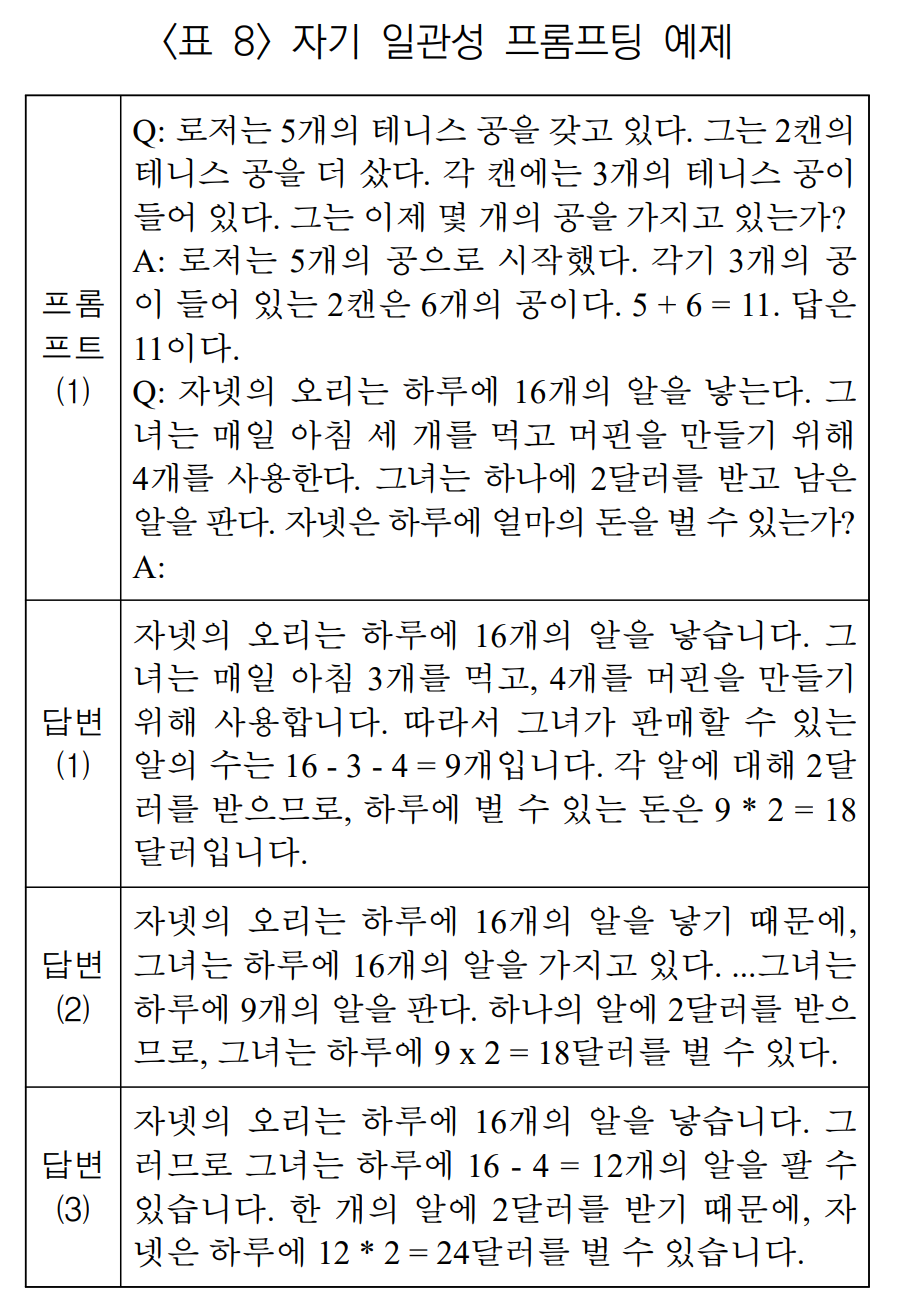
위의 답변들은 추론 실행시 Temperature Sampling 값을 조절하면서 3개의 답변을 뽑았다. 여기서 답변 1, 2는 18달러, 답변 3은 24달러인 결과이다. 따라서, 다수결 혹은 일관성 기준에 따라 18달러로 답을 선택한다.
