S.Korea : Vanishing at Unprecedented Speed
"저출산이 뜨거운 감자가 된 지도 오래된 한국, 이대로 저출산이 유지된다면 미래 한국의 모습은 어떨지 궁금하여 UN데이터를 통해 예측해보자."
- 절차:
데이터 확보->python분석->tableau시각화 - 환경: Google Colab
- 기간: 3일
Project: S.Korea : Vanishing at Unprecedented Speed
- process
- 주제 선정
- 데이터 전처리
- 분석 시각화
- 데이터 출처: https://population.un.org/wpp/Download/Standard/CSV/
-Presentation: https://www.canva.com/design/DAGRQgGsmRY/74Rn7KPzi5ro2ntp8C3ECA/edit
데이터를 국가별로 소분하여 각각의 테이블을 만들어 드라이브에 올려두었다.
- 한국
- 일본
- 세계
- 인도
주제 선정
24년도 상반기 합계 출산율 0.7명.
전례없는 속도로 고령화 및 인구 감소가 진행중인 대한민국의 상황을 객관적으로 모니터링하기 위해 필요한 데이터를 수집, 처리하여 대시보드를 만들어 보았다.
데이터 전처리
공유가 쉽도록 drive에 데이터를 올려 colab환경에 마운트하여 전처리를 진행하였다.
import pandas as pd
pd.set_option('display.float_format', '{:.0f}'.format)
# 모든 열을 출력할 수 있도록 옵션 설정
pd.set_option('display.max_columns', None) # 모든 열을 출력하도록 설정
pd.set_option('display.max_colwidth', None) # 열 이름의 최대 너비 제한을 해제
pd.set_option('display.max_seq_items', None) # 출력할 최대 항목 수 제한을 해제
# 드라이브 마운트
from google.colab import drive
drive.mount('/content/drive')
India = pd.read_csv('/content/drive/MyDrive/스파르타_실전프로젝트B03/새롭게 시작한 프로젝트/작업/1950-2100 - India.csv', encoding='utf-8', thousands=' ') #object
Japan = pd.read_csv('/content/drive/MyDrive/스파르타_실전프로젝트B03/새롭게 시작한 프로젝트/작업/1950-2100 - Japan.csv', encoding='utf-8', thousands=' ') #int
Korea = pd.read_csv('/content/drive/MyDrive/스파르타_실전프로젝트B03/새롭게 시작한 프로젝트/작업/1950-2100 - Korea.csv', encoding='utf-8', thousands=' ') #int
World = pd.read_csv('/content/drive/MyDrive/스파르타_실전프로젝트B03/새롭게 시작한 프로젝트/작업/1950-2100 - World.csv', encoding='utf-8', thousands=' ') #object 타입
