
SQL
🟦 SQL 쿼리 동작 순서
예시 문제
| 단계 | 설명 |
|---|---|
| 1.FROM | USED_GOODS_BOARD 테이블과 USED_GOODS_USER 테이블을 INNER JOIN 하여 결합 |
| 2.WHERE | B.STATUS = 'DONE' 조건을 만족하는 행 필터링 |
| 3.GROUP BY | B.WRITER_ID를 기준으로 데이터 그룹화 |
| 4.HAVING | 가격 합계가 700,000원을 초과하는 그룹 필터링 |
| 5.SELECT | 각 작가 ID와 가격 합계를 선택 |
🟦 WHERE
"NULL": "IS NOT NULL" 혹은 "IS NULL"을 사용해야 한다.
/*
select count(user_id) USERS
from user_info
where age = null
*/ -> 오류 발생!
select count(user_id) USERS
from user_info
where age is nullSQL에서 'NULL' 값은 특별하다!
'NULL' 필터링: "IS NULL" or "IS NOT NULL"을 사용해야 한다.
비교연산자(예: =, !=, <, >)로는 비교가 불가능.
쿼리 WHERE age = NULL은 어떠한 결과도 반환하지 않는다.
🟦 JOIN
- 칼럼값이 동일하면 칼럼명이 달라도 JOIN이 가능하다!
CODEKATA
⭐ JOIN + AND 연산자로 FROM 절 필터링하기
- 서브쿼리의 결과가 다중 행을 반환한다면,
WHERE+=연산자를 사용한 필터링이 불가하다.
Subquery returns more than 1 row- WHERE 필터링은 단일 값 필터링이다.
- 이 경우,
JOIN+AND을 사용한 필터링이 가장 일반적이다.
-> JOIN 함수와 AND 연산자를 통해 JOIN 연산 과정에서 미리 필터링하는 과정을 살펴보자.
SELECT MAIN.FOOD_TYPE,
MAIN.REST_ID,
MAIN.REST_NAME,
SUB.FAVORITES
FROM REST_INFO MAIN INNER JOIN
(
SELECT FOOD_TYPE,
