✅윈도우 함수
윈도우 함수의 역할
기본적으로, GROUP BY는 데이터를 그룹화하고 각 그룹에 대해 하나의 집계 결과를 반환한다.
이 과정에서 원본 데이터의 개별 행들은 사라지고, 그룹화된 결과만 남게 된다.
그룹화된 집계 결과를 얻으면서 동시에 원본 데이터의 각 행을 그대로 유지하고 싶을 때, 이때 사용하는 것이 윈도우 함수이다.
윈도우 함수 VS GROUP BY
-
GROUP BY: 데이터를 그룹화하고, 각 그룹에 대해 하나의 집계 결과를 반환합니다. 이 경우 원본 데이터의 개별 행은 사라집니다.
예를 들어, 부서별 평균 급여를 구할 때:
SELECT department_id, AVG(salary) FROM employees GROUP BY department_id; -
윈도우 함수: 원본 데이터의 각 행에 대해 추가적인 집계 정보를 제공하지만, 각 행 자체는 그대로 유지합니다.
예를 들어, 각 직원의 급여와 함께 부서별 평균 급여를 표시할 때:
SELECT employee_id, department_id, salary, AVG(salary) OVER (PARTITION BY department_id) AS dept_avg_salary FROM employees;
윈도우 함수의 구성 요소
- 윈도우 함수: 예를 들어
SUM(),AVG(),ROW_NUMBER()등이 있습니다. - OVER() 절: 윈도우 함수를 어떻게 적용할지 결정하는 부분입니다.
- PARTITION BY: 데이터를 그룹화할 열을 지정합니다.
GROUP BY와 비슷한 역할을 하지만, 원본 데이터를 유지합니다. - ORDER BY: 결과를 정렬할 열을 지정합니다.
- ROWS/RANGE BETWEEN: 윈도우 내에서 계산할 행의 범위를 지정합니다.
- PARTITION BY: 데이터를 그룹화할 열을 지정합니다.
윈도우 함수의 예시
-
부서별 평균 급여:
각 직원의 급여와 함께 그 직원이 속한 부서의 평균 급여를 나타내는 예시입니다.
SELECT employee_id, department_id, salary, AVG(salary) OVER (PARTITION BY department_id) AS dept_avg_salary FROM employees;이 쿼리는 각 직원의 행을 유지하면서 그 직원이 속한 부서의 평균 급여를 추가 정보로 제공합니다.
-
순위 매기기:
부서 내에서 급여 순위(1위, 2위, ...)를 매기고 싶다면
ROW_NUMBER()를 사용할 수 있습니다.SELECT employee_id, department_id, salary, ROW_NUMBER() OVER (PARTITION BY department_id ORDER BY salary DESC) AS rank FROM employees;이 쿼리는 각 부서별로 급여가 높은 순서대로 직원에게 순위를 부여합니다.
보완된 설명
- 윈도우 함수는 원본 데이터의 구조를 유지하면서도, 각 행에 대해 추가적인 집계나 분석 정보를 제공할 수 있게 합니다.
- GROUP BY와 달리 윈도우 함수는 데이터를 축약하지 않으며, 모든 행을 그대로 유지합니다. 단지 각 행에 추가적인 계산 결과를 더해줄 뿐입니다.
- 이를 통해 각 행에 대해 개별적으로 분석하면서도, 전체적으로 그룹화된 정보를 동시에 얻을 수 있습니다.
결론
윈도우 함수는 SQL에서 데이터를 다룰 때 강력한 도구로, GROUP BY로는 얻을 수 없는 세밀한 분석과 원본 데이터 유지가 가능하게 합니다.
원본 데이터와 추가 집계 데이터를 함께 보려는 경우 윈도우 함수를 사용하는 것이 가장 적합합니다.