4) 제로샷 CoT 프롬프팅 (Zero-shot CoT)
CoT 프롬프팅은 문제 해결 방법을 사용자가 설명해줘야 한다.
즉, 사용자가 풀 수 없는 유형의 문제는 답을 구할 수 없다.
Zero-shot CoT 프롬프팅은 문제의 추론 과정을 사용자가 입력하는게 아닌 LLM이 단계적으로 문제를 해결하는 방식이다.
- 추론 트리거 문장(Trigger Sentence)를 이용해 질문과 추론을 유도한다.
- 1단계에서 생성된 추론 과정과 응답을 유도하는 응답 트리거 문장을 추가하여 답을 구한다.
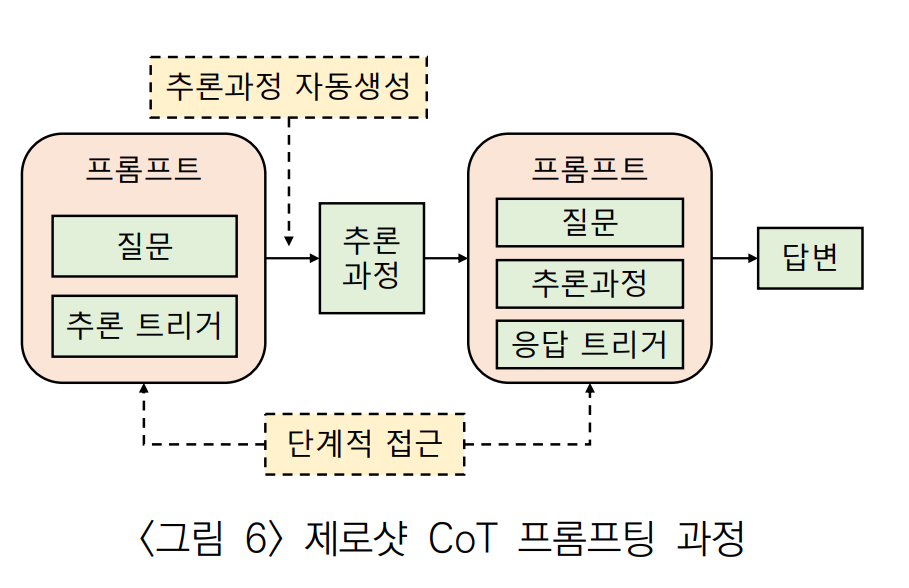
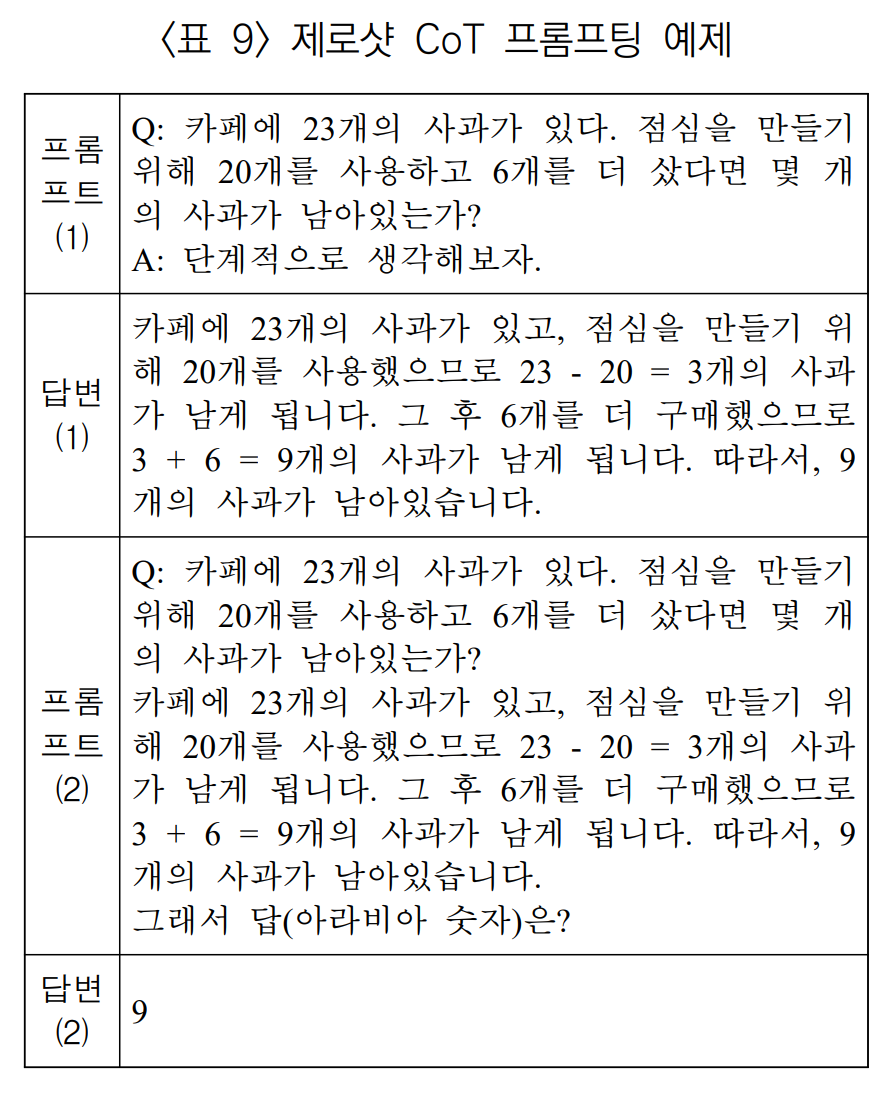