MAX(FAVORITES) FAVORITES
FROM REST_INFO
GROUP BY FOOD_TYPE
) SUB ON MAIN.FOOD_TYPE = SUB.FOOD_TYPE AND MAIN.FAVORITES = SUB.FAVORITES
ORDER BY 1 DESC-
문제 설명
음식 종류별로 즐겨찾기가 가장 많은 식당을 구하고, 해당 식당의 음식 종류, ID, 식당 이름, 즐겨찾기 수를 조회합니다. 결과는 음식 종류를 기준으로 내림차순(
DESC)으로 정렬합니다. -
REST_INFO 데이터 테이블
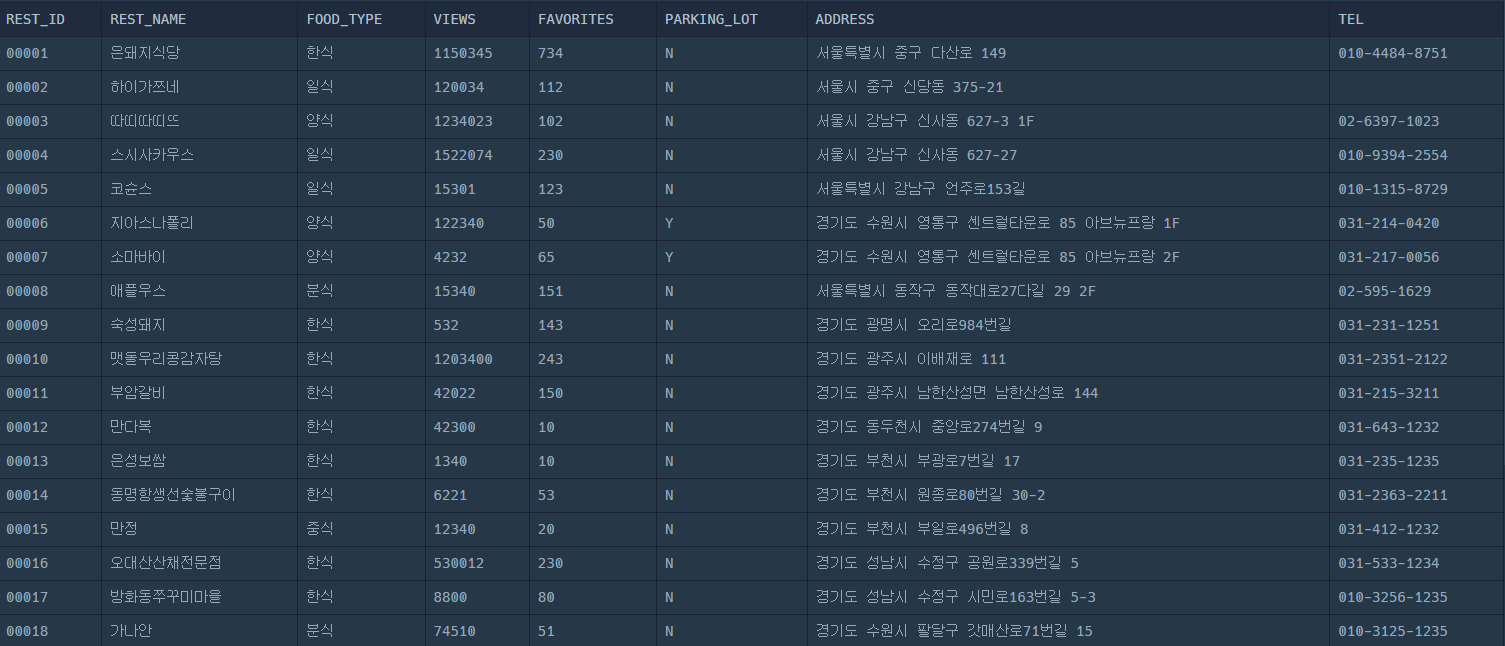
-
쿼리 작성
다음은 각 음식 종류별로 즐겨찾기 수가 가장 많은 식당을 찾기 위해 서브쿼리와 JOIN을 사용하는 쿼리입니다.
SELECT R.FOOD_TYPE, R.REST_ID, R.REST_NAME, R.FAVORITES FROM REST_INFO R JOIN ( SELECT FOOD_TYPE, MAX(FAVORITES) AS MAX_FAVORITES FROM REST_INFO GROUP BY FOOD_TYPE ) AS T ON R.FOOD_TYPE = T.FOOD_TYPE AND R.FAVORITES = T.MAX_FAVORITES ORDER BY R.FOOD_TYPE DESC; -
쿼리 설명
- 서브쿼리
T는 각FOOD_TYPE별로 최대 즐겨찾기 수(MAX_FAVORITES)를 계산합니다. - 메인 쿼리는
REST_INFO테이블을 서브쿼리T와 JOIN하여FOOD_TYPE과 즐겨찾기 수가 일치하는 행을 찾습니다. - 결과는 음식 종류를 기준으로 내림차순으로 정렬됩니다.
- 서브쿼리
-
쿼리 결과
위의 쿼리를 실행하면 다음과 같은 결과가 나옵니다.
FOOD_TYPE REST_ID REST_NAME FAVORITES 일식 00004 스시사카우스 230 양식 00003 따띠따띠뜨 102 한식 00001 은돼지식당 734 -
💡중요포인트💡
JOIN ON 뿐만 아니라 AND 를 통해 한 번 더 조건을 걸 수 있다.
