[수업 목표]
- SQL Window 함수의 기본 구조 및 개념 이해하기
- 각 Window 함수 별 용도와 사용법 익히기
- 실습을 통해 Window 함수를 활용한 SQL 능력 향상하기
>Window 함수를 알아보아요
- Window 함수란 무엇인가요?
Window 함수는 한 번에 여러 행을 묶어서 처리 할수 있는 함수로,GROUP BY구문과 매우 비슷하지만, 원형의 데이터를 변형시키지 않고도, 다양한 함수를 원형의 데이터셋 행에 동시에 사용할 수 있습니다.

한마디로 원형의 데이터를 유지하는 상태에서 새로운 데이터를 만든다라고 생각하면 됨.
한마디로 group by 는 유니크함수를 써서 각각의 countif등 함수를 사용해 값을 낸다고 생각하면되고
window 함수는 유니크함수를 쓰는게 아니라 전체 행을 대상으로 countif를 사용한다고 생각하면됨.
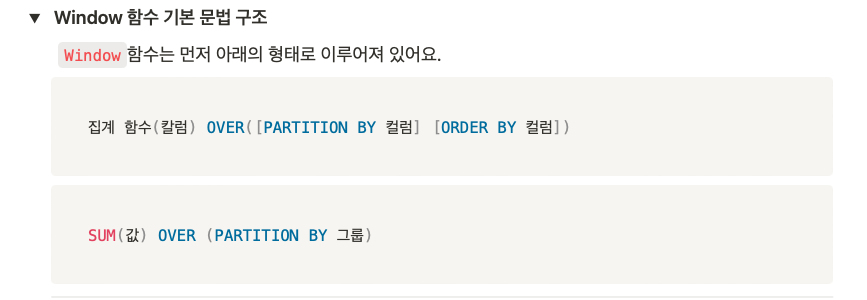
- 사용하는 문법: 집계 함수는 주로
GROUP BY절과 함께 사용되며, 데이터의 그룹별 요약을 제공하지만, window 함수는OVER절과 함께 사용되어 각 행에 대해 추가적인 계산 정보를 제공합니다.- 사용하는 경우: 집계 함수는 전체 그룹 또는 서브 그룹의 요약된 값을 필요로 할 때 사용됩니다. 반면 윈도우 함수는 각 행을 유지하는 범위 내에서 계산된 값을 제공하여 순위, 이동 평균, 누적 합계 등을 계산할 때 유용합니다.
-
Window 함수 종류
Window 함수가 가장 많이 사용되는 몇 가지 예시는 다음과 같습니다:
✅ 순위 매기기
[RANK, DENSE_RANK, ROW_NUMBER, LAG, LEAD]데이터를 특정 기준에 따라 순위를 매기는 데 유용합니다. 예를 들어, 판매 부서에서 매출액이 높은 상위 3명의 직원을 찾을 때 순위 함수를 사용할 수 있습니다.
✅ 이동 계산
[AVG]시계열 데이터에서 이동 평균을 계산하여 데이터의 추세를 파악하는 데 사용됩니다. 이동 평균은 데이터의 불규칙한 요소를 보다 부드럽게 표현하는 데 도움이 됩니다.
과일장수라서 과일을 파는데 월요일부터 일요일까지 판매하는데 어떤날은 300만원 어떤날은 400만원 어떤날은 1000만원 어떤날은 50만원 그래서 버는양만큼 소비를 하려고 하는데 이때 평균적으로 계산하려고할때 커지고 작아지고 이런거를 부드럽게 만들어주기 위해서
예를 들어
월요일 1000만원 / 이동평균 1000만원
화요일 200만원 / 이동평균 600만원
수요일은 500만원 / 이동평균 535만원 정도
이런식으로 평균을 흐름에 맞춰서 왔다갔다하지 않고 평균적으로 얼마를 벌었는지 부드럽게 만들어주는
주식시장에서 많이 사용
countif(a$2:a2,a2) 이런거라고 보면됨.✅ 누적 합계 또는 누적 평균
[SUM, AVG]일정 기간 동안의 누적 합계나 평균을 계산하는 데 사용됩니다. 예를 들어, 매일 증가하는 재고 수량을 누적 합산하여 전체 재고의 추이를 파악할 수 있습니다.