✅rows between
범위 지정 키워드
- UNBOUNDED PRECEDING:
- n PRECEDING:
- CURRENT ROW:
- n FOLLOWING:
- UNBOUNDED FOLLOWING:
)
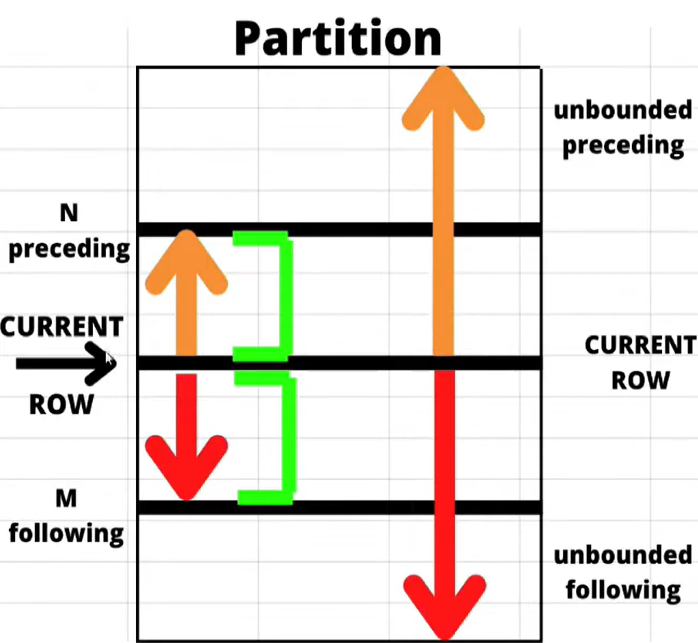
ROWS BETWEEN은 윈도우 함수가 계산을 수행할 때 참조할 행의 범위를 지정하는 데 사용된다.
구문
<윈도우 함수> OVER (
[PARTITION BY column1, column2, ...]
ORDER BY column
ROWS BETWEEN <범위1> AND <범위2>
)- PARTITION BY: 데이터의 파티션을 지정합니다. 파티션 내에서 각 그룹별로 윈도우 함수를 계산할 수 있습니다.
- ORDER BY: 데이터를 특정 열 기준으로 정렬하여 윈도우 함수의 계산 순서를 정의합니다.
- ROWS BETWEEN <범위1> AND <범위2>: 현재 행을 기준으로 계산할 범위를 지정합니다.
예시
1. 기본 사용 예
SUM(Sales) OVER (ORDER BY Date ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING)- 1 PRECEDING: 현재 행의 바로 앞 행을 포함.
- 1 FOLLOWING: 현재 행의 바로 다음 행을 포함.
- 따라서, 현재 행과 그 앞, 뒤의 합계가 계산됩니다.
2. 최근 3일의 합계 계산
SUM(Sales) OVER (ORDER BY Date ROWS BETWEEN 2 PRECEDING AND CURRENT ROW)- 2 PRECEDING: 현재 행의 앞 2행을 포함.
- CURRENT ROW: 현재 행을 포함.
- 따라서, 현재 행과 그 앞 2행까지의 합계를 계산합니다.
3. 모든 이전 행의 평균 계산
AVG(Sales) OVER (ORDER BY Date ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW)- UNBOUNDED PRECEDING: 시작 지점을 첫 번째 행으로 설정하여 모든 이전 행을 포함.
- CURRENT ROW: 현재 행을 포함.
- 따라서, 첫 행부터 현재 행까지의 평균을 계산합니다.
ROWS BETWEEN과 RANGE BETWEEN의 차이
- ROWS BETWEEN: 실제 행의 물리적 위치에 따라 범위를 지정합니다. 순서대로 각 행을 따로따로 계산합니다.
- RANGE BETWEEN: 데이터 값의 범위를 기준으로 계산합니다. 동일한 값이 있을 경우 그 값의 전체 행이 포함될 수 있습니다.
예시 비교:
- ROWS: 특정 행을 정확히 지정 (1행, 2행 등).
- RANGE: 값의 범위를 기준으로 지정 (값이 동일하면 여러 행 포함).
주의점
- MySQL에서는
ROWS BETWEEN을 사용하려면 MySQL 8.0 이상 버전이 필요합니다. ORDER BY절은 윈도우 내에서 데이터를 어떤 순서로 정렬할지 결정하며, 이 순서가ROWS BETWEEN범위 계산에 직접적인 영향을 미칩니다.- 범위 설정 시, 지정된 범위 내에 유효한 데이터가 없을 경우 결과가 NULL이 될 수 있습니다.