SELF JOIN
https://school.programmers.co.kr/learn/courses/30/lessons/299305#qna
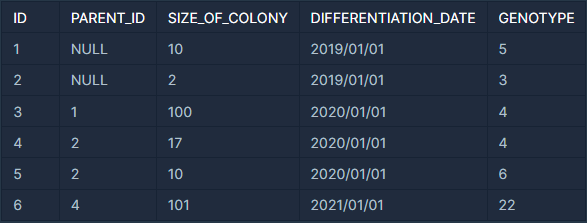
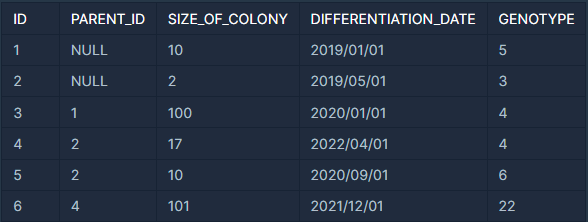
위 사진과 같은 테이블 ECOLI_DATA은 대장균 개체에 관련된 데이터이다.
- 문제:
대장균 개체의 ID(ID)와 자식의 수(CHILD_COUNT)를 출력하는 SQL 문을 작성해주세요. 자식이 없다면 자식의 수는 0으로 출력해주세요. 이때 결과는 개체의 ID 에 대해 오름차순 정렬해주세요.
이 때 ID와 PARENT_ID가 동일한 경우의 수를 구해야 한다.
SELF JOIN을 통해 풀어볼 수 있다.
-
FROM ECOLI_DATA A LEFT JOIN ECOLI_DATA B ON A.ID = B.PARENT_IDID와 PARENT_ID가 일치하는 경우를 JOIN하는 FROM절을 작성한다.
이 때 ID를 기준으로 GROUP BY를 진행해야 하므로 LEFT JOIN을 수행한다. -
SELECT A.ID ID, COUNT(B.ID) CHILD_COUNT FROM ECOLI_DATA A LEFT JOIN ECOLI_DATA B ON A.ID = B.PARENT_ID GROUP BY 1 ORDER BY 1ID에 해당되는 그룹의 수를 구해야 하기 때문에 COUNT(B.ID)를 적어준다.
이처럼 하나의 테이블에서 각 칼럼이 일치하는 경우를 반환하는 쿼리를 수행해야 하는 경우 SELF JOIN을 사용하면 쉽다.
[JOIN ON] vs [JOIN USING]
table join 방법에는 join - on 을 사용하는 방법과 join - using 을 사용하는 방법 총 2가지가 있다.
using을 사용하여 간결한 JOIN 쿼리를 만들어보자.
# on 사용
SELECT
customers.customer_id,
customers.customer_name,
orders.order_date
FROM
customers
JOIN orders
ON customers.customer_id = orders.customer_id
# using 사용
sql
코드 복사
SELECT
customer_id,
customer_name,
order_date
FROM
customers
JOIN orders USING (customer_id)🟦 GROUP BY
group by 핵심
1. 규칙
select 절에서 사용된 모든 열은 'group by'절에 포함되거나 집계 함수로 감싸져야 한다.
2. 이유
그룹화된 각 그룹 내에서 단일 값을 반환해야 하는데, 집계되지 않는 열은 그룹 내에서 여러개의 값을 가질 수 있기 때문에 모호성을 가진다.
3. 집계 함수(SUM, AVG, COUNT, MIN, MAX 등)
group by multiple columns
having + 집계함수(count(*)등)를 통해 group by 로 묶인 칼럼들의 상태를 확인할 수 있다.
ex) 같은 회원 아이디(USER_ID)로 다른 날 같은 상품(PRODUCT_ID)을 재구매한 사람들을 구하라
:GROUP BY USER_ID, PRODUCT_IDSELECT USER_ID, PRODUCT_ID FROM ONLINE_SALE GROUP BY 1,2 HAVING COUNT(*) >= 2 #이걸로 해당 조합의 수를 구할 수 있다!! ORDER BY USER_ID, PRODUCT_ID DESCselect 절 or having 절에서 집계함수 count(*)을 사용하여 해당 조합의 숫자를 알아낼 수 있다.
🟦 order by
다중 정렬 조건: ORDER BY 절에 ","를 사이에 두고 여러개의 정렬 조건이 나열되면 첫 번째 정렬 결과값 속 중복 행에 대하여 다음 정렬이 수행된다.
