DML
앞서 DML의 구조와 내용에 대해 간단히 찍먹해 보았다면, 이제 좀더 다양한 키워드들과 자세한 내용을 알아보도록 하자.

우선 위의 그림은 실제 Select문을 입력할 때 작성하는 쿼리의 순서이다.
앞에서 배우지 않은 Group by와 Having 그리고 Order by는 여기서 천천히 알아볼 것이므로 이런게 있구나라고만 생각하고 넘어가자.
Query 해석 순서(유효범위)
앞서 SQL의 특징에서 설명 했듯이 SQL은 쿼리의 순서에 상관없이 실행되는 완벽한 declarative언어이다.
(이로 인해 발생하는 Natural Join의 특징은 매우 중요하므로 잊지말자.)
이것은 명령을 수행하는데 순서가 없다는 뜻이지 해석하는데에 순서가 없다는 뜻은 아니다.
예를 들어 아래와 영어 문장을 생각해 보자
I want to connect student table and takes table and course table.
- 위의 문장을 해석해서 수행한다고 하자.
이 때 당연히 우리는 Table을 연결할 순서에 대한 생각은 하지 않고 단순히 3개의 Table을 연결하고 싶다는 생각만 할 것이다.
- 이번엔 위의 문장을 해석한다고 하자.
한국어와 영어는 해석 순서가 다르기 때문에 우리는 다시 한국어로 순서를 맞추어 이해할 것이다.
이와 같은 이유로 정의에 유효 범위가 발생한다. 다음과 같은 sql문을 보자.
select Course_ID as CID
from course
where CID > 10500;여기서 CID는 select절에서 Rename한 것이다.
즉, where절에서 CID를 만나면 컴퓨터는 아직 select절을 해석하기 전이기 때문에 CID가 무엇인지 이해할 수 없다.
즉, CID는 Select절이나 그 이후에 해석되는 곳에서 사용 가능하다.
1. From 절 (필수)
from instructor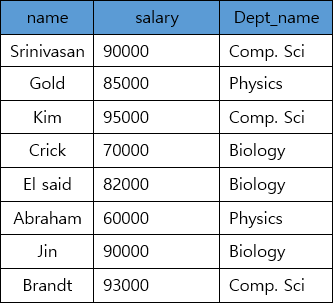
from절은 앞으로 사용할 Relation을 정하는 곳이다.
catesian product
natural Join
join using
Join using
Join on
natural join
join on
(실행순서 on -> join)
2. Where 절 (필수X)
from instructor
where salary > 80000;
- 목적
- From절에서 가져온 Relation중에서 가져올 Tuple을 정하기 위해 사용한다.
- 사용법
where+조건
- 작동 과정
- From절에서 가져온 Relation의 모든 Tuple을 검사하여 True, False, Unkown을 판별하고 True로 판별된 Tuple만을 골라서 가져온다.
3. Group By 절 (필수X)
from instructor
where salary > 80000
group by dept_name;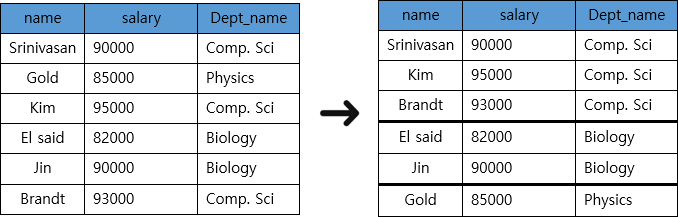
- 목적
- 후에 Select절에서 사용할 Aggregate함수를 Relation전체가 아닌, Group별로 적용하기 위해 사용한다.
- 사용법
group by+기준 Attribute
- 주의사항
- group by를 사용한 경우에는 반드시 Select절에서 Aggregate 함수를 사용해 주어야한다.
4. Having 절 (필수X)
from instructor
where salary > 80000
group by dept_name
having count(dept_name) <= 2; //count는 Aggregate함수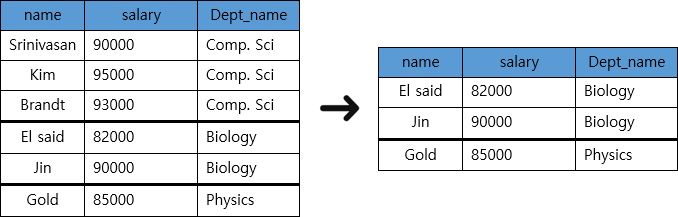
- 목적
- where절은 Group By이전에 해석된다. 따라서 Group으로 나눈 후에는 where절로 보고싶은 Group의 조건을 설정할 수 없다.
즉, 만약 Group별로 조건을 설정하고 싶다면 Having절을 사용하면 된다.