✅ 그룹별 집계
[SUM, MAX, MIN]특정 그룹에 대한 집계를 계산할 때 window 함수가 유용합니다. 예를 들어, 부서별로 최고 월급을 찾는 등의 작업에 활용됩니다.
✅ 백분위수 계산
[PERCENT_RANK, NTILE]데이터의 분포를 이해하고 이상치를 탐지하기 위해 백분위수를 계산할 때 window 함수가 사용됩니다. 특정 백분위수보다 큰 값이나 작은 값들을 확인하여 데이터의 특성을 분석할 수 있습니다.
-
ROW_NUMBER()
- 개념: 각 행에 고유 번호를 부여합니다.
- 실습:
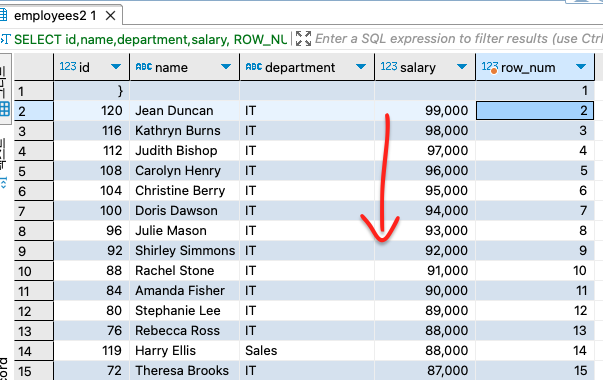
employees테이블에서 급여 순으로 각 행에 번호 매기기 - 예제:

employees 테이블에서 로우넘버를 쫘르륵 나열한건데 order by를 사용해서 salary의 높은순대로 1,2,3,4,5.. 이런식으로 로우의 번호를 매긴다는 것
결과>
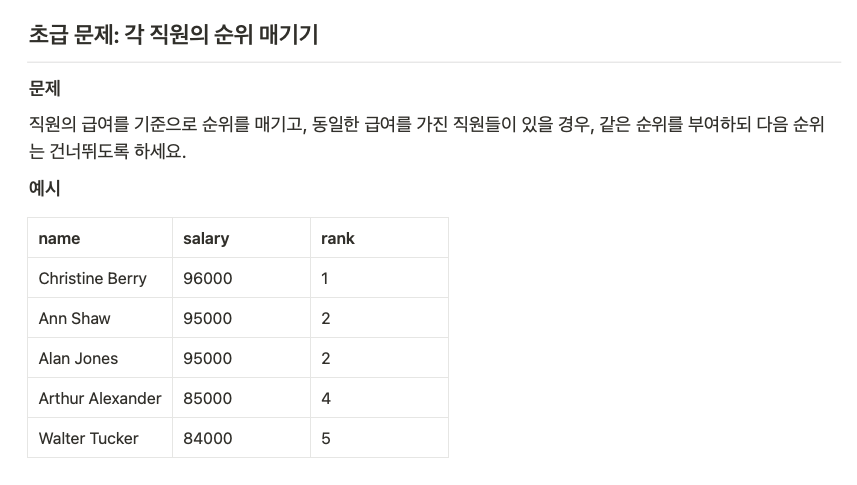
- RANK() & DENSE_RANK()
- 개념: 순위를 부여하는 함수로, 동순위 발생 시 RANK는 순위 건너뛰고, DENSE_RANK는 건너뛰지 않습니다
- 실습:
employees테이블에서 급여 순으로 순위 매기기 - 예제:
굉장히 row_number 와 동일한 개념이고 row_number는 동일한 순위 발생시에도
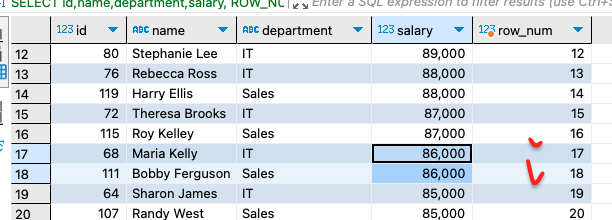
이런식으로 로우넘버가 같게 나오지않음
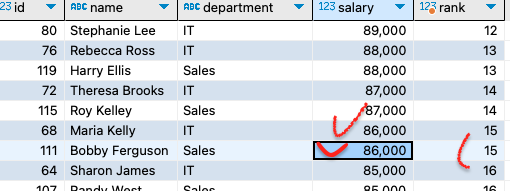
대신 rank() 와 dense_rank() 는 1위가 있고 2위 2명일때 3위를 어떻게 표시할것이냐 혹은 안할것이냐를 하는데 dense 라는 의미가 밀집하다 라는 의미가 담겨져있다.