# 모든 테이블이 동일한 형식을 가지기 때문에 concat을 사용하여 위-아래로 붙여준다.
population = pd.concat([World, Korea, Japan, India])
# 각 열을 숫자로 변환 (공백 제거 및 숫자형 변환)
population.loc[:, '0_15':'100+'] = population.loc[:, '0_15':'100+'].apply(pd.to_numeric, errors='coerce')
population['0_15'] = population.loc[:, '0':'14'].sum(axis=1)
population['15_39'] = population.loc[:, '15':'39'].sum(axis=1)
population['40_64'] = population.loc[:, '40':'64'].sum(axis=1)
population['65_'] = population.loc[:, '65':'100+'].sum(axis=1)
population['total'] = population.loc[:,'0':'100+'].sum(axis=1)
# 사용할 칼럼들만 뽑아내서 population_select 변수에 재배정
population_select = population[['Year', 'Country', '0_15', '15_39', '40_64', '65_','total']]
# 단위 "천 명" -> "명" 으로 맞추기
population_select.loc[:, '0_15':'total'] = population_select.loc[:, '0_15':'total'] * 1000
# GDP 데이터 넣기 | melting -> merging
GDP = pd.read_csv('/content/drive/MyDrive/스파르타_실전프로젝트B03/새롭게 시작한 프로젝트/작업/GDP.csv')
GDP = GDP.drop(index=[0,1]).rename(columns={'Country Name':'Year', 'Korea, Rep.':'Korea'})
# melt
melted_GDP = GDP.melt(id_vars='Year', var_name='country', value_name='GDP')
melted_GDP = melted_GDP.rename(columns={'country':'Country'})
melted_GDP['Year'] = melted_GDP['Year'].astype(int)
# merge
population_gdp = population_select.merge(melted_GDP, how='left', on=['Year', 'Country'])
# 출산율 데이터 넣기 | melting -> merging
born = pd.read_csv('/content/drive/MyDrive/스파르타_실전프로젝트B03/새롭게 시작한 프로젝트/작업/born.csv')
born = born.rename(columns={'Country Name':'Year', 'Korea, Rep.':'Korea'})