- 사용법
having+조건
- 주의사항
- group by가 있을 때에만 사용 가능
5. Select 절 (필수)
select dept_name, count(dept_name)
from instructor
where salary > 80000
group by dept_name
having count(dept_name) <= 2;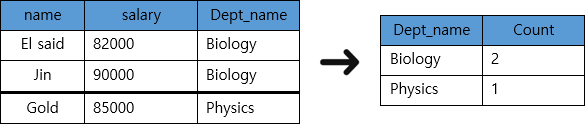
- 목적
- 앞서 배웠듯이 Project의 역할을 한다. 즉, 모든 선택을 마친 뒤 결과로 보여줄 Attribute를 고르기 위해 사용한다.
- 사용법
select+Attributeselect+Aggregate Function(집계 함수)(Attribute와 Aggregate Function 혼합사용 가능)
- 주의사항
- Group이 지정되어 있는 경우 Aggregate Function은 Group별로 수행된다.
- Attribute와 Aggregate Function을 같이 사용할 경우 반드시 그 개수가 같도록 선택해주어야 한다.
- Aggregate함수 사용 시 중복을 제거해야 하는 경우 반드시 distinct와 함께 사용해야 한다.
예시
Attribute + Aggregate Function
select salary, count(dept_name) // 오류발생: salary=3개, count(Dept_name)=2개) select max(salary), count(dept_name) // 정상작동: max(salary)=2개, count(Dept_name)=2개)distinct 활용
select count(distinct dept_name) // 출력결과: 교수가 있는 학과의 개수 from instructor; select count(dept_name) // 출력결과: 교수의 수 from instructor;
1) Aggregate 함수 종류
- avg(A): A의 평균
- min(A): A의 최소값
- max(A): A의 최대값
- sum(A): A의 합계
- count(A): A의 개수
(참고: count(*)는 해당 Table의 몇개의 Row가 있는지 알려줌)2) Aggregate 함수의 NULL처리
- count함수가 아닐 경우
- 모두 null일 경우: 결과도 null
- null이 아닌 것이 있는 경우: null을 제외한 나머지에 대해 함수 수행
- count함수의 경우
- count(*)의 경우 (null을 제외하지 않고 셈)
- 모두 null일 경우: Row의 수
- null이 있을 경우: Row의 수
- count(A)의 경우 (0부터 null을 제외하고 셈)
- 모두 null일 경우: 결과는 0
- null이 있을 경우: null을 제외하고 셈
6. Order By 절(필수X)
select name, salary, Dept_name
from instructor
where salary > 80000
order by salary desc; //order by salary asc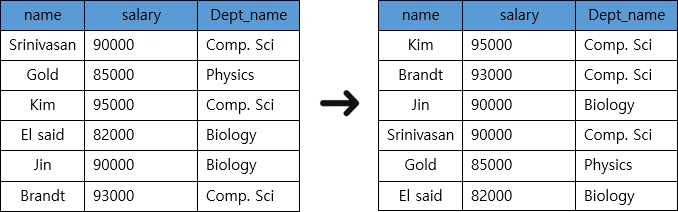
- 목적
- 모든 Instance선택을 마치고 결과Relation을 출력할 때, 정렬된 결과를 보고 싶은 경우 사용한다.
- 사용법(오름차순, 내림차순)
order by A asc: A를 기준으로 오름차순으로 정렬하여 출력한다. (이 경우 asc는 생략가능)order by A desc: A를 기준으로 내림차순으로 정렬하여 출력한다.
- 옵션(정렬기준 여러개 설정)
order by A, B desc, c: 이런 방식으로 정렬기준의 우선 순위를 설정할 수 있다.(이 코드는 A를 기준으로 오름차순 정렬하되, 같은 값을 가지면 B를 기준으로 내림차순, 이것도 같으면 C를 기준으로 오름차순 정렬하여 출력도록 하는 명령이다.)
SubQueries
Subquery는 Query안에 Query를 또 작성하여 표현하는 것을 의미한다. 이때 제일 바깥에서 Query를 시작하고 끝내는 역할을 하는 Query를 MainQuery라고 한다.
이 Subquery들은 쿼리의 어디에 위치하는지에 따라 하는 역할이 달라진다. 여기서는 각각의 상황에서 Subquery들을 어떻게 작성하고 해석해야 하는지 알아보자.
들어가기 전에...
먼저 몇가지 특징을 만족할 때 다음과 같이 불리는 SubQuery들이 있다. 이 특징들과 용어를 기억해 두자
1) Scalar Subquery
- 조건
- Scalar Subquery는 단일 값만 가지는 Relation을 결과로 내는 Subquery이다.
- 예시

2) Correlative Subquery
- 조건
- Correlative Subquery는 MainQuery에 상관없이 독립적으로 실행 될 수 없는 Subquery를 의미한다.