그래서 rank() 는 1위가 있고 2위가 2명일 경우에 4위로 바로 넘어감!
dense_rank() 는 1위가 있고 2위가 2명일 경우에 3위로 넘어가진다.
- rank
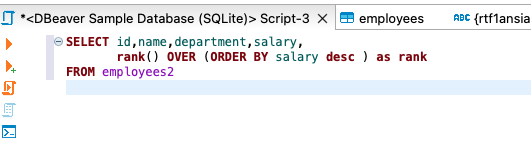
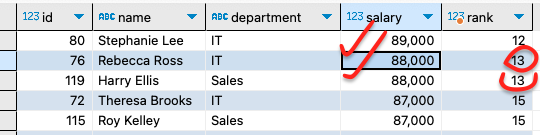
- dense_rank()

-
NTILE()
- 개념: 데이터를 N개의 구간으로 나누기
- 실습:employees테이블에서 급여를 4개 구간으로 나누기
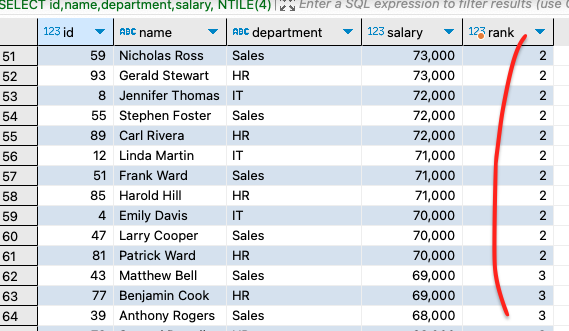
- 예제: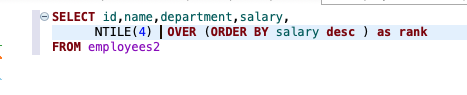분기를 4분기로 나누는것처럼 나눠서 숫자가 표기하게 만들어준다.
-
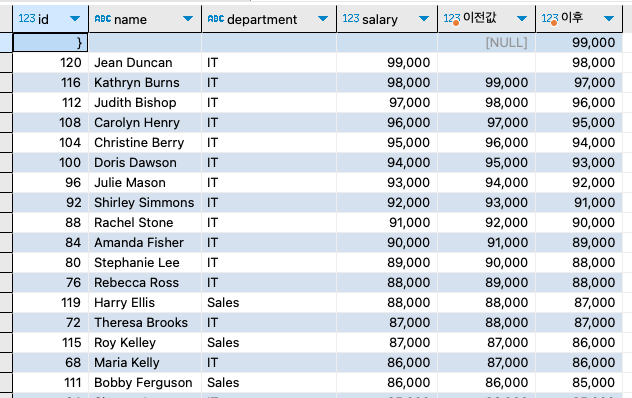
LAG() & LEAD()
- 개념: 현재 행을 기준으로 이전 또는 다음 행의 값 참조
- 실습:employees테이블에서 현재 행을 기준으로 이전 및 다음 행의 급여 값 참조하기
- 예제:
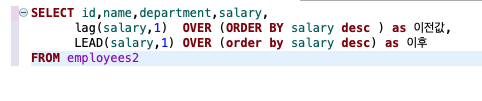
LAG > 이전값
LEAD > 이후값
-
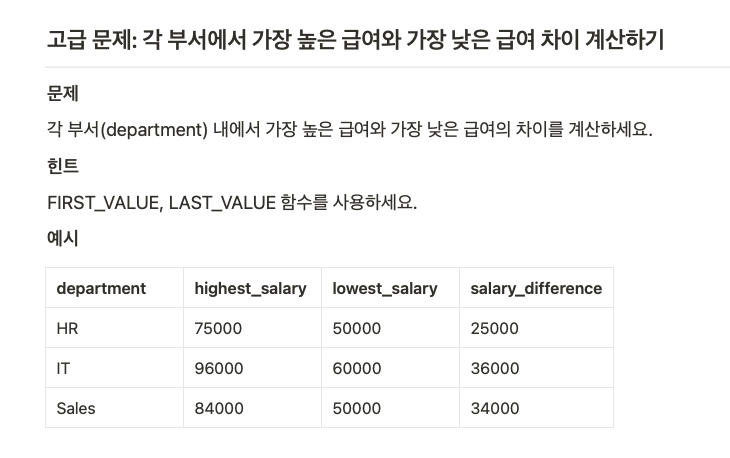
FIRST_VALUE() & LAST_VALUE()
- 개념: 윈도우 내 첫 번째 및 마지막 값 반환
- 실습:employees테이블에서 윈도우 내 첫 번째 및 마지막 급여 값 참조하기
- 예제:

first_value 는 맨첫번째 값을 나오게하고
last_value는 맨 마지막값을 나오게 한다.
