91번. Not Boring Movie
- 나의 정답
# report the movies with an odd-numbered ID and a description that is not "boring".
select *
from cinema
where id%2 != 0 and description != 'boring' -- odd-numbered, not "boring"
order by rating desc- 다른 정답
SELECT *
FROM Cinema
WHERE
MOD( id, 2) = 1
AND description <> 'boring' ORDER BY rating DESCMOD()함수 - 나머지 구하기
SELECT MOD(18, 4)= 2
18을 4로 나누고 나머지를 반환
92번. Average Selling Price
# find the average selling price for each product
select
p.product_id,
ifnull(round((sum(p.price * u.units) / sum(units)),2),0) average_price
from Prices p left join UnitsSold u
on p.product_id = u.product_id
and u.purchase_date between p.start_date and p.end_date
group by p.product_id
# 중요 포인트 1:
-- join의 기준 열 속성 파악이 핵심, 기준열이 PK가 아니면 JOIN의 결과가 예상과 다름.
-- 이 문제에서는 기준 테이블에 PK가 3개나 되어서 JOIN 시 예상보다 많은 행이 출력되었다.
# 중요 포인트 2:
-- grouping 후 계산 시 주의사항
-- grouping 후 계산할 때 집계함수를 사용할 때와 단일연산을 사용할 때의 결과가 다르다.
# TIP:
-- 현실 과제는 정답 예시가 없다.
-- 간단한 연산으로 검증하는 방법이 있음. (결과 확인용)- ifnull(함수,null대체값)
ifnull(round((sum(p.price * u.units) / sum(units)),2),0)
round((sum(p.price * u.units) / sum(units)) 의 값이 null 이면
2를 반환하라.
JOIN 기준열의 속성값을 항상 확인해라.
보통은 PK지만, PK가 아니라면, 혹은 PK가 여러개의 칼럼이라면 예상 JOIN결과와 실제 결과가 다를 수 있다. 아니 거의 다르다.
JOIN AND 를 통한 필터링으로 테이블을 간단하게 만들어 유리한 고지에서 출발할 수 있다. 적극활용해~
93번. Project Employees 1
# average experience years of all the employees for each project
select
p.project_id,
round(avg(e.experience_years), 2) average_years
from project p join employee e
on p.employee_id = e.employee_id
group by p.project_idjoin - grouping - avg 로 간단하게 풀어버리기~
통계학 기초 1주차
통계학을 배우는 이유
통계학 배우는 이유는 무수히 많은 데이터의 특징을 요약하고(기술통계) 추론하는 과정을 통해(추론통계) data-driven 의사결정을 하기 위해서이다.
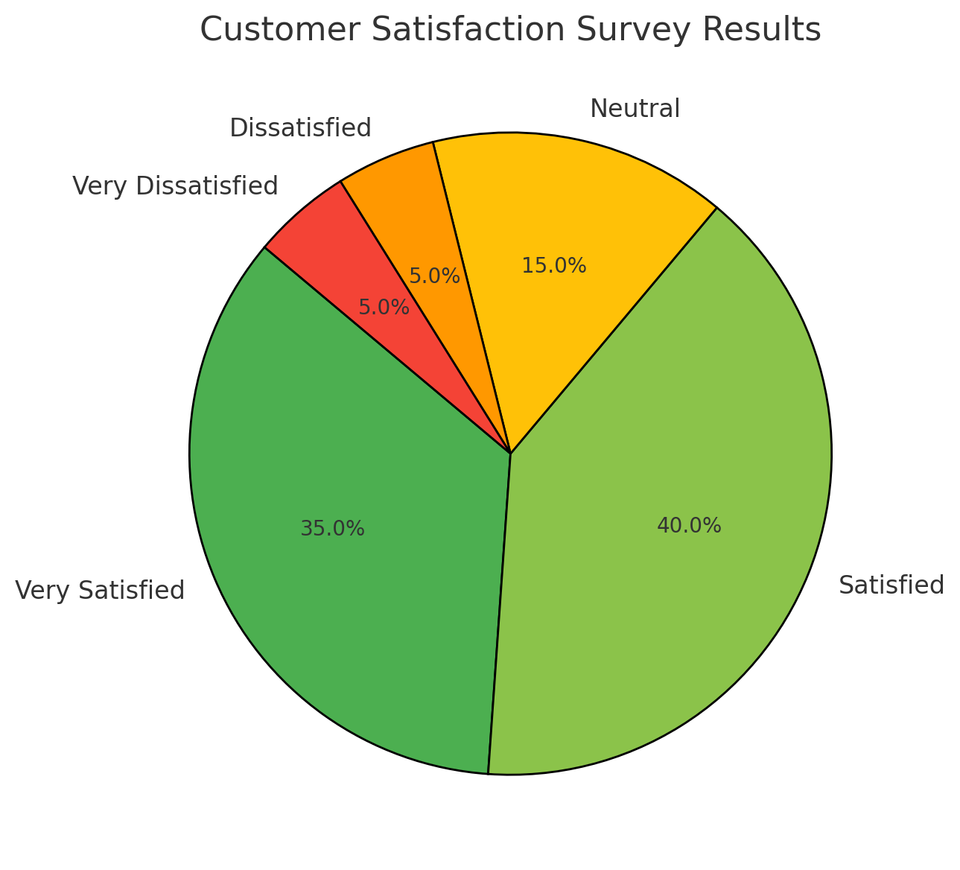
수천 수만개의 데이터를 파이그래프를 통해 간단하게 표현할 수 있다.