- 원인
- Correlated Name
: Main Query에서 Attribute나 Table의 이름을 재정의 하고 이를 Subquery에서 사용하고 있을 때- Correlation Variable
: Main Query에서 가져온 Attribute를 SubQuery에서도 사용할 경우에 해당한다.
- 예시
- Correlated Name
select distinct course_id from section as s where semester = 'Fall' and year = 2009 and course_id in (select course_id from s where semester = 'spring' and year = 2010);
- Correlation Variable
select course_id from section as s where semester = 'Fall' and year=2009 and exists(select* from section as t where semester='spring' and year=2010 and s.course_id=t.course_id);
1. from절에 들어가는 경우
우선 from절은 우리가 처음 가져올 Relation을 결정하는 역할을 했었다. 즉, from절의 Subquery는 MainQuery를 실행하기 전에 Relation을 가공할 때 사용할 수 있다.
1) Deal in Group
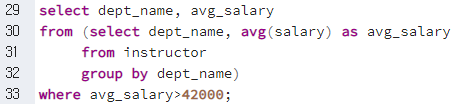
- 목적
- 우리는 group by으로 묶은 Relation에 대해 where절에서 가공할 수 없었다.
이를 해결할 수 있는 방법으로 다음과 같은 방법을 사용할 수 있다.
- having절을 사용하는 방법
- from절에서 Subquery를 사용하는 방법
- 예시
select dept_name, avg_salary from (select dept_name, avg(salary) from instructor group by dept_name) as dept_avg(dept_name, avg_salary); //as 테이블이름(Attribute이름)(참고: Postgre SQL에서는 from절에 들어가는 Subquery는 반드시 Rename해서 사용하게 하도록 한다.)
2) with키워드
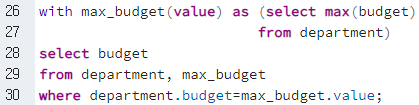
- 목적
- from절 안에 Subquery를 넣을 경우 문장이 복잡해 져서 읽기 어려워 질 수 있다.
이때, 처음에 Subquery를with와 같이 표현하고 from절에서 가져오면 사용할 수 있다
- 사용법
with 테이블이름(칼럼 이름) as (select ~ ), 테이블이름(칼럼 이름) as (select ~ ), ...
- 예시
with dept_total(dept_name, value) as (select dept_name, sum(salary) from instructor group by dept_name), dept_total_avg(value) as (select avg(value) from dept_total) select dept_name from dept_total, dept_total_avg where dept_total.value = dept_total_avg.value;
2. where절에 들어가는 경우
where절은 가져올 Tuple에 대한 조건을 설정할 때 사용했었다.
즉, where절에 사용할 경우 좀 더 다양한 조건을 설정할 수 있게 되는데 이는 원하는 목적에 따라 다음과 같이 나누어 볼 수 있다.
1) Set Membership, (in)
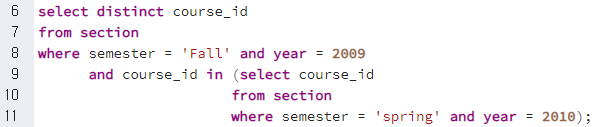
- 목적
- 두 Relation의 교집합을 확인하여 두 Relation의 교집합 또는 차집합을 구할 때 사용한다.
- 사용방법
- 논리 연산자
in과 함께 사용한다.where+A+in+Subquery(
in: A중, Subquery에 포함되는 것만을 True로 만든다.)
(not in: A중 Subquery에 포함되지 않는 것만을 True로 만든다.)
- 예시
select distinct course_id from section where semester = 'Fall' and year = 2009 and course_id in (select course_id from section where semester = 'spring' and year = 2010);select distinct course_id from section where semester = 'Fall' and year = 2009 and course_id not in (select course_id from section where semester = 'spring' and year = 2010);
- 참고1
위의 두 예시는 각각 다음 SQL문장과 같은 역할을 한다.
(select course_id from section where semester = 'Fall' and year = 2009) intersect (select course_id from section where semester = 'Spring' and year = 2010);(select course_id from section where semester = 'Fall' and year = 2009) except (select course_id from section where semester = 'Spring' and year = 2010);
- 참고2
다음과 같이in을 Relation이 아닌 Tuple에서의 포함관계를 파악할 때 활용하는 것도 가능하다.
where Attribute in ('a', 'b');
2) Set Comparison, (some/all)

- 목적
- 서로 다른 두 Relation의 값들을 비교하기 위해서 사용한다.
- 사용방법
- 논리 연산자
some과all과 함께 사용한다.where+A+비교연산자+some/all+Subquery- 비교연산을 위해서 subquery의 결과가 Multi-Column가 되지 않도록 주의하자.