RANGE BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING
이것은 무엇인지 알아보도록 하자.
RANGE BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING 부분은 SQL에서 윈도우 함수의 프레임을 지정하는 데 사용됩니다. 이 구문은 현재 행을 기준으로 윈도우 프레임의 시작과 끝을 설정합니다. 여기에서 각 키워드의 의미를 살펴보겠습니다:
RANGE: 이 키워드는 윈도우 프레임을 값 범위로 지정합니다. 다른 옵션으로는 ROWS가 있으며, 이는 실제 행의 개수를 기준으로 윈도우 프레임을 지정합니다.
BETWEEN: 프레임의 시작과 끝을 지정합니다.
UNBOUNDED PRECEDING: 윈도우 프레임의 시작을 첫 번째 행으로 지정합니다. "제한 없이 앞의 모든 행을 포함"하는 것을 의미합니다.
UNBOUNDED FOLLOWING: 윈도우 프레임의 끝을 마지막 행으로 지정합니다. "제한 없이 뒤의 모든 행을 포함"하는 것을 의미합니다.
따라서 RANGE BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING는 윈도우 프레임이 전체 파티션(또는 결과 집합)으로 확장됨을 의미합니다. 현재 행에서 윈도우 함수가 적용되는 범위를 첫 번째 행에서 마지막 행까지로 설정합니다.
LAST_VALUE(salary) OVER (ORDER BY salary DESC RANGE BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) 는 salary 열을 기준으로 내림차순으로 정렬하여 마지막 값(즉, 가장 낮은 급여)을 각 행에 대해 반환합니다. 여기서 RANGE BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING 구문은 전체 결과 집합을 범위로 지정하여 첫 번째 행에서 마지막 행까지의 범위를 포함합니다.
이 구문을 사용하면 현재 행과 상관없이 전체 데이터 집합에서 가장 낮은 급여를 정확히 찾을 수 있습니다.