위의 예제에서 질문과 함께 '단계적으로 생각해보자.'는 추론 트리거를 삽입해 답변을 이끌어 냈다. 이 이끌어낸 답변은 추론 과정이다. 질문이랑 추론 과정을 합치고, 응답 트리거인 '그래서 답(아라비아 숫자)은?'을 같이 줘서 올바른 답을 받았다.
5) Auto-CoT(Automatic CoT) 프롬프팅
Zero-shot CoT가 추론 과정을 직접 입력해야하는 수작업을 없앴다. 하지만 Zero-shot CoT에서의 1단계 추론과정이 항상 정답이 아니다. 그래서 잘못된 예제를 제시함으로써 틀린 답을 유도할 수 있다. 따라서, 성능이 Few-shot CoT에 비해 떨어질 수 밖에 없다.
Auto-CoT 프롬프팅은 답안의 추론 과정을 자동으로 생성하는 방안을 제시했다.
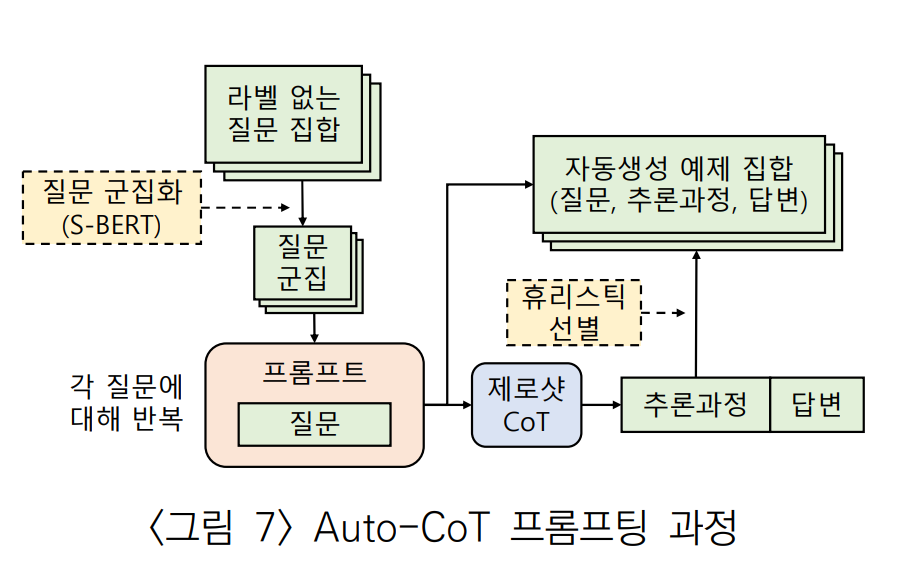
- 추론과정과 답이 없는 문제 집합에 군집화(Clustering)를 적용해 의미적으로 유사한 군집으로 분리한다.