-- 모든 ID, NAME, DATETIME을 조회, 이름 순 정렬 /
-- 같은 이름일 경우 날짜 내림차순 정렬
SELECT ANIMAL_ID, NAME, DATETIME
FROM animal_ins
ORDER BY NAME, DATETIME DESC;
SQL에서 ORDER BY 절에 여러개의 정렬 조건을 사용하면 수행 플로우는 다음과 같다.
ORDER BY CONDITION1, CONDITION2
1. 첫 번째 정렬 조건(CONDITION1) (이름 순 정렬)
2. 두 번째 정렬 조건(CONDITION2) (같은 이름? -> 날짜 기준 내림차순 정렬)
🟦 집계함수는 SELECT 문에만 사용하는가?
집계함수: max() min()등의 함수
🅰️ 집계함수는 일반적으로 'SELECT' 문에서 가장 많이 사용된다. 하지만 'HAVING' 절에서 사용될 수 있다.
HAVING:
그룹화된 결과에 대한 조건을 지정할 때 사용되며, GROUP BY 절과 함께 특정 조건을 만족하는 그룹만을 필터링할 때 사용
주요 집계 함수:
MAX(): 주어진 열의 최대값을 반환
MIN(): 주어진 열의 최소값을 반환
SUM(): 숫자 열의 총합을 반환
AVG(): 숫자 열의 평균값을 반환
COUNT(): 특정 조건을 만족하는 행의 수를 계산
🟦 IF()
🅰️ IF() 함수는 주로 SELECT 문 내에서 칼럼이 들어갈 위치에 사용된다.
-
if 절의 구조
if(
조건,조건을 충족할 때,조건을 충족하지 않을 때)
예시
SELECT ANIMAL_TYPE,
IF(NAME IS NULL, 'No name', NAME) NAME,
SEX_UPON_INTAKE
FROM ANIMAL_INS
ORDER BY ANIMAL_ID
/*
[IF 함수를 대체할 수 있는 CASE함수]
CASE
WHEN NAME IS NULL THEN 'No name'
ELSE NAME
END AS NAME,
*/🟦 NULL 값 처리
💡IFNULL(expression, alt_value)
expression값이 NULL 일 때,alt_value를 반환한다.
SELECT IFNULL(NULL, 500)
# 500💡COALESCE()
- 주어진 값에서 NULL값을 제외한 가장 첫 번째 값 반환
SELECT COALESCE(NULL, '바보',1, 2, '과연 뭐가 나올까?');
# '바보' 출력🟦 DATE_FORMAT() 함수 & Specifier
날짜 데이터의 구조를 변경하고 싶을 때 사용하는 함수:
DATE_FORMAT()
registration_datetime 칼럼의 날짜 데이터 구성을 변경해보자.
SELECT
first_name,
last_name,
DATE_FORMAT(registration_datetime, '%a, %Y %M %e %H:%i:%s')
AS format_registration_datetime
FROM student_platform;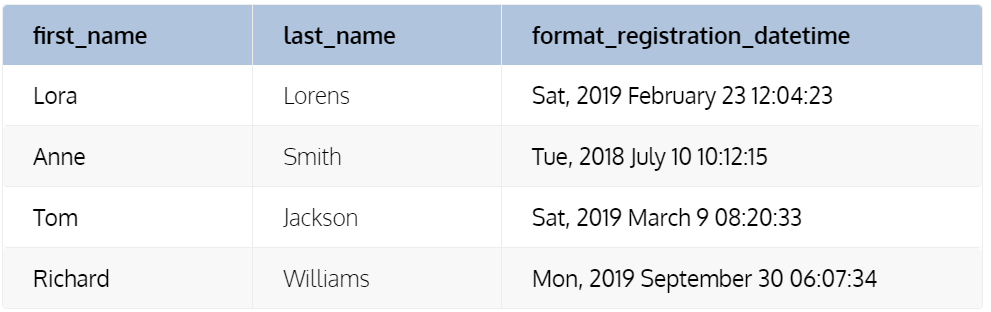
SELECT
first_name,
last_name,
DATE_FORMAT(registration_datetime, '%a, %Y %M %e %H:%i:%s')
AS format_registration_datetime
FROM student_platform;- 날짜 데이터 지정자(specifier)는 다음과 같다.
