배경
- 우리 챗봇 서비스는 생성 AI를 사용하여 응답을 제공한다.
- ChatGPT와 HyperClova를 사용한다.
문제 발생
부하 테스트를 하는 도중 네이버 HyperClova에 Request를 보냈을때
초당 4개가 넘으면 "Too many request" 에러가 발생되었다.
현재 테스트앱말고 서비스앱을 신청해서 사용하고 있지만
하이퍼 클로바는 아직 베타 테스트 버전이기 때문에 서비스 앱의
QPM(query per minute)을 200으로 제한하고있었다.
그래서 RPS(Request per second)가 4를 넘지 못하고 에러가 발생되는 것이다.
외부 API를 사용할때 종종 제한하는 경우가 있다고 들었지만,
처음 경험해보니 먹먹했다.
왜냐하면, 우리 서비스는 일상대화로 많은 요청이 필요하기 때문이다.
문제 정의
문제를 정의하면 Clinet의 요청이 내 서버로 100개가 들어오더라도,
100개의 요청을 초당 4개로 나눠서 보내야했다.
Interval request, Back Pressure 등 다양한 키워드로 검색해봤지만, 찾기 어려웠다.
삽질 과정
Python Celery 에서 제공하는 비동기 큐를 사용하면 해결이 될 것이라고 생각했다.
하지만, 큐에서 꺼내서 다시 요청을 보내야하고, 그 요청을 받아서 client에게 전달하는 방법을
구현하는게 어려웠다.
Celery를 공부하면서 아주 좋은 프레임워크라는 것을 알게되었지만,
현재 문제에서는 적합하지 않다고 판단했고, Redis와 Celery worker 등 환경셋팅하는 부분이
많아져서 포기했다.
문제 해결
해결 방법은 생각보다 아주 간단했다.
바로 요청을 제한하는 것이다, 나는 분할하는 것만 생각했고 제한하는 방법은 생각하지 못했었다.
요청을 제한하는 방법은 간단하다.
비동기 요청을 보낼때, 세마포어(Semaphore)의 수를 제한하는 것이다.
from fastapi import FastAPI
import asyncio
app = FastAPI()
# 최대 4개의 동시 요청을 처리할 수 있는 세마포어 생성
semaphore = asyncio.Semaphore(4)
@app.get("/")
async def get_endpoint():
async with semaphore:
# 세마포어를 획득한 후 실행할 비동기 작업
# 예를 들어, 여기에서 데이터베이스 쿼리 또는 외부 API 호출 수행
await asyncio.sleep(2)
return {"message": "Request processed"}
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=8000)이렇게 하면 엔드포인트가 동시에 최대 4개의 요청만 처리하도록 제한되고,
나머지 요청은 대기 상태에 있으며 세마포어가 해제될 때 실행된다.
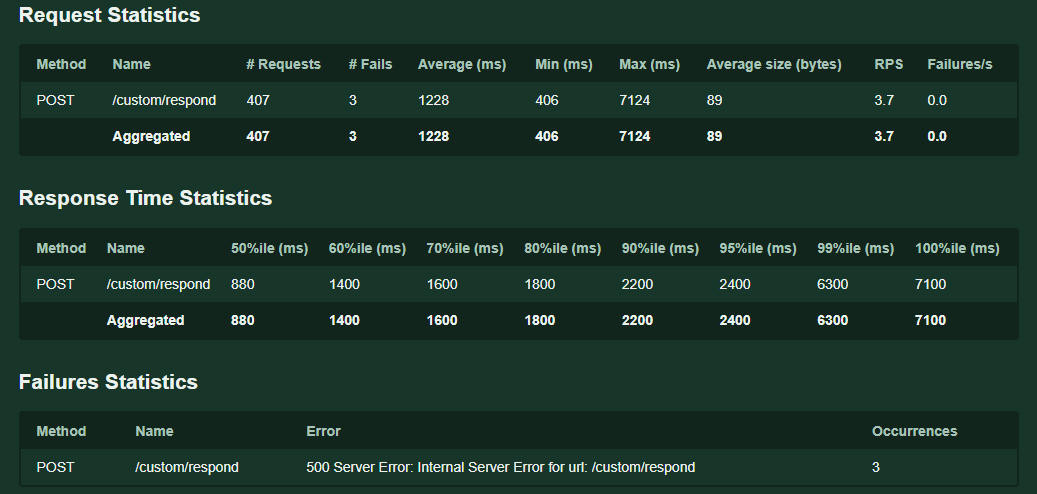
결과
요청이 몰려도 "Too Many Reqeust" 에러는 발생하지 않았고
에러비율은 1%로 떨어졌다.
대신에 평균 0.6~0.7초였던 처리시간은 요청 수에따라 늘어났다.
하지만 우리 서비스에서 생각하는 5초는 넘지않았기에
원하는 결과를 얻었다고 볼수있다.