- Zero-shot CoT를 이용해 군집에 있는 모든 문제들에 추론 과정을 생성한다.
- 휴리스틱을 적용해 각 군집을 대표하는 문제, 추론과정, 답변 을 하나씩 선별한다.
- 선별된 결과는 예제 집합에 추가되고, 주어진 질문에 대해 제로플러스퓨샷 CoT 프롬프트의 형태로 사용된다.
Few-shot CoT에 근접하거나 더 나은 성능을 보였다.
*제로플러스퓨샷 CoT: 제로플러스퓨샷 CoT는 Few-shot CoT에서 사용하는 각각의 예제에 대해 추론과정 앞에 추론 트리거 문장을 추가하여 학습한 방식이다.
“질문 + 추론과정 + 답” → “질문 + 추론 트리거 + 추론과정 + 답”
*Few-shot CoT: “질문 + 추론과정 + 답”
6) 액티브(Active) 프롬프팅
Zero-shot CoT에 의해 생성되는 추론 과정이 사람이 만든 추론과정보다 정확하지 않을 가능성은 항상 있다. 이는 사람이 추론과정을 생성하는 것이 높은 비용을 요구하기 때문이다. 액티브 프롬프팅은 Auto-CoT와 사람이 예제를 작성하는 Few-shot 프롬프팅의 절충안과 같은 방법이다.
액티브 프롬프팅은 학습을 위한 문제 집합과 평가를 위한 문제 집합이 나눠져 있는 환경에서 학습용 문제 집합을 이용해 평가용 문제 집합에서 사용할 예제들을 개발한다.

-
학습용 문제 집합에 있는 문제들에 대해 Few-shot CoT 프롬프트를 적용하거나, 예제가 없다면 Zero-shot CoT를 이용해 각 문제 별로 k개의 다양한 추론 과정 예제를 생성한다.
-
생성된 예제들에 대해 다른 예제들과의 불일치 정도를 기반으로 불확실성(Uncertainty)을 수치로 측정하고, 불확실성이 높은 상위 n개 예제들을 추출한다.
-
추출된 예제들에 대해 사람이 직접 정확한 예제를 생성해서 교체한다. 이것이 평가용 문제 집합에 대해 사용할 예제 집합이다.
-
완성된 예제 집합을 사용해 평가용 문제 집합에 대한 추론을 한다.
즉, Zero-shot CoT를 적용했을 때 다른 예제들 대비 불확실성이 높은 예제만 사람이 직접 교체해준다. 따라서, 안좋은 예제만 수정해줘서 적은 노력으로 높은 성능을 기대할 수 있을 것이다.
(부분 자동화)
7) ToT(Tree of Thought) 프롬프팅
복잡한 추론 문제를 해결하기 위해 제안되었다.
사람의 의사 결정 방식은 다음의 두가지로 나뉜다.
-
빠르고 자동적이고 무의식적인 방식
-
느리고, 심사숙고하고, 의식적인 방식.
현재 선택에 대한 다양한 대안 탐색, 현재의 상황을 주의 깊게 평가하고 전체적인 관점에서 더 나은 의사결정을 하기 위해 미리 다음 상태를 들여다보거나 다시 이전으로 돌아가 생각하는 특징이 있다.
여기서 두번째 방식을 반영한 프롬프팅 기법이다.
