https://newindow.tistory.com/254
1. Data Augmentation
데이터의 불균형을 해결해줌
-
데이터 불균형
- 클래스 불균형
- 데이터 패턴의 불균형
(ex. 사진의 구도) - 즉, 우리가 확인하지 못한 데이터들이 수없이 많음
-
Crop, Cutmix는 이미지 데이터에 있어서 손쉽게 성능향상을 불러옴
(주의: Cutmix를 사용할 경우 라벨데이터도 바꿔줘야함) -
randaugmentation
1) 밝기조절
2) rotate
3) Crop
4) Affine Transform
찌그러 뜨리는 것
5) Cutmix
6) Rand Augment
여러가지 처리 방법을 조합해 새
2. Pretrained Model활용
1) Transfer learning
한 데이터셋에서 얻은 지식을 다른 데이터셋에서 활용하는 것
ex) 이미지넷 데이터셋 -> 동물 분류 데이터셋
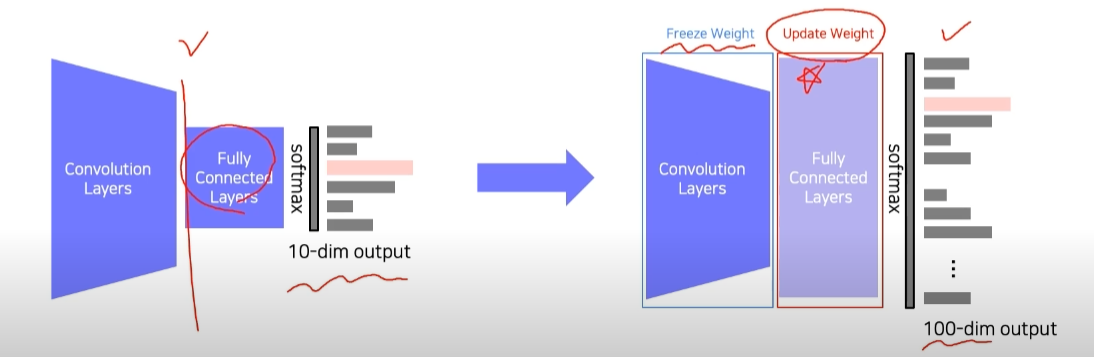
1. freeze
주로 다음과ㅏ 같이 Convolution layer는 고정시키고 FC layer만 변경하여 사용
주어진 데이터가 적을 때 유용하게 활용할 수 있음
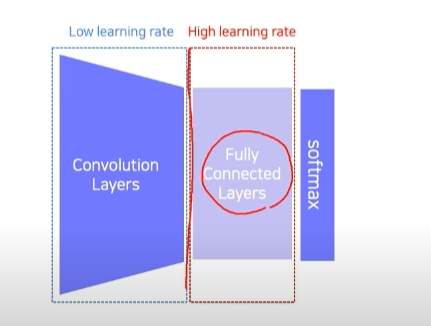
2. fine-tuning
모두 학습하긴 하는데 Convolution layer는 낮은 learning rate로 학습
주어진 데이터가 많을 때 유용하게 활용할 수 있음
3. Teacher-Student Networks
Knowledge Distillation기법을 이용
pre train된 모듈을 이용하는 더 진보된 방법
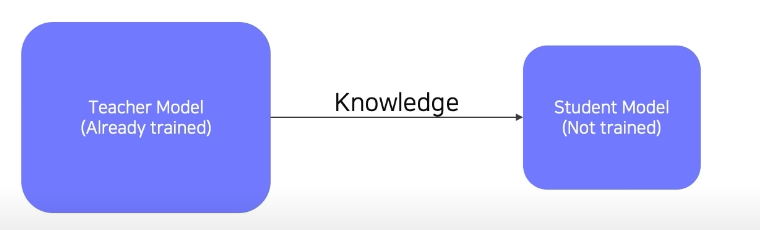
주로 큰 모델에서 생성된 정보를 작은 모델에 적용
3. Unlabeled Dataset활용
1) Semi-Supervised learning
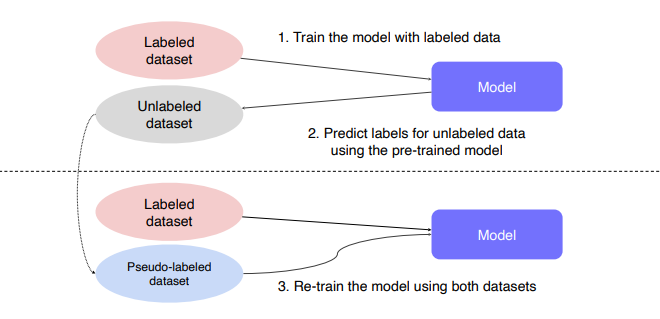
unlabeled data활용
- labeled data로 모델을 학습
- 해당 모델로 unlabeled data의 psudo-label을 달아줌
- labeled data + pseudo-labeled로 1번에서 학습시켰던 모델을 재학습시킨다.