# melt
birthrate = born.melt(id_vars = 'Year', var_name='Country', value_name='Birth rate' )
population_gdp.merge(birthrate, how = 'left', on=['Year', 'Country'])
# merge
population_gdp_birthrate = population_gdp.merge(birthrate, how = 'left', on=['Year', 'Country'])
# 파생변수(면적당 인구)
def PPA_calculation(df):
# 각 나라의 면적 (단위: 제곱킬로미터)
area_dict = {
'India': 3287000,
'Korea': 100210,
'Japan': 377973,
'World': 510072000
}
# 각 행마다 PPA를 계산 (인구 밀도)
df['population per area'] = df.apply(lambda row: row['total'] / area_dict.get(row['Country'], 1), axis=1)
return df
PPA_calculation(df)
# 저장
PPA_calculation(df).to_csv('/content/drive/MyDrive/스파르타_실전프로젝트B03/새롭게 시작한 프로젝트/작업/project.csv')
Tableau 시각화
절차
1. 테이블 업로드, 타입 점검
2. 대시보드 디자인 by Figma, 노트와 펜
3. 워크시트 생성 (디자인 과정에서 필요하다고 정리한 chart, BAN 등)
4. 대시보드 컨테이너 설계 by draw.io
5. 대시보드 조립
1. 테이블 업로드, 타입 점검
project_real.csv: 시계열 예측에 필요한 데이터
한국지도.csv: 위치, 지역별 고령화, 출산율 정보 포함 데이터
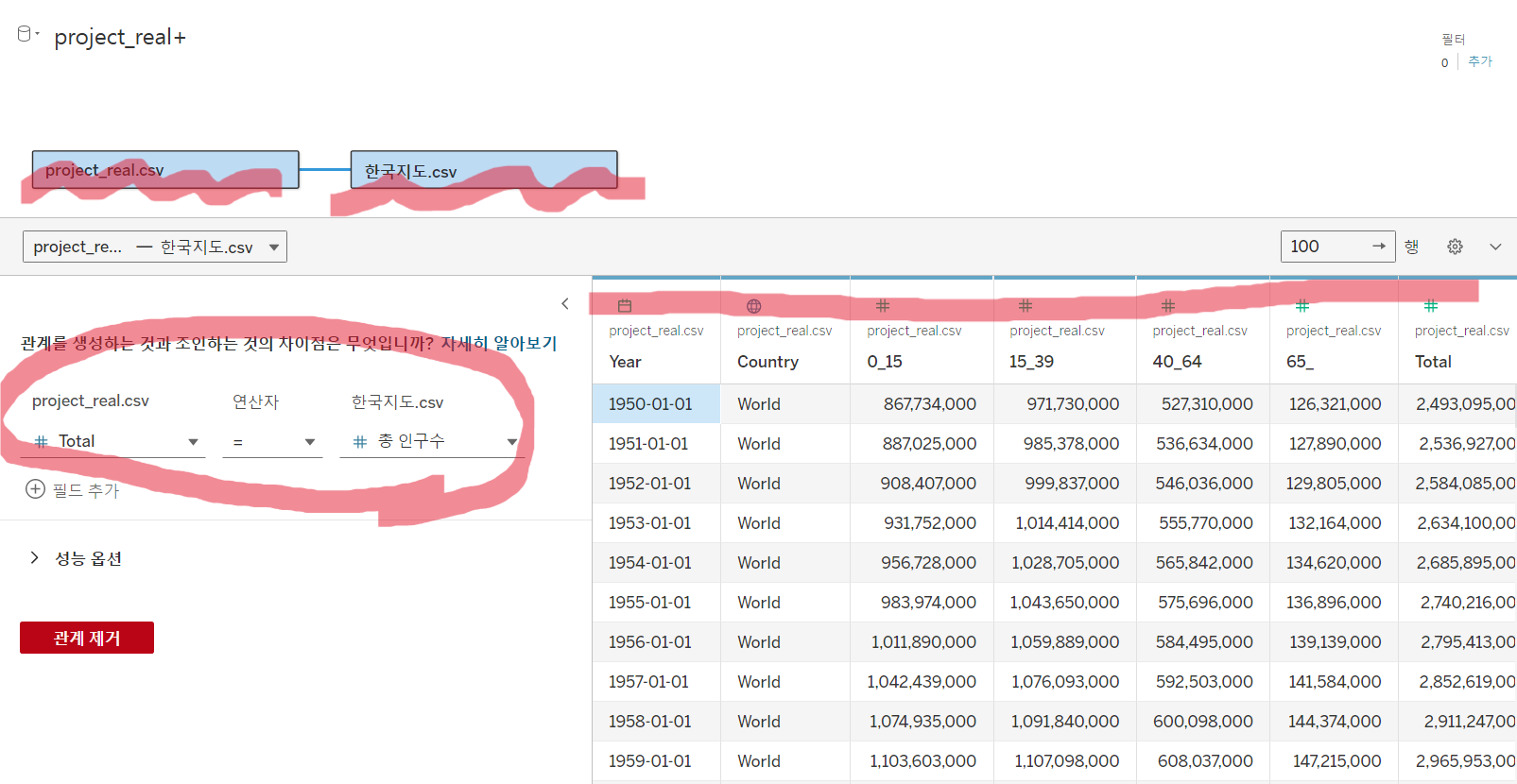
인구 칼럼 total + 총 인구수 로 연결해줬다.
빨간 표시가 되어있는 데이터 타입 부분을 검토하며 날짜, 위치 등의 맞는 타입을 배정해준다.
2. 대시보드 디자인 by Figma, 노트와 펜
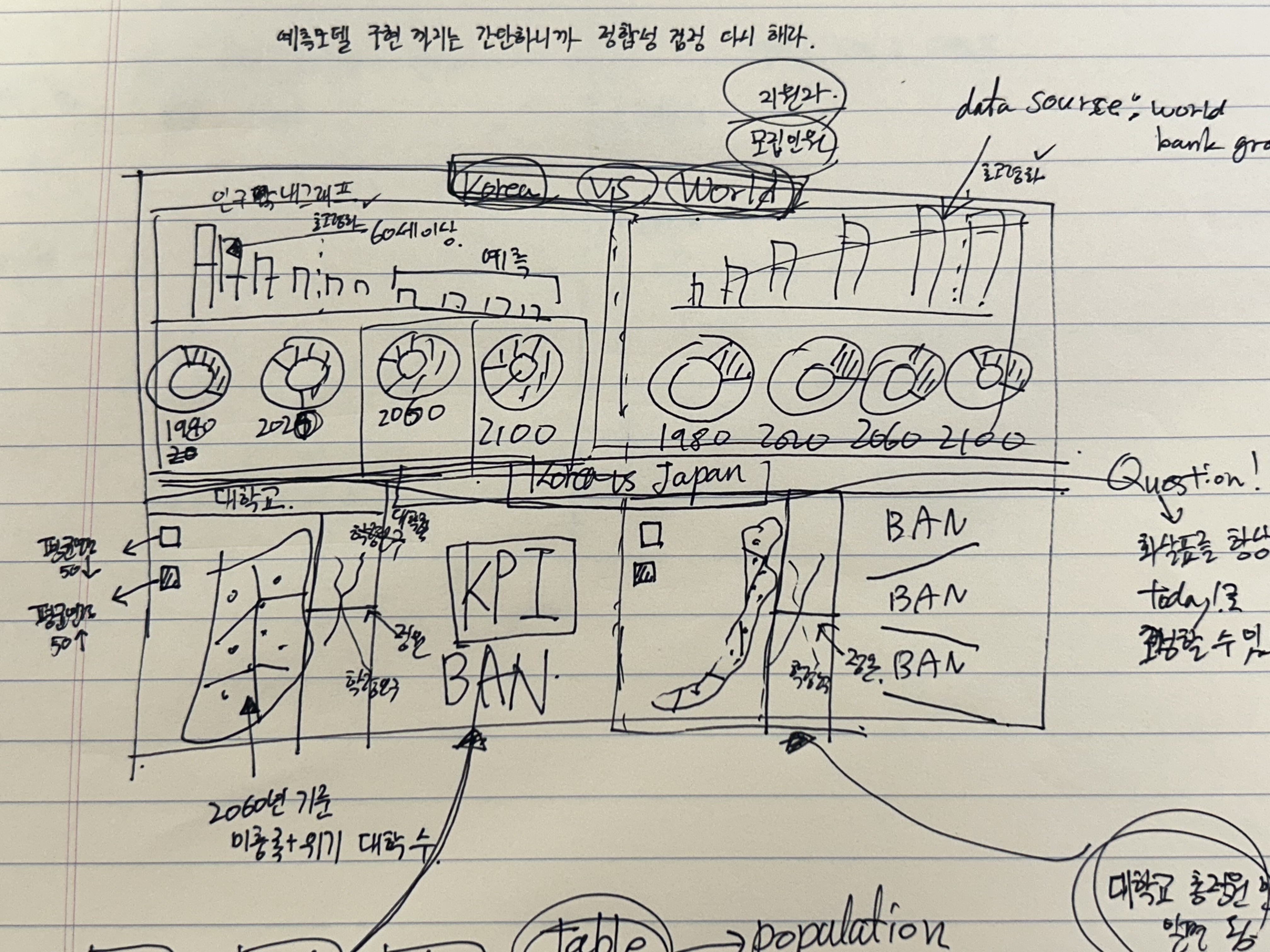
figma로 그림을 그려가며 디자인 하거나, 노트와 팬을 사용해 원하는 모습, kpi, 그래프 위치 등을 최대한 설득력 있게 디자인한다.
-
야망 넘치게 그려낸 첫 디자인. 조금씩 실현 가능한 모습으로 단순화되는게 킬포다.
-
두 번째 디자인
-
세 번째 디자인 가장 직관적이고 설명 가능한 그래프라고 자부한다. 쫌 없어보이지만 그래도 완성하면 멋있음.
3. 워크시트 생성 (디자인 과정에서 필요하다고 정리한 chart, BAN 등)
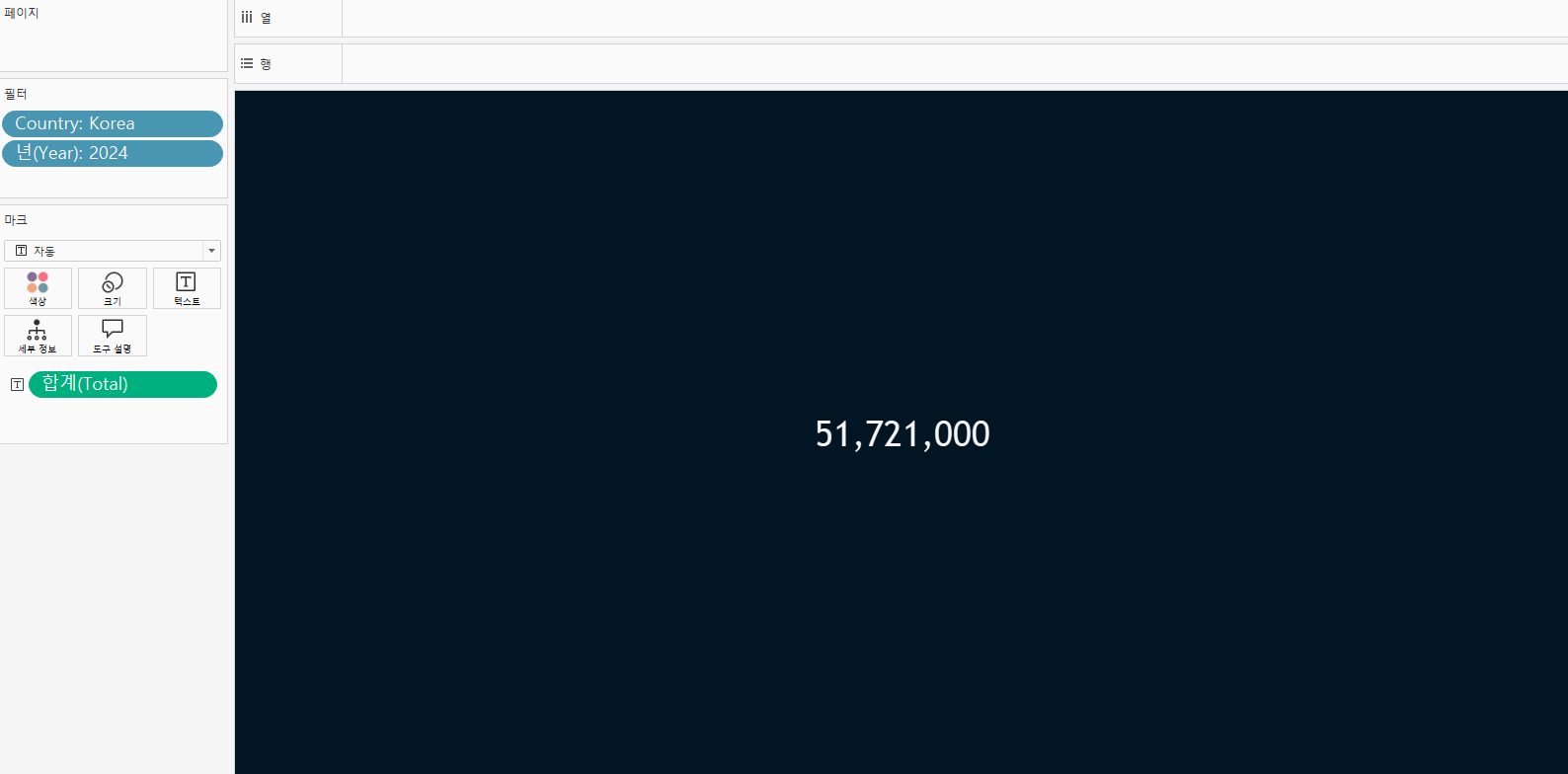
- KPI를 BAN(big ass number)로 만들어 각각의 워크시트에 담아냈다.
