이번에는 만들어진 Data Base를 평가하는 방법에 대해서 알아보자.
이 방법에 대해 생각해보기에 앞서 우선 다음과 같은 Relation을 평가해보자.
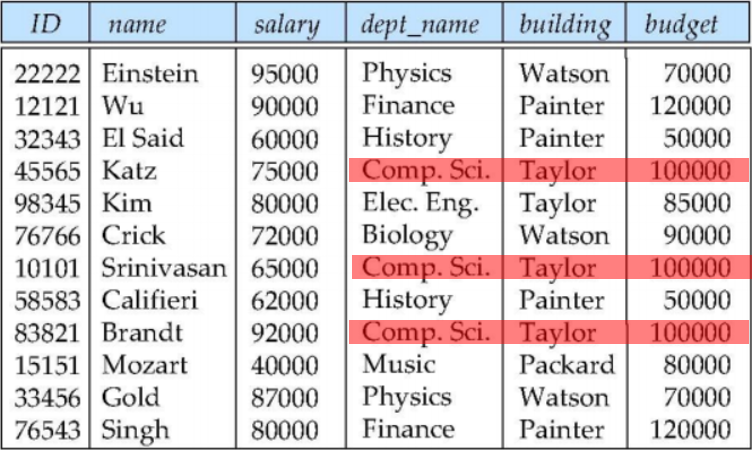
표시해 놓은 곳을 보면 알 수 있듯이 해당 Relation은 중복된 Relation을 반복해서 표현하고 있다.
이럴 경우 다양한 문제가 발생할 수 있게 되는데, 우선 해당 Relation에서 katz, srinivasan, brandt가 없어질 경우 Comp.Sci는 아예 없었던 데이터가 되어버린다.
뿐만 아니라 데이터를 수정하거나 삭제할 경우에도 중복된 데이터를 가지고 있는 모든 Tuple에 같은 작업을 해 주어야 하므로 비용적인 문제도 발생한다.
즉, 우리는 데이터의 Redendency의 정도에 따라 우리가 만든 Relation의 좋고 나쁨을 결정해 볼 수 있다.
용어
1. Functional Dependency

다시말해, 어떤 Attribute Set이 다른 Attribute Set을 결정(구분)하는 관계를 뜻한다.
(중요)
Functional Dependency는 Relation에서 나타나는 현상이 아닌, 사용자가 정한 규칙을 의미한다.즉, 어떤 Relation에서 우연히 해당 조건을 만족하더라도 그것은 Functional Dependency가 아니다.
1. 표기법
: a가 b를 결정하는 관계는 위와 같이 표기한다.
2. Trivial
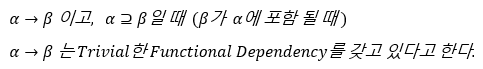
: 잘 생각해 보면 이 경우 functional dependency는 당연해진다.
3. 참고: Key의 정의

: Relation에서 Attrbute Set이 Unique하다는 것은
해당 Attribute Set이 결정되면 해당 Relation의 모든 값을 구분할 수 있다는 것을 의미한다.
2. FD의 Closure

1) 표기법
: F를 통해 유도 가능한 모든 Functional Dependency의 집합을 의미한다.
2) 방법
1. Armstrong's Axiom(공리)
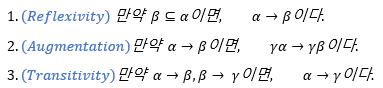
: 이 Armstrong's Axiom을 F가 더이상 변하지 않을 때까지 반복하여 적용하면 F의 Closure을 구할 수 있게 된다.
2. Additional Rules
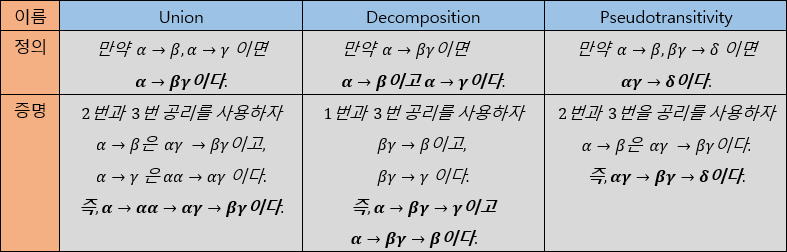
: 위의 Armstrong's Axiom을 통해 위와 같은 규칙 또한 유도할 수 있다.
3) Code
즉, functional dependency의 계산은 O(2^n)의 시간 복잡도를 갖는다.

3. Attribute Set의 Closure

1) 표기법
: A를 통해 결정 가능한 모든 Attribute Set의 집합을 의미한다.
2) 방법
a->a+가 있다고 하자.
a+의 초기값은 a라고 설정한다.
- 주어진 F를 모두 검사한다. 즉, 모든
b->c를 검사한다.
- 이 때,
b가a+에 속해있을 경우c를a+에 추가한다.
- 이것을
a+가 변하지 않을 때 까지 반복한다.
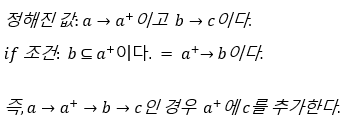
3) 코드
즉, attribute dependency의 계산은 O(n^2)의 시간 복잡도를 갖는다.
즉, 특정 Attribute가 key인지 확인할 경우에 사용하면 편하다.