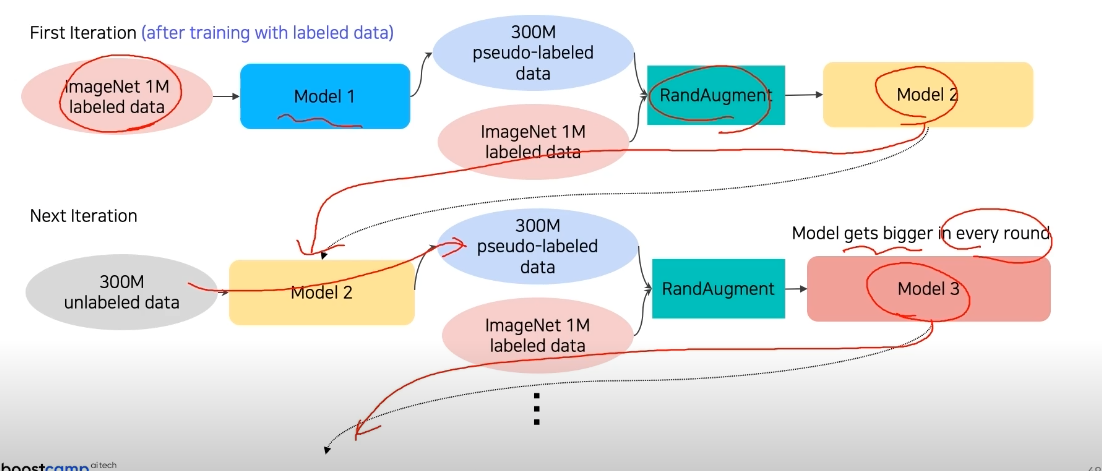
2) Self-Training
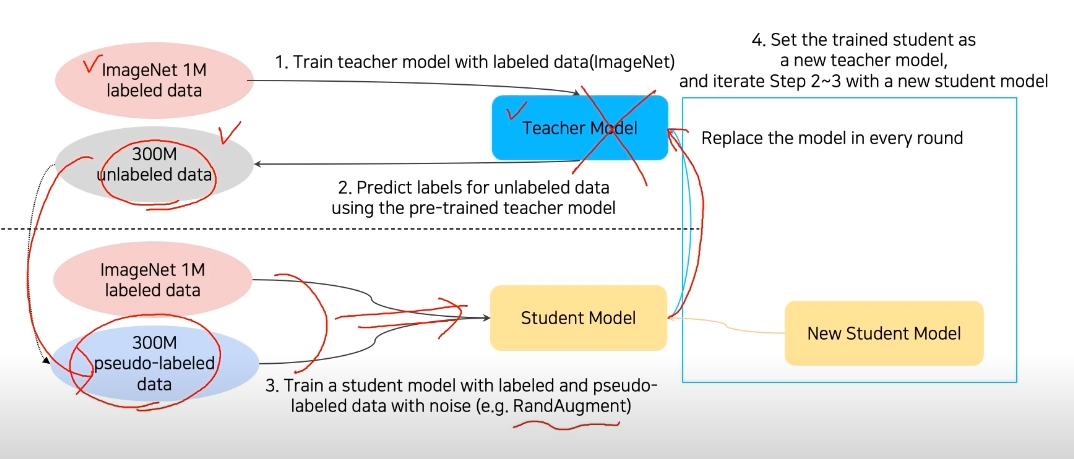
augmentation
Teacher-Student Networks
semi-supervised learning
을 합쳐서 만듦
hard nevative mining
Label Smoothing
focal loss

github로 이전 중... (https://uijinee.github.io/)