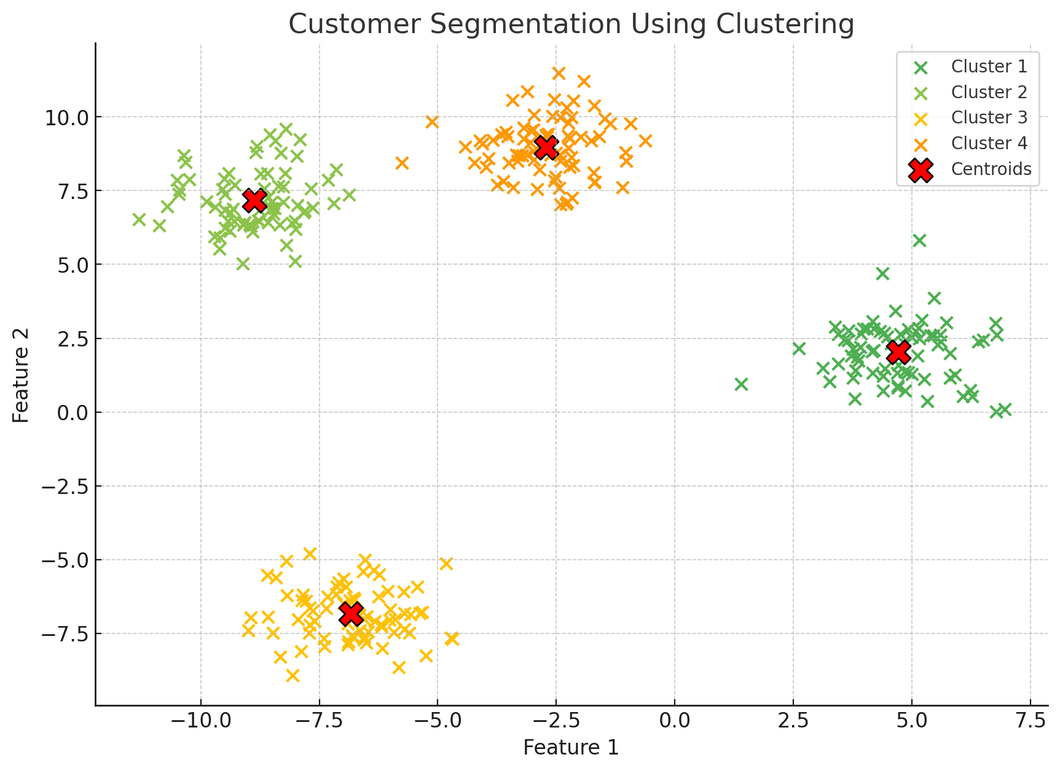
또한 수 많은 고객 데이터를 머신러닝 기법을 통해 직관적으로 보이게 만들 수도 있다.
기술통계 vs 추론통계
기술통계: 데이터를 요약해서 설명하는 통계 방법
"평균, 중앙값, 분산, 표준편차" 등을 사용하여 데이터를 설명한다.
1 평균, 중앙값: 대표적인 위치 추정 방법
2 분산, 표준편차: 평균으로부터의 흩어짐 정도를 나타내는 척도
- 분산(Variance):
편차 제곱의 합/데이터 수 - 표준편차(Standard Deviation):
분산 제곱근 값-> 원래 데이터 값과 동일한 단위로 표현
추론통계: 표본으로 모집단을 추정하는 통계 방법
"신뢰구간, 가설검정"을 사용한다.
-
신뢰구간: 보통 95%를 기준으로 하며 p-value를 통해 측정한다.
-
가설검정: 모집단에 대한 가설을 검정한다.
- H0(귀무가설)
- H1(대립가설)
- "귀무가설 기각 여부"를 결정한다.
