오늘 한 거 240806
pytorch 문제를 풀다가 이해가 안 되는 지문이 있어서 아는 분께 도움을 요청하여 문제를 해결하였다.
해당 지문은 아래와 같다
torch.std()를 통해 '포본'표준편차를 계산할 수 있다.
나는 표본표준편차가 아닌 표준편차를 계산한다고 생각했는데 지문이 저래서 당황스러웠다.
내 생각대로면 표준편차가 메서드 이름이 std면 표본표준편차는 sstd(smaple std)이런식의 메서드가 존재하거나 표본 혹은 모집단을 구분하는 매개변수가 정의 되어 있어야 하겠지만 보이지 않았다.
torch.std(input, dim=None, \*, correction=1, keepdim=False, out=None)→ Tensor
# https://pytorch.org/docs/stable/generated/torch.std.html#torch.std혹시 정의를 이해하지 못하는 건가 해서 같이 공부하는 분께 물어보니 아래와 같은 배경을 설명해주셨다
모집단은 크게는 집단 자체를 의미하고 거기서 뽑아낸 것이 표본 그리고 이를 통해 표본표준편차를 구하면 모집단의 표본표준편차를 추정해볼 수 있다. 집단의 편차를 계산할 때 효율성을 생각해서 모집단에서 추출한 표본표준편차만을 계산하는 것이 일반적이다.
위를 바탕으로 그러면 일반적인 경우에 표준편차를 표본표준편차라고도 부를 수 있나?를 생각해봤지만 단정은 못했다. 일단 비약이 너무 심한 것도 있고 반대로 모집단이 집단 자체를 의미하는 걸 생각해보면 집단 자체의 표준편차는 모집단의 표준편차이니 크게 보면 모표준편차를 표준편차라고 볼 수도 있나?를 생각할 수도 있을 거 같아서이다.
여기까지 생각을 한 뒤에 pytorch 문서에 있는 std 계산식을 살펴보았다.
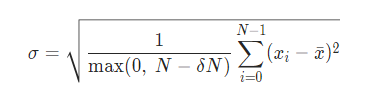
위는 pytorch에 명시된 std의 계산식이다. 모표준편차와 표본표준편차는 계산 식이 다르니 둘 중 위의 식과 같은 걸 찾아보면 pytorch에서 말하는 표준편차를 알아낼 수 있겠다 싶었다


그리고 통계를 손 놓은지 오래된 나는 식을 정확하게 볼 줄 몰랐다. 위는 표본표준편차(좌)와 모표준편차(우)의 공식인데 pytorch의 std 계산식과 비교해보려고 했으나 아는 게 없어 눈으로만 비교를 해봤고 표본표준편차의 꼴과 유사해보였다.
처음 알려주셨던 분이 본인도 찾아보다가 일단 코드로 돌려보았다고 하셨다.
import torch
a = torch.tensor([x * 10 for x in range(1, 7)], dtype=torch.float32)
s = sum((a - torch.mean(a)) ** 2)
print(f'torch 표준편차: {torch.std(a)}')
print(f'모표준편차: ', torch.sqrt(s / 6))
print(f'표본표준편차: ', torch.sqrt(s / 5))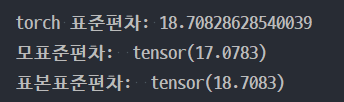
위 결과로 볼 때 표본표준편차로 보는 것이 타당할 거 같다고 이야기 해주셨다.