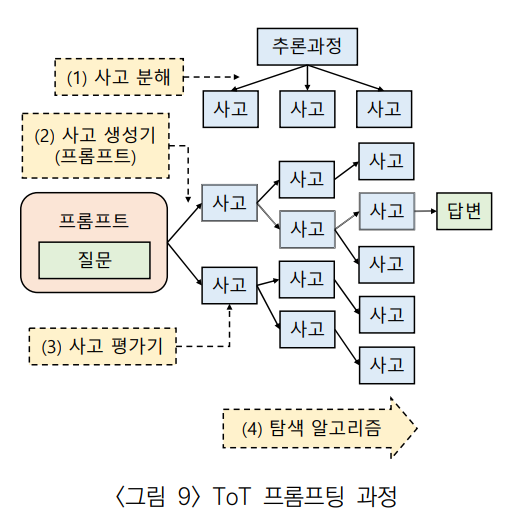
입력으로부터 다양한 사고를 생성하고, 트리 형태로 다음 단계 사고들을 생성하면서 그 중 가장 적합한 사고를 따라가 출력을 만들어낸다.
ToT 프롬프팅의 구현을 위한 4개 요소
-
사고 분해(Thought Decomposition)
주어진 문제를 유형에 따라 적절하게 작은 사고의 단위로 분해한다. -
사고 생성기(Thought Generator)
현재 트리 상태에서 다음 사고 단계를 생성한다. 사고의 생성에는 샘플(Sample)과 제안(Propose) 방식이 있다.-
샘플(Sample)
현재까지의 트리 상태를 입력으로 한 CoT 프롬프트를 독립적으로 k번 반복하여 다양한 사고를 생성한다. -
제안(Propose)
제안 프롬프트를 사용해 k개의 사고를 한 번에 생성한다. 샘플 방식은 다양성을 높일 수 있고, 제안은 사고가 단순할 때나 중복을 피하기 위해 사용할 수 있다.
-
-
상태 평가기(State Evaluator)
휴리스틱을 이용해 현재 상태를 평가해 트리에서 최적의 경로를 찾는다.- 각 상태를 독립적 평가하는 전략
- 전체 상태에서 상태들 간 비교를 통해 평가하는 전략
-
탐색 알고리즘
DFS, BFS
논문에서는 24 게임을 예시로 제시했다. 24 게임은 주어진 4개의 숫자로 사칙 연산을 해서 24를 만드는 게임이다.
예를 들어, "4, 9, 10, 13" 이 입력이면
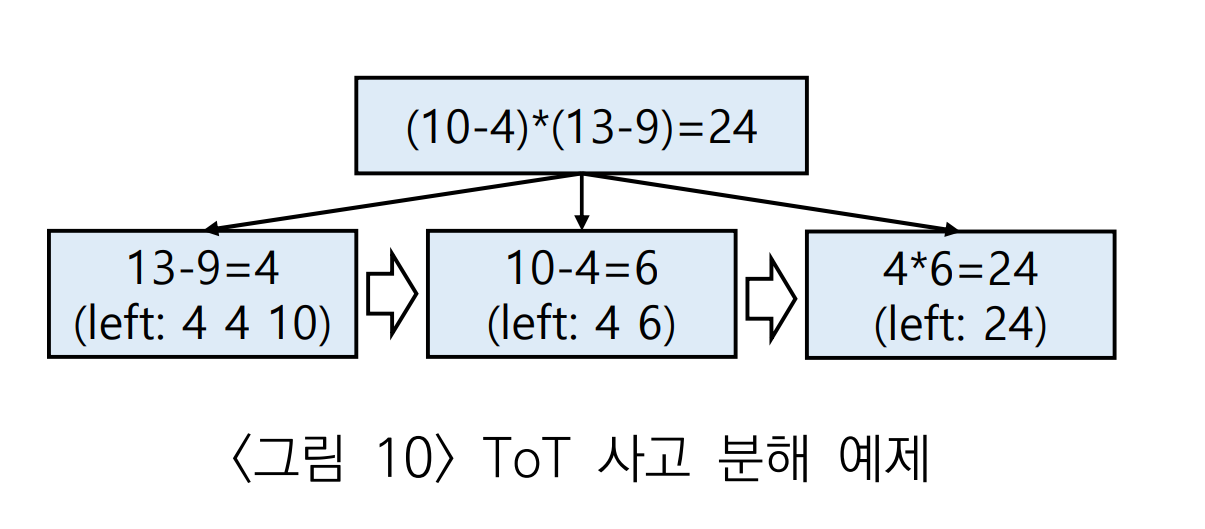
위와 같이 3단계로 사고 분해된다.