RANGE BETWEEN 구문의 사용 예시
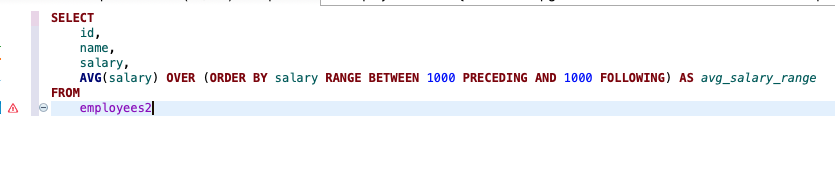
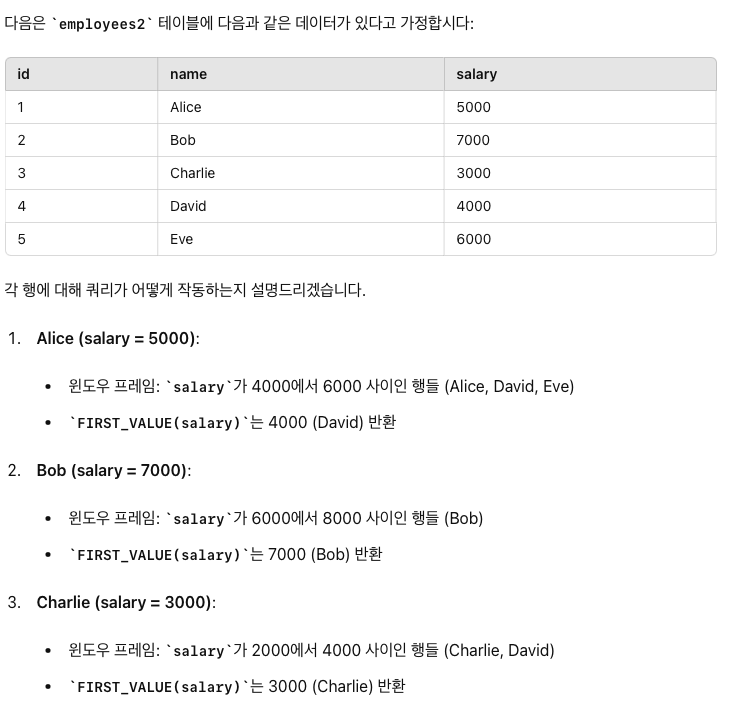
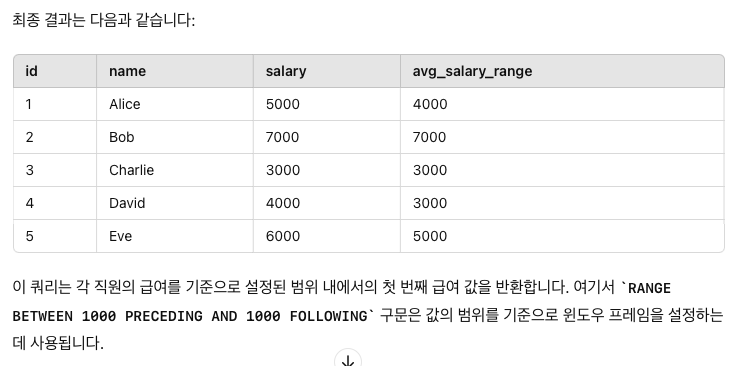
1. 현재 행에서 앞과 뒤로 특정 값 범위 지정:
RANGE BETWEEN 1000 PRECEDING AND 1000 FOLLOWING
RANGE BETWEEN 구문은 값의 범위를 기준으로 프레임을 지정합니다. 다음은 몇 가지 사용 예시입니다:
이 쿼리는 salary 열을 기준으로 정렬하고, 현재 행의 salary 값에서 1000 아래와 1000 위의 범위 내에 있는 salary 값들의 평균을 계산합니다.
첫번째 값을 가져오는데 salary 에서 +-1000 점 인애들중에서 첫번째값을 가져오라는 의미인데
예를 들어서

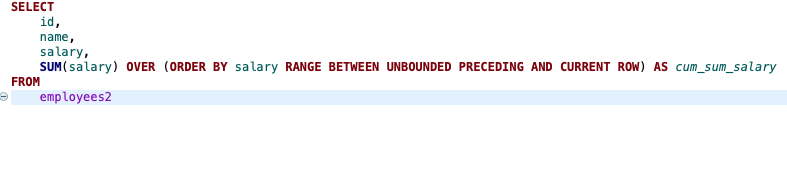
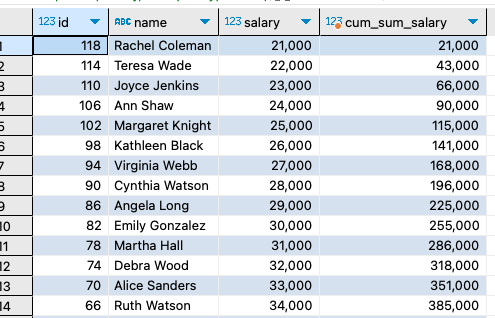
2.현재 행에서 앞의 모든 행 포함, 현재 행까지: (누적합계를 구할때 좋다)
RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW
ROWS BETWEEN 구문의 사용 예시