%a – 요일 이름 약어
%Y – Year, in 4-digits.
%M – 월 이름
%m - 월 (01-12)
%d - 일 (00-31)
%e – 일 (1–31)
%H – 시 (00-23)
%i – 분 (00-59)
%s – 초 (00-59).
ex) 2024-06-29 = "%Y-%m-%d"
'%Y-%m-%d' 가 가장 많이 쓰이는 듯.
🟦 WHERE 필터링
WHERE 절 복수의 조건
select *
from theglory
where 날짜 is not null
and 성별 != '남자'
and 직업 in ('아나운서', '승무원', '화가')
and 나이 between 30 and 40and연산자를 사용해서 where절 안에 있는 각 조건들을 묶어준다.
🅰️ 논리연산자(AND,OR), 혹은 IN연산자를 사용한다.
#sql_19_흉부외과 또는 일반외과 의사 목록 출력하기
SELECT DR_NAME,
DR_ID,
MCDP_CD,
DATE_FORMAT(HIRE_YMD, "%Y-%m-%d") HIRE_YMD
FROM DOCTOR
WHERE MCDP_CD = 'GS'OR MCDP_CD = 'CS'
ORDER BY HIRE_YMD DESC, DR_NAME ASC
# WHERE 절에 들어가는 복수의 조건들 표현
# 꼭 저렇게 자세히 써야해?
🤔 WHERE MCDP_CD = 'GS' OR 'CS' 라고 하면 왜 안되는가..?
🅰️ CS는 언제나 참이 되기 때문에 원하는 결과가 나오지 않는다.
따라서 여러 조건을 확인할 때는 논리연산자(AND,OR,NOT)를 각각 사용해주거나 'IN'연산자를 사용할 수 있다.
💡'IN'연산자
SELECT column_name(s)
FROM table_name
WHERE column_name IN (value1, value2, ...);CODEKATA
ex) 특정 이름들이 포함된 칼럼 조회
WHERE NAME IN ('Lucy','Ella','Pickle','Rogan','Sabrina','Mitty')SQL구문이 더 간결하고 가독성이 높아진다!
💡FIND_IN_SET('해당사항',칼럼) > 최소수량
-- '통풍시트', '열선시트', '가죽시트' 중 하나 이상의 옵션이 포함된 자동차 조회
SELECT CAR_TYPE,
COUNT(CAR_ID) CARS
FROM CAR_RENTAL_COMPANY_CAR
WHERE FIND_IN_SET('통풍시트',OPTIONS) > 0
OR FIND_IN_SET('열선시트',OPTIONS) > 0
OR FIND_IN_SET('가죽시트',OPTIONS) > 0
GROUP BY CAR_TYPE
ORDER BY CAR_TYPE🟦 MAX() 함수 주의사항
⭐MAX()가 적용된 데이터"만" 최대값인 경우를 주의하라.

-- 가장 비싼 가격의 항목의 정보를 전부 구하기
SELECT PRODUCT_ID,
PRODUCT_NAME,
PRODUCT_CD,
CATEGORY,
MAX(PRICE) PRICE
FROM FOOD_PRODUCT;
-- 이렇게 작성하면 MAX(PRICE)와는 상관없는 칼럼들이 나온다.
