- EDA process
- Imports and Reading Data
- Data Understanding
- Data Preparation
- Feature Understanding
- Feature Relationship
- Ask a Question about the data
Step 0. Imports and Reading Data
보통 pandas, numpy, matplotlib, seaborn 을 import한다.
import pandas as pd
import numpy as np
import matplotlib.pylab as plt
import seaborn as sns
# matplotlib 과 seaborn의 종류 중 ggplot 을 선택!
plt.style.use('ggplot')
# 칼럼 200개 까지 보이도록 설정
pd.set_option('display.max_columns', 200)pandas: 데이터 처리 및 조작
numpy : 수치 연산 및 데이터 배열 처리
matplotlib: 기본 시각화
seaborn : 고급 시각화
Step 1. Data Understanding
데이터 프레임의 구조, head데이터와 tail데이터, datatype을 조회해본다.
-
df.shape
행과 열을 반환 -
df.head()
첫 번째 5개 row를 보여준다.
-
df.columns
칼럼들의 리스트를 보여준다. -
df.dtypes
모든 칼럼의 dtype을 보여준다. -
df.describe()
수치형 데이터에 대한 요약 통계 정보를 제공
범주형 데이터에 대한 정보는df.describe(include=[object])옵션으로 조회할 수 있다. -
df.nuniqe():
각 칼럼별 고유값의 수를 볼 수 있다.
tip:
shape,columns,dtypes 는 property(속성)이라서 소괄호를 붙이지 않고,
head(), describe()는 method(메서드)라서 소괄호를 붙여줘야 한다.
Step 2. Data Preparation
필요 없는 칼럼이나 복제된 데이터를 삭제하고 칼럼들의 이름을 보기 좋게 수정하며 파생 변수를 만들어 주는 등 데이터셋을 수정해본다.
subsetting: subset 생성과 재배정을 통한 칼럼 수정
import pandas as pd
data = {
'A': [1, 2, 3],
'B': [4, 5, 6],
'C': [7, 8, 9]
}
df = pd.DataFrame(data)
# 'A'와 'B' 열만 선택 (하위 집합)
subset_df = df[['A', 'B']]
print(subset_df)-
df.drop(['Opening date'], axis=1)
단일 칼럼 삭제 -
df.drop(columns = ['coaster_name','Location'])
복수 칼럼 삭제 -
pd.to_데이터타입(df['칼럼이름'])
해당하는 칼럼을 원하는 데이터 타입으로 변환해준다. -
df.rename(columns={원래이름:바꿀이름, 원래이름:바꿀이름,...}]
rename()메서드에 딕셔너리 형태로 인자를 넣어 칼럼 이름을 수정할 수 있다. -
df.isna().sum()
칼럼별 null 값의 총 합을 조회한다. -
df.loc[df.duplicated()]
duplicated rows를 조회한다.
df.loc = 특정 조건을 만족하는 행을 선택하는 기능 -
df.loc[df.duplicated(subset=['칼럼이름'])]
: 해당 칼럼에 중복 value를 가지는row들 중 마지막 하나의 row를 출력한다.
import pandas as pd
data = {
'Coaster_Name': ['Cyclone', 'Thunderbolt', 'Cyclone', 'Zeus', 'Thunderbolt'],
'Location': ['Park A', 'Park B', 'Park A', 'Park C', 'Park B']
}
df = pd.DataFrame(data)
# 중복된 Coaster_Name을 가진 행들 선택
duplicates = df.loc[df.duplicated(subset=['Coaster_Name'])]
print(duplicates)output:
| Coaster_Name | Location |
|---|---|
| Cyclone | Park A |
| Thunderbolt | Park B |
-
df.query('칼럼이름 == "칼럼value"')
: 중복값 체크하기
칼럼의 값이 칼럼value에 주어진 값과 동일한 모든 행을 출력한다. -
df = df.loc[~df.duplicated(subset=['칼럼1','칼럼2','칼럼3'])].reset_index(drop=True).copy()
: 칼럼1,2,3을 기준으로 중복된 값이 있는 행들 중 첫 번째 행을 남겨두고, 그 이후에 나타나는 중복된 행들은 모두 제거
Step 3. Feature Understanding
(Univariate analysis) 라고 부르기도 한다.