ROWS BETWEEN 구문은 행의 수를 기준으로 프레임을 지정합니다. 다음은 몇 가지 사용 예시입니다:
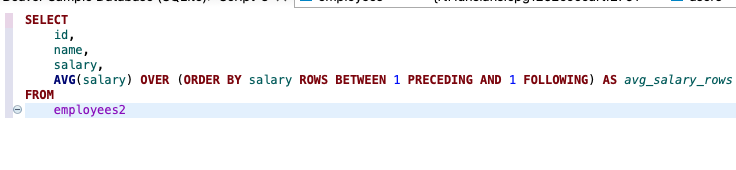
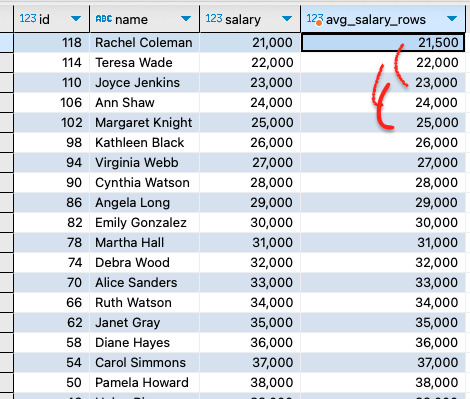
1. 현재 행에서 앞과 뒤로 특정 행 수 지정:
이 쿼리는 salary 열을 기준으로 정렬하고, 현재 행과 그 앞뒤 각각 한 행씩 포함한 3개의 행의 salary 값들의 평균을 계산합니다.
2. 현재 행에서 뒤의 모든 행 포함:
이 쿼리는 salary 열을 기준으로 정렬하고, 현재 행에서부터 마지막 행까지의 모든 salary 값들의 합계를 계산합니다.
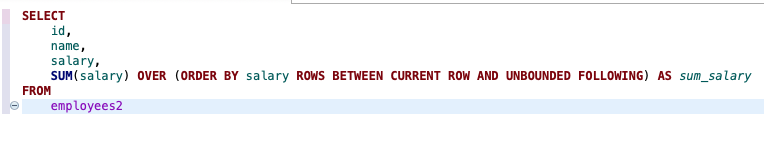
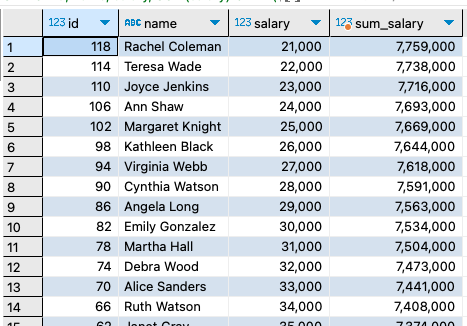
주요 차이점
RANGE: 값의 범위를 기준으로 프레임을 설정합니다. 예를 들어, 특정 값 이하 또는 이상의 범위를 지정할 때 사용합니다.
ROWS: 행의 개수를 기준으로 프레임을 설정합니다. 예를 들어, 특정 개수의 행을 포함할 때 사용합니다.
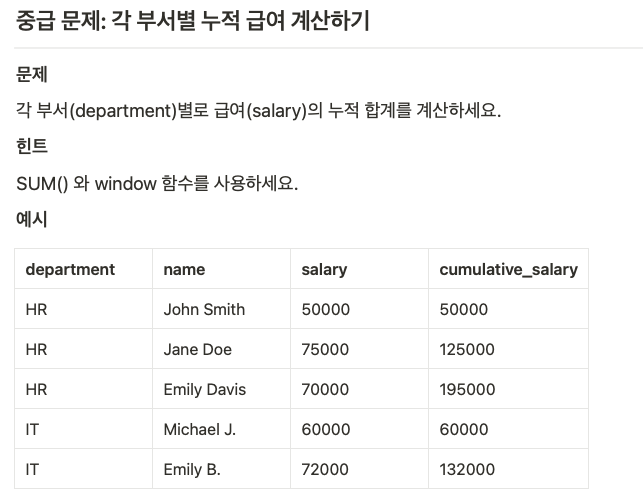
- SUM(), AVG(), COUNT() 등 집계 함수와의 조합
- 예제: 각 그룹별 누적 합계 계산

<<<<< 문제 풀어보기 >>>>>