Normal Form
(2nd Normal Form은 난잡하고 별로 중요하지 않아 설명 x)
맨 위에서 보았듯이 데이터의 Redendency는 Relation을 평가하는데에 중요한 역할을 한다. 하지만 이 Redendency를 완전히 없앤다고 꼭 좋은 것 만은 아니다.
이 점을 다음의 normal form들에 대해 살펴보면서 생각해 보자.
- First Normal Form
- Second Normal Form
- Third Normal Form
- Boyce-Codd Normal Form(BCNF)
#정의
Normal Form이란 정해진 특정 제약 조건을 만족하는 형태의 Relation이라고 할 수 있다.
이때, 이 조건은 Redendency를 줄이기 위한 조건으로, Functional Dependency의 관점에서 정의되고, 이것은 BCNF로 갈수록 점점 추가된다.
즉, 중복된 데이터를 줄이기 위해 Functional Dependency의 개념을 사용할 것인데, 이 때 필요한 조건들을 각 Normal Form들에서 추가해 준다는 것이다.
#목표
우리는 결과적으로 Third Normal Form의 형태를 갖는 Relation들이 BCNF나 3NF의 형태가 되도록 만들어야 한다.
이를 위해서는 중복된 데이터를 가진 Relation을 Decompose해야 한다.
이 때, 가장 중요한 점은 Decompose할 때 반드시 Loss가 발생해서는 안되고, 될 수 있으면 Dependency Preserving이 되도록 하자. (뒤에서 설명)
- Lossless-join Decomposition
- Dependency Preserving (될 수 있으면)
1. First Normal Form
<그림>
1) 정의
모든 Attribute의 domain은 atomic해야 한다.
(중요)
atomic은 나눌 수 없다는 뜻이다.즉, Data Base를 사용하는 입장에서는 해당 Attribute의 값을 사용할 때, Parsing해서 사용하지 않아야 한다.
(사용하고자 한다면 따로 Attribute를 만들어야 함)이 조건으로 인해 DB의 설계 측면과 db사용 측면의 역할을 나눌 수 있게 됨
2) FD와의 관계
모든 attribute는 반드시 atomic해야 한다.
= 어떤 하나의 attribute는 반드시 나머지 attribute를 결정하는 역할을 해야한다.
= 모든 Relation은 반드시 Key를 가져야 한다.
= "모든 relation은 functional dependancy가 존재해야 한다."
(만약 atomic하지 않은 value가 있을 경우 Key가 해당 Attribute의 값을 하나로 결정 할 수 없기 때문에)
2. Boyce-Codd Normal Form
<그림>
(참고로 BCNF를 만족하는 Relation이라는 의미는 1NF도 만족시킨다는 의미이므로 주어진 F가 존재한다.)
1) 정의
주어진 F에 대해 F의 Closure는 반드시 다음의 조건 중 적어도 하나를 만족해야 한다.
- Trivial한 것을 나타내는 FD이다.
a->b에서 a는 Relation의 Superkey이다.
2) FD와의 관계
a->b에서 a는 Relation의 Superkey이다.= a가 Relation의 Superkey가 아닐 경우
a->b의 a가 될 수 없다. (대우법)= Key를 제외한 나머지의 Attribute는 다른 Attribute를 결정하는 역할을 해서는 안된다.
= "Relation을 결정하는 Functional Dependency외에 다른 Functional Dependency가 존재해서는 안된다."
3) BCNF로 변환하는 방법
1. Decomposition
2. Lossless-Join Decomposition
조건
1. r을 r1, r2로 decomposition할 때, 교집합이 다음을 만족해야 한다.
-> r1 n r2 -> r1 (교집합의 attribute가 r1의 key역할을 한다.)
또는
-> r1 n r2 -> r2 (교집합의 attribute가 r2의 key역할을 한다.)
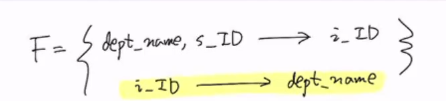
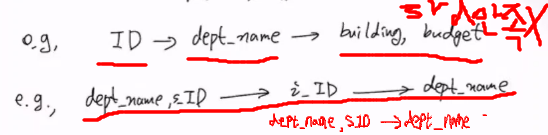
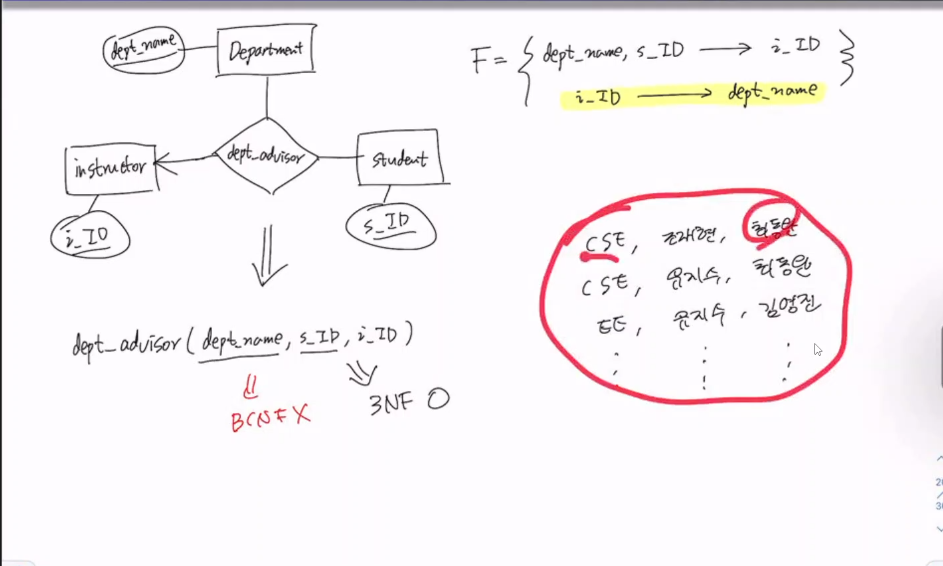
3. Dependency Preserving
BCNF를 만족하도록 decompose하는 방법
a->b가 BCNF를 위반하는 조건이라고 할 때,
(주의: 두 Relation의 연결을 위해 원래의 Relation R에는 a를 남겨놔야 함)
이 때, 나눠진 Relation중 a, b로 이루어진 Relation에서 a가 key의 역할을 하기 때문에 lossless decomposition이다.
예시
따라서 decompose하면


