sql
TROUBLE SHOOTING
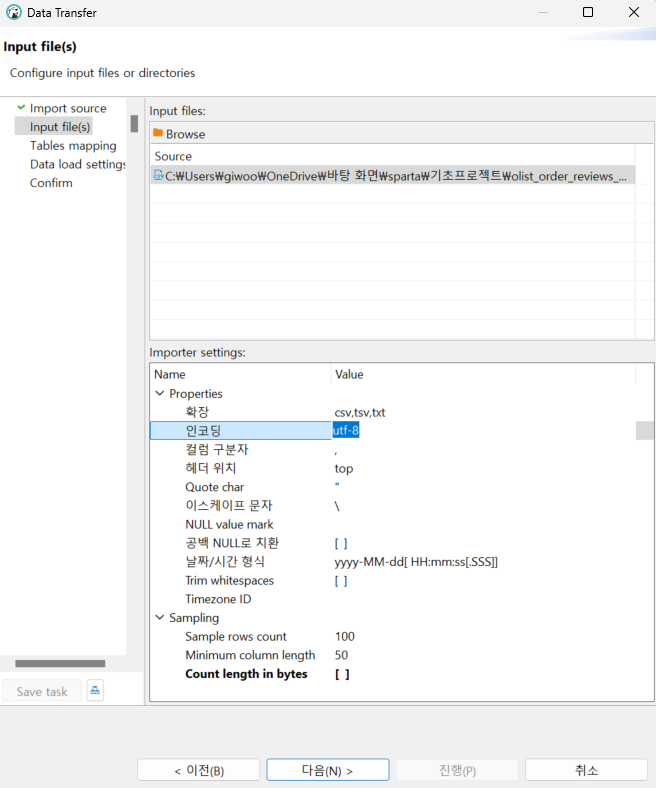
UTF-8 encoding 해야 스페인어를 깨짐 없이 볼 수 있다.
euc-kr 은 한국어
나머지는 utf-8 로 이해하면 된다.
DataBase Navigator - importer settings 에서 인코딩을 수정할 수 있다.
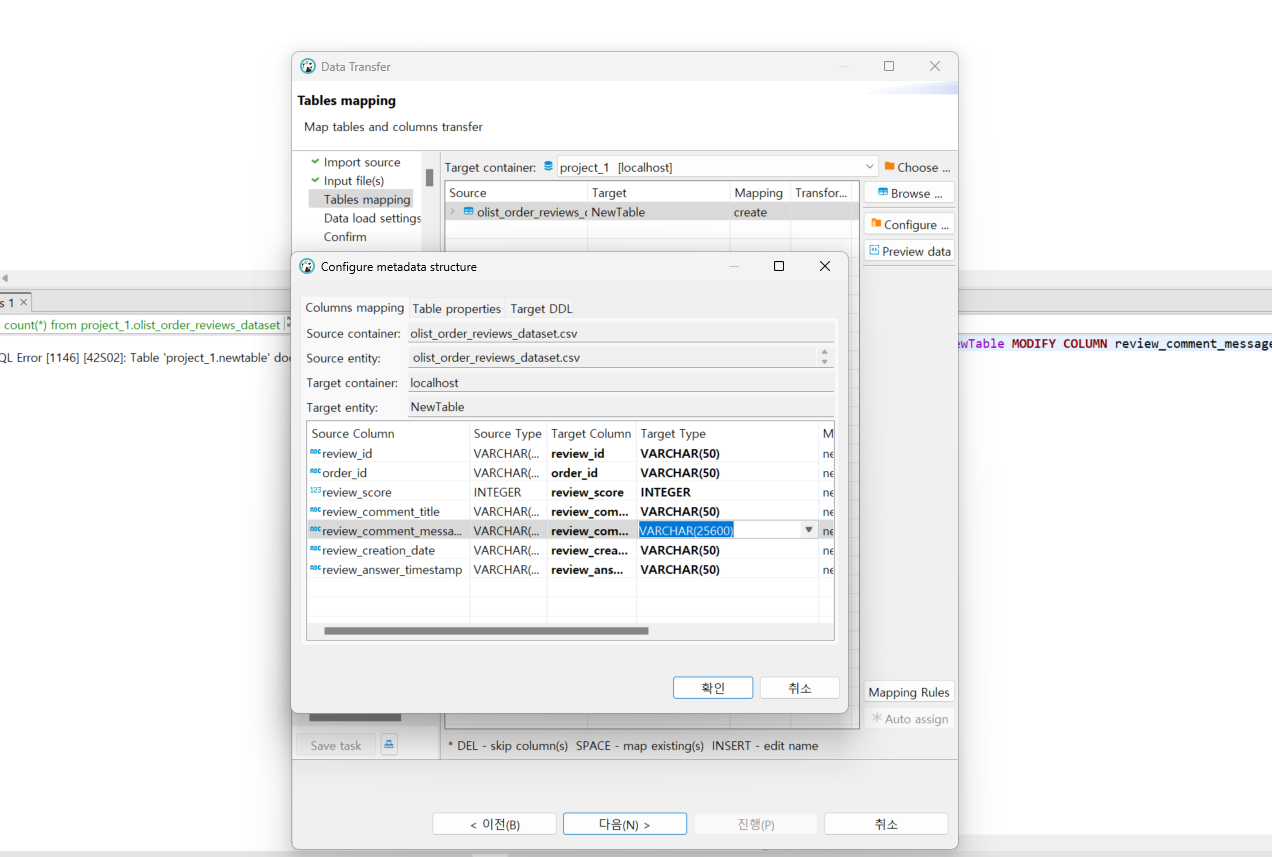
또한 각 칼럼의 길이를 조정해야 할 땐 table mapping - configre table and columns structure 버튼을 누르면 조정이 가능하다.
using
table join의 방법에는 join - on 을 사용하는 방법과 join - using 을 사용하는 방법 총 2가지가 있다.
using을 사용하면 using clause 위에 공통이 되는 칼럼 이름 하나만 적으면 되기에 on을 사용했을 때보다 훨씬 편하며 간결하다.