-- 올바른 작성 예시
SELECT *
FROM FOOD_PRODUCT
WHERE PRICE = (SELECT MAX(PRICE) FROM FOOD_PRODUCT);
1번 코드로 작성하면,
PRICE 칼럼에는 최대값이 출력되지만 나머지 칼럼에는 전부 최대값과는 관련없는 데이터가 출력된다.
| PRODUCT_ID | PRODUCT_NAME | PRODUCT_CD | CATEGORY | PRICE |
|---|---|---|---|---|
| 최대값아님 | 최대값아님 | 최대값아님 | 최대값아님 | 최대값 |
2번 코드처럼 WHERE 서브퀘리를 통해 해당 행 정보를 전부 출력해야 한다.
| PRODUCT_ID | PRODUCT_NAME | PRODUCT_CD | CATEGORY | PRICE |
|---|---|---|---|---|
| 최대값 | 최대값 | 최대값 | 최대값 | 최대값 |
🟦 ROUND()
평균 가격을 소수점 둘째 자리까지 반올림
SELECT ROUND(AVG(PRICE), 2) AS avg_price
FROM BOOK;🟦 CONCAT() Function
concat( 표현1, 표현2, 표현3, ... )
https://www.w3schools.com/sql/func_mysql_concat.asp
SELECT CONCAT("SQL ", "Tutorial ", "is ", "fun!") AS ConcatenatedString;
| ConcatenatedString |
|---|
| SQL Tutorial is fun! |
- note 표현 중 하나라도 NULL값이 있다면, 해당 함수는 NULL을 return한다.
🟦 CAST()
CAST(값 AS 형식)
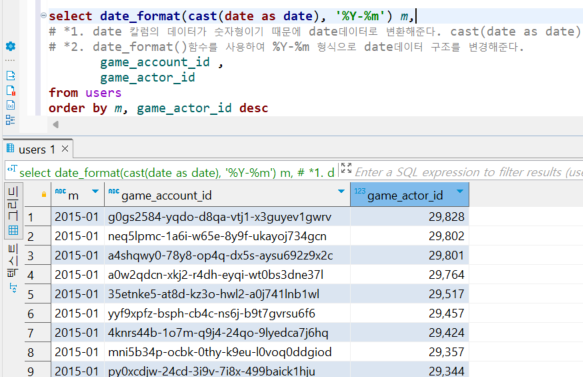
select date_format(cast(date as date), '%Y-%m') m- 위 select 절 workflow는 다음과 같다.
- date 칼럼의 데이터 형식이 str
- str 데이터를 time data로 변경해준다. cast(date as date)
- time data로 변경한 칼럼을 대상으로 date_format 함수를 사용하여 format을 원하는 것으로 바꿔준다!
날짜를 다루는 칼럼은 보통 "date"로 이름짓기 때문에 막연하게 time data겠거니~ 하고 검증을 뛰어넘는 경우가 있다.
그럴 경우 date_format 함수 같은 time data를 대상으로 하는 함수를 사용하지 못할 뿐 만 아니라 정렬 과정에서도 오류가 날 수 있기에 주의하자.
🟦 CASE WHEN ~조건~ THEN ~출력~ ELSE END
- case when 에서 조건을 각각 작성해줘야 한다.
❌:when 1 < level <= 10 then '1~10Lv 이하'
⭕: when 1 < level and level <= 10 then '1~10Lv 이하'
---------------------------case함수 구조------------------------
CASE
WHEN condition1 THEN result1
WHEN condition2 THEN result2
...
ELSE default_result
END
-----------------------------예시--------------------------------
-- CASE WHEN 구조 예시
SELECT game_actor_id,
level,
CASE
WHEN 1 < level AND level <= 10 THEN '1~10Lv 이하'
WHEN 10 < level AND level <= 20 THEN '10~20Lv 이하'
WHEN 20 < level AND level <= 30 THEN '20~30Lv 이하'
END AS level_range
FROM game_actors;
ELSE를 안적으면 안돼?
🅰️쿼리는 실행되지만 확인되지 않는 값들은 'NULL'을 반환한다.