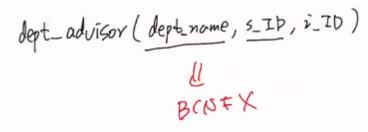
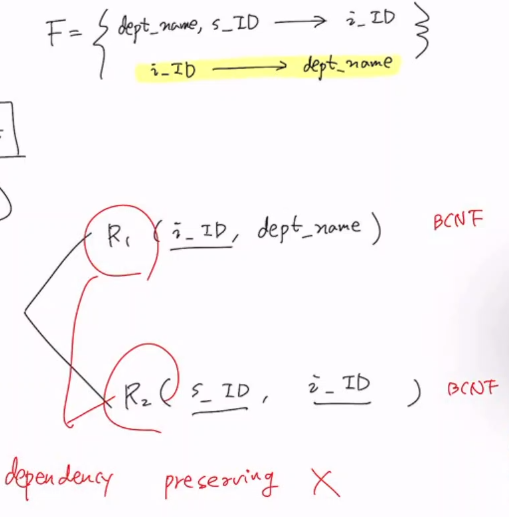
4) BCNF의 단점
dependency preserving이 안될 수 도 있음
decomposition이 dependency Preservation하다는 것이란?나눠진 Relation을 r1, r2 라고 하고, 나눠진 functional dependency는 f1, f2라고 할 때
f1은 r1만을 가지고도 검사할 수 있어야 하고
f2는 r2만을 가지고도 검사할 수 있어야 한다.
예를들어
즉, DF를 검사할 일이 많다거나, 동작 시간을 단축시키고 싶다거나 할 경우 BCNF를 사용하지 않을 수 도 있음
이 때, 3rd normal form 사용
dependency preserving을 보장하기 위해서는 중복을 좀 더 허용해야 된다.
이 때, 3rd normal form에서는 BCNF보다 중복을 좀 더 허용하더라도 dependency preserving이 항상 보장된다.


3. Third Normal Form
<그림>
1) 정의
주어진 F에 대해 BCNF를 만족하거나, 다음의 추가 조건을 만족해야 한다.
- Trivial한 것을 나타내는 FD이다. (BCNF)
a->b에서 a는 Relation의 Superkey이다. (BCNF)b-a에 속하는 각 Attribute들은 모두 Candidate Key에 속해있어야 한다. (3NF)
2) FD와의 관계
a->b에서 a는 Relation의 Superkey이다.= "Relation을 결정하는 Functional Dependency외에 다른 Functional Dependency가 존재해서는 안된다." (BCNF)
b-a에 속하는 각 Attribute들은 모두 Candidate Key에 속해 있어야 한다.= "Transitivity Dependency from a key가 없는 Relation이어야 한다."
3) 3NF vs BCNF
1. Transitivity Dependency란?
Functional Dependency로 어떤 Attribute들의 관계가
a->b->c와 같이 주어질 때,c는a에 Transitivity Dependency가 있다고 함.즉, 직접적인 Dependency는 없으나 중간에 다른 Attribute를 거쳐 결정되는 관계에 있다는 것을 의미한다.
2. 3NF
즉,
Key->B->C와 같은 관계가 없는 Relation이어야 한다는 뜻이다.예를들어
일 때,
로,
위는 transitivity dependency가 있어 3rd normal form을 만족하지 않음.
아래는 transitivity dependency가 없으므로 3rd normal form을 만족.
3. 3NF vs BCNF