- 13과 9를 만들어 4를 만든다. 이 과정으로 4, 4, 10인 3개의 수가 남는다.
- 10과 4를 가지고 6을 만든다. 이 과정으로 4, 6인 2개의 수가 남는다.
- 4, 6으로 24를 만든다.
다음은 사고 생성의 예제이다.
숫자가 4개 있는 초기 단계에서 프롬프트를 이용해 다음과 같이 후보들을 생성한다.
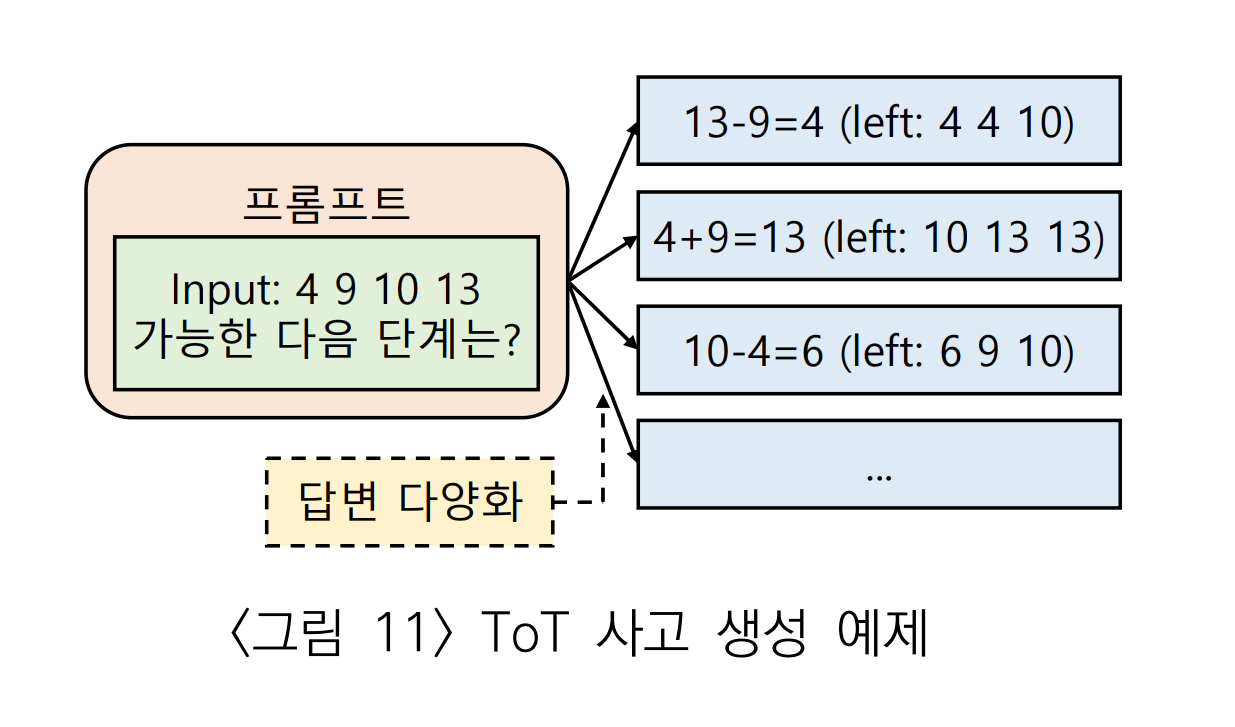
생성된 후보들에 대해 3단계인 사고 평가를 실시한다.