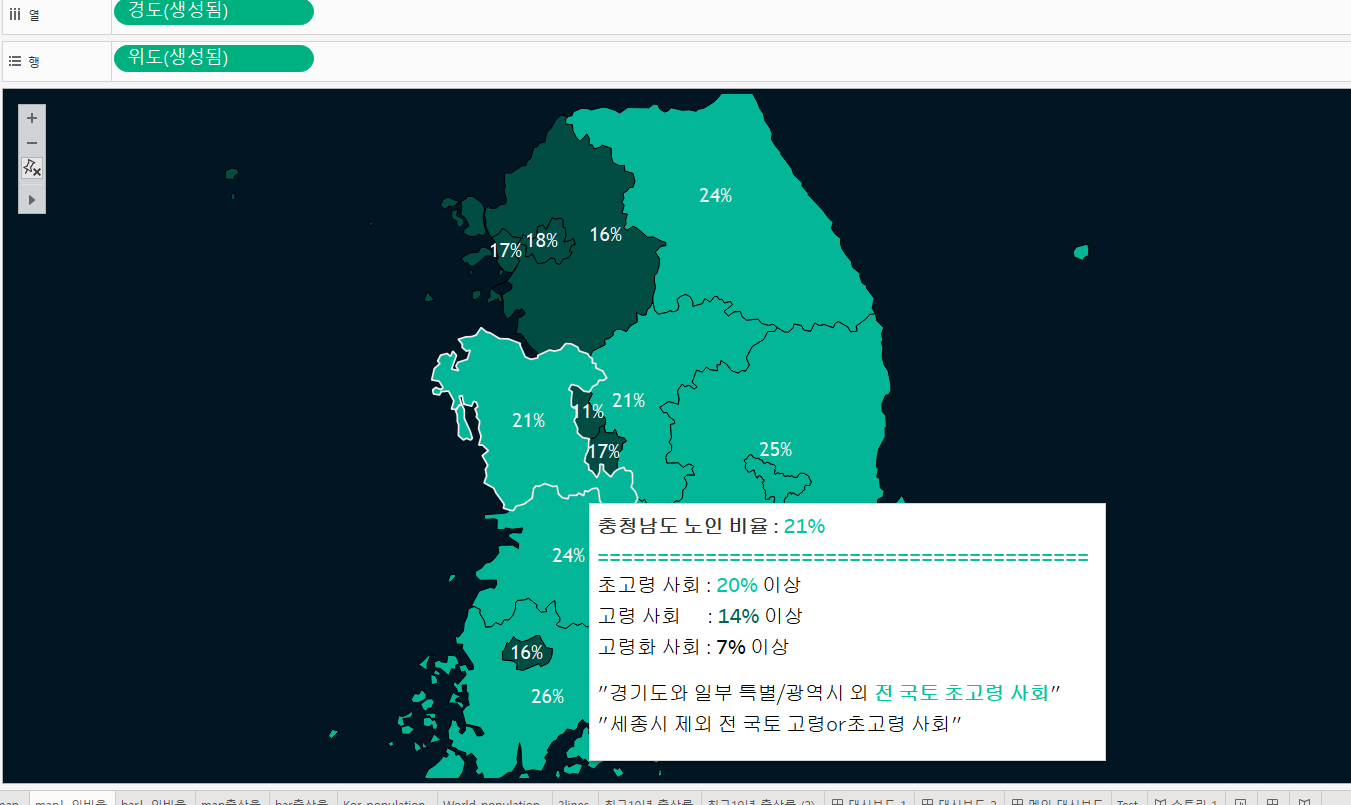
- 대한민국 위치 정보를 활용하여 지역별 고령화, 출산율을 시각화했다.
이 때도구 설명란을 적극 활용하여 마우스를 지도에 올려두었을 때 추가정보다 팝업될 수 있도록 했다.
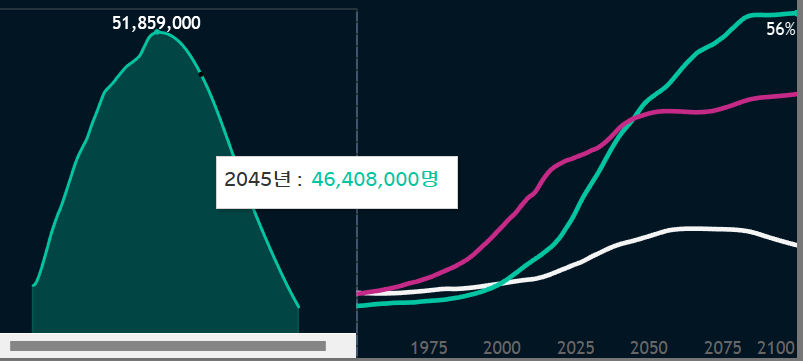
- 세계 vs 한국의 인구 시계열 데이터 비교, 일본과의 비교 등을 차트로 표현
4. 대시보드 컨테이너 설계 by draw.io
차트를 계획 없이 조립하면 대참사가 벌어지기 때문에 draw.io를 사용하여 미리 컨테이너 구조를 설계했다.
