오늘 한 거 240816
멀티프로세싱
python에서 1.7GB자리 단일 csv 파일을 pd.read_csv()로 불러올 일이 있었는데 해당 부분을 최적화 해보기 위해서 예전에 했던 멀티 프로세싱을 써보았다.
우선 예전에 코드를 한 번 보았다
corr_df = pandas.DataFrame()
if __name__ == '__main__': # for windows os
freeze_support() # for windows os
with Pool(processes=15) as pool:
pool_size = 15
chunk_size = 2000 * pool_size
count = 0
for file_chunk in pd.read_csv('../csv/data_compact.csv', low_memory=False, chunksize=chunk_size):
line = count * chunk_size
print(f"Processing {chunk_size} lines after line {line}")
# Split chunk evenly. It's better to use this method if every chunk takes similar time.
pool.map(processing_chunk, pd.np.array_split(file_chunk, pool_size))
count += 1
pool.close()
pool.join()
- windows 10 멀티프로세싱을 할 때 권한을 얻는 과정이 필요하다고 한다. 해서 2 ~ 3줄에 해당 처리를 해주었다.
- pool은 처음 호출시 사용 가능한 쓰레드 수를 지정한다.
- 이후 map method를 호출하여 인자 값으로 병렬 실행 시킬 함수와 해당 함수 호출에 필요한 인자를 넘겨준다.
- 이 과정에서 단순하게 read_csv method를 넘겨주면 파일 전채를 읽어오는 프로세스를 15개 생성하는 꼴이라 파일을 부분부분 쪼개서 실행시켜야한다.
https://subscription.packtpub.com/book/programming/9781783989263/1/ch01lvl1sec08/three-constraints-on-computing-performance-cpu-ram-and-disk-io
아래 설명은 위 사이트를 참조했다.
정확한 내용은 아니고 제가 생각한 내용입니다.
다시 설명하면
- read_csv() 실행시 storage에서 data_compact.csv를 순차적으로 읽어온다.
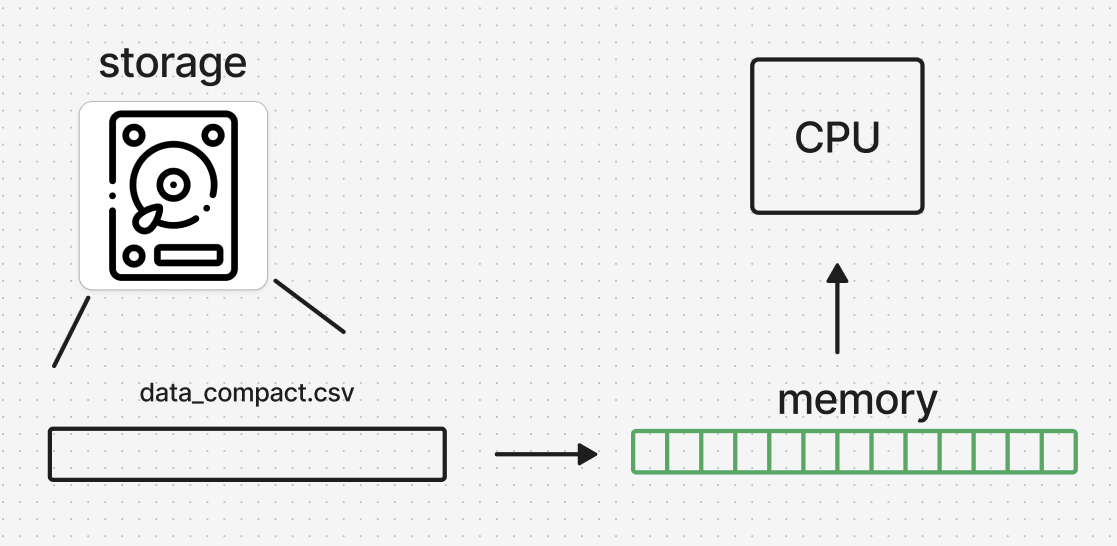
조금 자세히 보면
- 실행된 프로그램은 read_csv() 실행 이후 storage에 저장된 데이터를 메모리에 올려 cpu가 사용가능한 상태로 만든다.
- 이 과정에서 주체가 되는 프로그램은 프로세서로서 하나의 물리적인 쓰레드에 할당 되고 프로세서는 하나의 작업을 할 수 있게 된다.
아이디어와 상황고려?
- 프로세서를 늘리면 된다.
- 사용하는 cpu가 8코어 16쓰레드이니 한 12개 정도 할당하면 되겠다 싶었다

살아계셨군요 ^____^ b