(
some: A중, Subquery의 하나의 tuple에 대해서라도 비교식을 만족하는 것만을 True로 만든다.)
(all: A중, Subquery의 모든 tuple에 대해 비교식을 만족하는 것만을 True로 만든다.)
- 예시
select name from instructor where salary > some (select salary from instructor where dept_name='Biology');
- 참고1
- 위의 예시는 다음 SQL문장과 같은 역할을 한다.
select distinct T.name from instructor as T, instructor as S where T.salary > S.salary and S.dept_name='Biology';
- 참고2
= some은in과 같은 역할을 한다.
(!= some이not in인 것은 아니다.)!= all은not in과 같은 역할을 한다.
(= all이in인 것은 아니다.)(ex.
5 = some (4, 5): True,5 != some (4, 5): True)
(ex.5 = all (4, 5): False,5 != all (4, 6): True)
3) Set Cardinality, (exists)

- 목적
- 해당 Subquery가 존재하는지(공집합이 아닌지) 확인할 때 사용한다.
- 사용방법
- 논리 연산자
exists와 함께 사용한다.where+exists+Subquery(
exists: 뒤에 나오는 Relation이 비어있지 않으면(존재하면) True로 만든다.)
(not exists: 뒤에 나오는 Relation이 비어있으면(존재하지 않으면) True로 만든다.)
- 예시
select course_id from section as s where semester = 'Fall' and year=2009 and exists(select* from section as t where semester='spring' and year=2010 and s.course_id=t.course_id);
- in과 exists의 차이
in+Subquery
- 해석순서: Subquery -> Mainquery
- 용도: Element와 Relation의 포함관계를 찾을 때 사용
exists+Subquery
- 해석순서: Mainquery -> Subquery
- 용도: Relation과 Relation의 포함관계를 찾을 때 사용
(exists는 공집합인지에 대한 여부만 파악하기 때문에 in보다 연산수가 더 적고 따라서 더 빠르다)
- 중요: "포함관계 파악" 구현
not exists와except를 활용하면 Relation간의 포함관계를 확인할 수 있다.
select distinct s.ID, s.name from student as s where not exists((select course_id from course where dept_name='Biology') except (select t.course_id from takes as t where s.ID = t.ID));
4) Extract that are not Duplicated, (unique)

- 목적
- Subquery의 결과 중 중복된 적이 없는 Tuple들만 뽑아내기 위해서 사용한다.
- 사용방법
- 논리연산자
unique와 함께 사용한다.where+unique+Subquery- 해석순서: main query -> subquery
(
unique: Subquery의 Tuple들중 중복이 없었던 것들만 true로 만든다.)
- 예시
select T.course_id from course as T where unique (select R.course_id from section as R where T.course_id = R.couse_id and R.year=2009);
- 참고
- 위의 예시는 다음 문장과 같다.
(unique는 대부분의 db에서 제공되지 않는다. 만약 사용하는 db에서 unique를 제공하지 않는다면 이와 같은 방법으로 사용해주자.)select T.course_id from course as T where 1 = (select count(R.course_id) from section as R where T.couse_id = R.couse_id and R.year=2009);
3. select절에 들어가는 경우
앞서 Select를 공부할 때 가장 중요했던 점은 일반 Attribute를 사용하던, Aggregate Function를 사용하던 결과적으로 그 개수를 맞추어 사용해야 한다는 것이었다.
이것은 Relation의 대원칙인 값이 Atomic해야 한다는 특성을 지키기 위해서 이기 때문이다.
즉, Select절에 들어가는 Subquery도 마찬가지로 이를 지키기 위해 그 결과로 단일값을 가져야 한다.
1) Scalar Subquery

- 목적
- Select절에 Subquery를 작성할 경우 가장 큰 장점은 보고 싶은 것을 단순 나열하기 때문에 가독성이 좋다는 점이다.
- 사용법
select+(Scalar Subquery) as A+...
- 단점
- subquery를 tuple의 수만큼 실행해야 하기 때문에 효율적이지 못하다.
(참고: 위의 장점보다 단점이 너무 명확하고 크기 때문에 실제로는 잘 사용하지 않는다.)
- 예시
select dept_name, (select count(*) from instructor where department.dept_name = instructor.dept_name) as num_instructors from department;
- 생각해 볼 부분
- 아래의 코드와 위의 예시는 다르게 작동한다. 왜그런지 생각해 보자.
select dept_name count(ID) from instructor group by dept_name;
위의 코드는 department라는 Relation을 참고한다.
아래의 코드는 instructor라는 Relation을 참고한다.즉, 만약 교수가 하나도 없는 department가 있다고 할 때,
위의 코드에서는 department에 소속 교수가 없다고 잘 나오지만,
아래의 코드에서는 해당 department자체가 출력되지 않게된다.