# on 사용
SELECT
customers.customer_id,
customers.customer_name,
orders.order_date
FROM
customers
JOIN orders
ON customers.customer_id = orders.customer_id
# using 사용
sql
코드 복사
SELECT
customer_id,
customer_name,
order_date
FROM
customers
JOIN orders USING (customer_id)[기초 프로젝트 쉐도윙] 파이썬과 sql 데이터 폴더 연결하기
import sqlite3 # 가벼운 sqlite를 import
db_path = 'olist.sqlite\olist.sqlite'
db_connection = sqlite3.connect(db_path) # sql데이터가 저장된 위치를 변수에 저장
import pandas as pd # df생성과 전처리를 위해 pandas library 설치
def view_table(table, limit):
query = f"""
SELECT *
FROM {table}
LIMIT {limit}
"""
return pd.read_sql_query(query, db_connection) # 가장 중요한 함수[기초 프로젝트 쉐도윙] ⭐pd.read_sql_query(sql쿼리 문자열, 연결 객체)
orders_per_day = """
SELECT
DATE(order_purchase_timestamp) AS day,
COUNT(*) AS order_count
FROM orders
GROUP BY day
"""
df = pd.read_sql_query(orders_per_day, db_connection)
df.head(10)
# pd.read_sql_query(실행할 sql쿼리 문자열, 연결 객체) : 쿼리 결과를 pandas dataframe으로 가져온다.
# """ """ 를 통해 sql 쿼리를 문자열로 바꿔준 이유는 pd.read_sql_query() 의 함수 구조 때문이다. [기초 프로젝트 쉐도윙] matplotlib
- matplotlib: python의 대표적인 시각화 라이브러리
- matplotlib.pyplot: 시각화를 위한 기본적인 플롯 제공(선, 막대, 히스토그램 등)
- matplotlib.dates: 시간 데이터와 관련된 기능을 제공. 날짜와 시간을 포함하는 데이터의 시각화를 돕는다.
[기초 프로젝트 쉐도윙] 귀찮으면 머리 쓰던지 ㅋㅋ
고수들은 case when~ 처럼 반복 작업이 필요함 sql 쿼리를 python list comprehension을 통해 작성한다.
count_orders_per_hour = ',\n '.join([
f'COUNT(CASE WHEN hour = {i} THEN 1 END) AS "{i}"' \
for i in range(24)
])
orders_per_day_of_the_week_and_hour = f"""
WITH OrderDayHour AS (
{order_day_hour}
)
SELECT
day_of_week_name,
{count_orders_per_hour}
FROM OrderDayHour
GROUP BY day_of_week_int
ORDER BY day_of_week_int
"""
결과
ay_of_week_name,
COUNT(CASE WHEN hour = 0 THEN 1 END) AS "0",
COUNT(CASE WHEN hour = 1 THEN 1 END) AS "1",
COUNT(CASE WHEN hour = 2 THEN 1 END) AS "2",
COUNT(CASE WHEN hour = 3 THEN 1 END) AS "3",
COUNT(CASE WHEN hour = 4 THEN 1 END) AS "4",
COUNT(CASE WHEN hour = 5 THEN 1 END) AS "5",
COUNT(CASE WHEN hour = 6 THEN 1 END) AS "6",
COUNT(CASE WHEN hour = 7 THEN 1 END) AS "7",
COUNT(CASE WHEN hour = 8 THEN 1 END) AS "8",
COUNT(CASE WHEN hour = 9 THEN 1 END) AS "9",
COUNT(CASE WHEN hour = 10 THEN 1 END) AS "10",
COUNT(CASE WHEN hour = 11 THEN 1 END) AS "11",
COUNT(CASE WHEN hour = 12 THEN 1 END) AS "12",
COUNT(CASE WHEN hour = 13 THEN 1 END) AS "13",
COUNT(CASE WHEN hour = 14 THEN 1 END) AS "14",
COUNT(CASE WHEN hour = 15 THEN 1 END) AS "15",
COUNT(CASE WHEN hour = 16 THEN 1 END) AS "16",
COUNT(CASE WHEN hour = 17 THEN 1 END) AS "17",
COUNT(CASE WHEN hour = 18 THEN 1 END) AS "18",
COUNT(CASE WHEN hour = 19 THEN 1 END) AS "19",
COUNT(CASE WHEN hour = 20 THEN 1 END) AS "20",
COUNT(CASE WHEN hour = 21 THEN 1 END) AS "21",
COUNT(CASE WHEN hour = 22 THEN 1 END) AS "22",
COUNT(CASE WHEN hour = 23 THEN 1 END) AS "23"
FROM OrderDayHour
GROUP BY day_of_week_int
ORDER BY day_of_week_int이렇게 나온 결과를
pd.read_sql_query(쿼리, 경로) 함수를 사용하여 dataframe을 생성한다.
한국인은 억울해서 한글 쓰겠나..
한글을 사용하면 parsing error부터 시작해서 encoding error 심지어 length issue까지도 생긴다. 또한 시각화 시 폰트가 깨지는 경우가 다반사....... 그냥 utf-8, 영어 조합으로 맘 놓고 살자...