각 feature를 시각화를 통해 이해하는 과정이다.
히스토그램, KDE(Kernel Density Estimation), Boxplot 등
시각화 방법은 여러가지가 있는데 2가지만 살펴보자.
1. Pandas (plot(kind=플롯이름)):
Pandas 플롯은 x축을 기본적으로 최소값과 최대값을 고려하여 설정한다.
2. Seaborn (sns.플롯이름):
Seaborn 플롯은 플롯을 생성할 때 전체 범위를 매개변수를 고려하여 자동으로 설정한다.
# sns라이브러리
sns.histplot(df['Year_Introduced'])
plt.title("Year_Introduced")
plt.xlabel("Speed (mph)")
# pandas df.plot 매서드
ax = df['Year_Introduced'].plot(kind='hist',bins=50,title='Year_Introduced')
ax.set_xlabel('Speed (mph)')df.value_count()
: Pandas라이브러리 함수, 각 칼럼(Series)의 고유 값 빈도를 계산한다.
데이터 분포, 최빈값 확인에 유용하다.
.describe()랑 같이 쓰이면 좋아보인다.
Step 4. Feature Relationship
-
seaborn 공식문서에서 거의 모든 시각화 메서드의 가장 정확한 정보를 살펴볼 수 있다.
-
sns.scatterplot(data = , x = ,y = ,hue = )
: 산점도를 통해 두 변수의 선형성, 상관관계, 이상치, 분산 파악
scatterplot 공식문서 -
sns.pairplot(pd.DataFrame)
: 모든 수치형 변수 쌍에 대한 산점도와 히스토그램 그리기
hue를 통해 그룹별로 변수 간의 관계를 비교할 수 있다.
pairplot 공식문서
-
Pandas
df.corr()메서드
: 변수간 상관관계를 계산한다. -
sns.heatmap(pd.DataFrame, annot=True)
: 상관관계를 시각화한다.
pandas, seaborn 둘 중 무엇을 사용해도 상관없다.
heatmap 공식문서
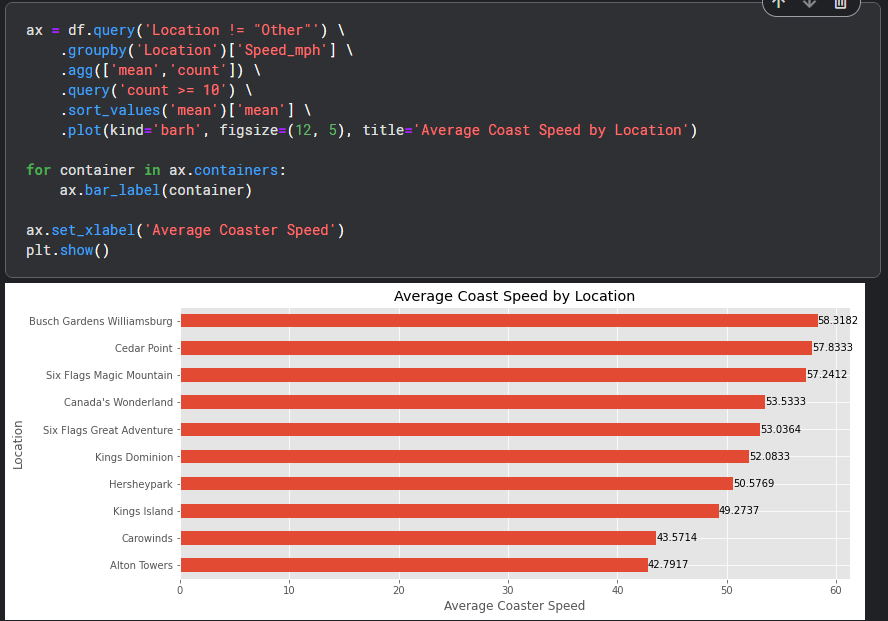
Step 5. Ask a Question about the data
과제 해결을 위해 필요한 질문을 만들고, 해당 질문의 답변을 통계적 지식과 시각화를 통해 구하는 과정이다.
example
"What are the locations with the fastest roller coasters (minimum of 10)?"