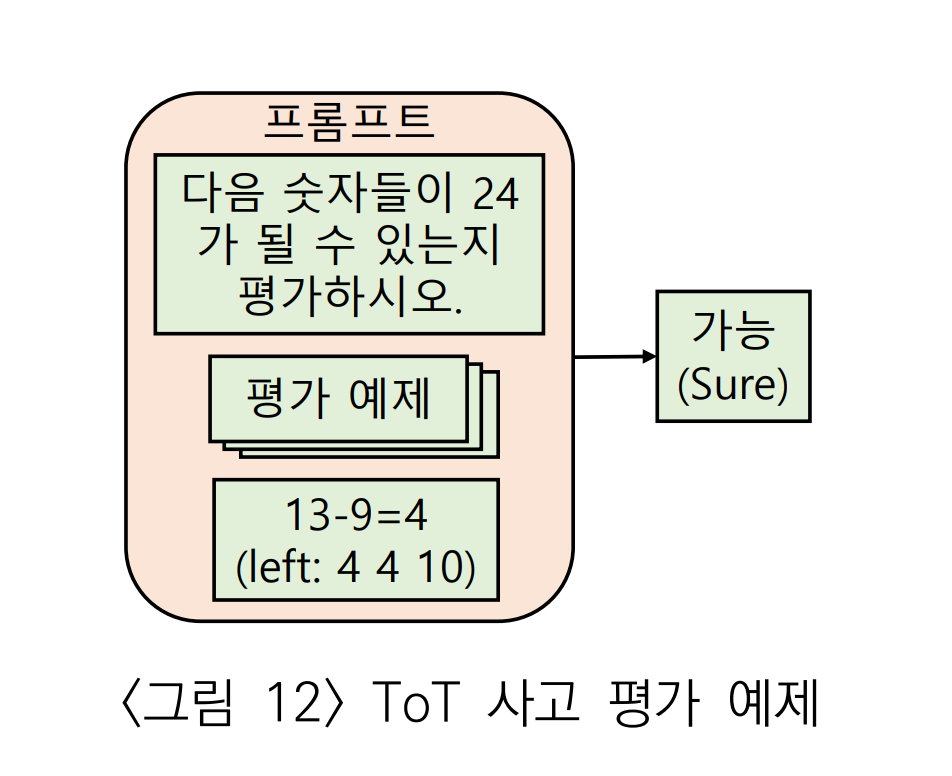
이는 Few-shot 프롬프트를 사용해 판별했다. 평가 결과를 이용해 트리에서 해를 찾기 위한 휴리스틱 기반 탐색이 이루어진다.
ToT를 공부하면서 햇갈렸던 부분은 사고 분해, 사고 생성, 상태 평가, 탐색이 독립적으로 이루어진다는 착각 때문이었다. 사고 분해를 하고, 사고 생성을 한다는게 무언가 연결이 잘 되지 않았었다. 하지만, 정리하자면 모두 병렬적으로 이루어지는 과정이다.
ToT 과정은 전반적으로 탐색 과정이다. 이 과정에서 문제를 해결하기 위해 사고를 분해하고, 분해된 각 사고에 대해 사고 생성을 하여 가능한 해결 방법을 제시한다. 그런 다음 각 사고를 평가하여 목표에 얼마나 가까운지 확인하고, 평가 결과를 바탕으로 다음 탐색을 진행한다. 이 과정을 반복적으로 수행하여 최적의 해결책을 찾아간다.
논문에 따르면 GPT-4를 사용해 실험했을때 CoT 프롬프팅과 자기 일관성 CoT 프롬프팅이 각각 4%와 9%의 성공률을 보인 반면 ToT 프롬프팅은 무려 74% 성공률을 보였다.
따라서, 프롬프팅 구조 혹은 단계의 설계에 따라 LLM이 매우 복잡한 문제도 풀 수 있음을 시사한다.