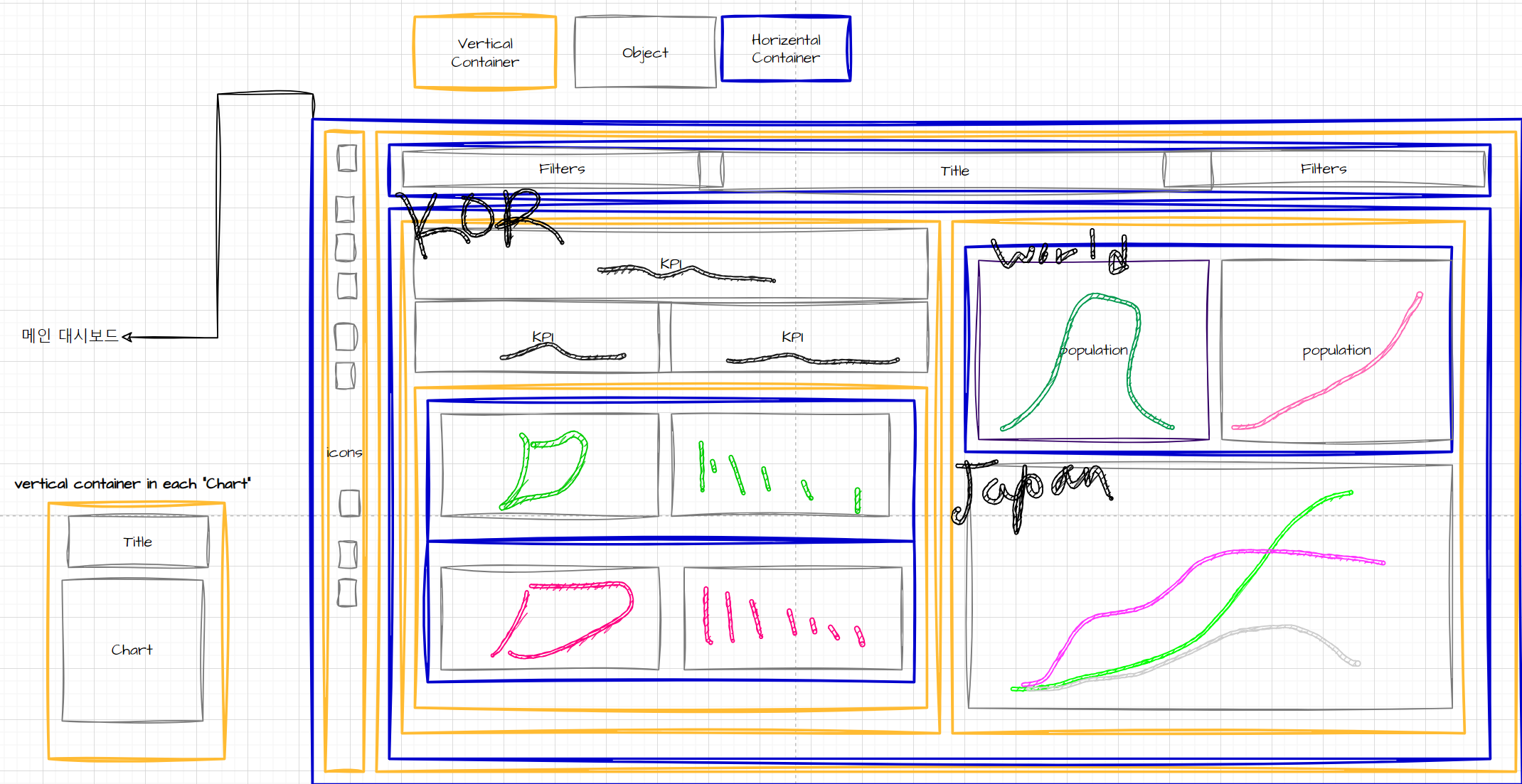
5. 대시보드 조립
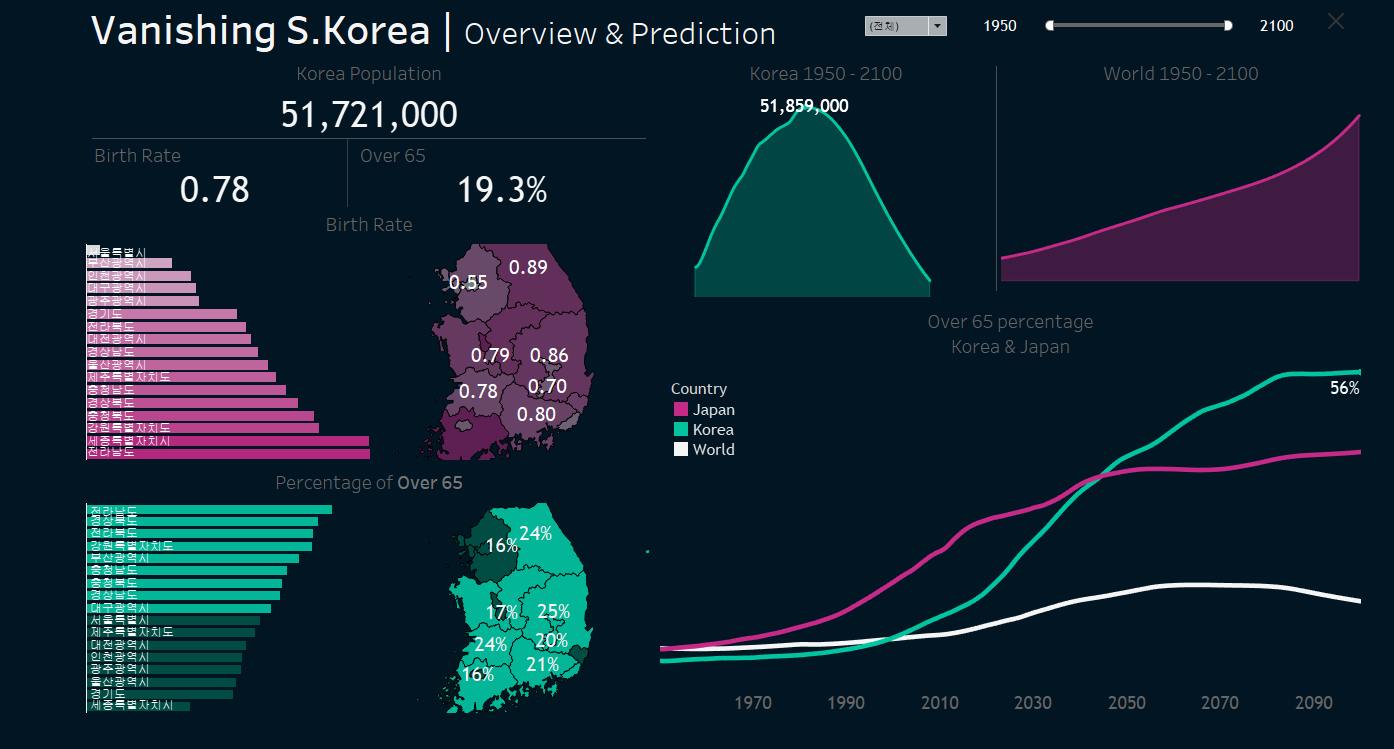
완성된 대시보드. 추가로 좌측 공간에 개인 linkedin 링크, 데이터 출처 사이트 링크 등으로 이동할 수 있는 아이콘을 추가하고 info 아이콘을 통해 기본적인 가설과 결과를 볼 수 있도록 발전시켜 포트폴이오에 활용할 계획이다.
소회
시각화를 위해 유투브로 인도 고수 형님의 시각화 프로젝트를 따라해 본 경험이 큰 도움이 되었다.
사이드 프로젝트로 하고 싶은거 다 해봐야 실력이 가장 빠르게 느는 것 같다.
내가 하고 싶은 것들
1. 업비트 API 활용 암호화폐 자동매매 시스템 만들기
2. Bigquery 활용 Google Trend 데이터 실시간 크롤링 및 실시간 검색어 대시보드 만들기