CASE WHEN : 부등호의 효율적 사용
- 나의 코드
SELECT ID,
CASE WHEN SIZE_OF_COLONY <= 100 THEN 'LOW'
WHEN SIZE_OF_COLONY > 100 AND SIZE_OF_COLONY <=1000 THEN 'MEDIUM'
WHEN SIZE_OF_COLONY > 1000 THEN 'HIGH'
END SIZE
FROM ECOLI_DATA
ORDER BY 1- 더 간단한 쿼리
SELECT ID,
CASE
WHEN SIZE_OF_COLONY <= 100 THEN 'LOW'
WHEN SIZE_OF_COLONY <= 1000 THEN 'MEDIUM'
ELSE 'HIGH'
END AS SIZE
FROM ECOLI_DATA
ORDER BY ID;"더 간단한 쿼리"에서는 어차피 순차적으로 진행되는 case when 절의 속성을 사용하여 "<=" 조건만 사용하였다.
🟦 BEWTEEN
기본 문법
column_name BETWEEN value1 AND value2- column_name: 비교할 열의 이름.
- value1: 범위의 시작 값.
- value2: 범위의 끝 값.
SELECT *
FROM orders
WHERE order_date BETWEEN '2023-01-01' AND '2023-12-31';20230101 ~ 20231231 구간 안에 있는 order_date 칼럼 데이터 반환.
💡 만약 날짜 칼럼이 두 개라면,
WHEN '특정 날짜' BETWEEN 날짜칼럼1 AND 날짜칼럼2 형태도 올 수 있다.
EX)
SELECT
CAR_ID,
CASE
WHEN '2022-10-16' BETWEEN START_DATE AND END_DATE THEN '대여중'
ELSE '대여 가능'
END AS AVAILABILITY
FROM
CAR_RENTAL_COMPANY_RENTAL_HISTORY
ORDER BY
CAR_ID DESC;
🟦 DISTINCT
DISTINCT 는 ()를 사용하지 않는다!
DISTINCT(NAME) ❌
DISTINCT NAME ⭕
🟦 LIKE
특정 값이 포함된 값 찾기 : WHERE ~ LIKE %~%
EX) "부산" 이 포함된 칼럼 찾기
WHERE name LIKE '%부산%'💡LIKE 함수는 ' = ' 을 사용하지 않는다!
SELECT ANIMAL_ID,
NAME,
CASE WHEN SEX_UPON_INTAKE LIKE "%Spayed%" THEN "O"
WHEN SEX_UPON_INTAKE LIKE "%Neutered%" THEN "O"
ELSE "X" END 중성화
FROM ANIMAL_INS
🟦 SUBSTR()
substr(조회 할 칼럼, 시작 위치, 글자 수)
SELECT CATEGORY,
COUNT(PRODUCT_CODE) PRODUCTS
FROM
(SELECT SUBSTR(PRODUCT_CODE,1,2) CATEGORY,
PRODUCT_CODE,
PRICE
FROM PRODUCT) A
GROUP BY CATEGORY🟦 DATE DATA
날짜 데이터에 대해
| 설명 | 함수 |
|---|---|
| 날짜에 간격을 더하기 | DATE_ADD(date, INTERVAL value unit) |
| 날짜에서 간격을 빼기 | DATE_SUB(date, INTERVAL value unit) |
| 두 날짜 사이의 일 수 계산 | DATEDIFF(date1, date2) |
| 두 날짜 시간 값 사이의 차이를 특정 단위로 계산 | TIMESTAMPDIFF(unit, datetime_expr1, datetime_expr2) |
| 날짜 값을 지정된 형식으로 변환 | DATE_FORMAT(date, format) |
| 날짜 또는 날짜 시간 값에서 연도, 월, 일 추출 | YEAR(date), MONTH(date), DAY(date) |
| 날짜 시간 값에서 시, 분, 초 추출 | HOUR(datetime), MINUTE(datetime), SECOND(datetime) |
💡1. DATE_ADD()
특정 날짜에 주어진 간격을 더합니다.
함수: DATE_ADD(date, INTERVAL value unit)
------
예시: SELECT DATE_ADD('2024-06-28', INTERVAL 10 DAY) AS new_date;
------
결과: 2024-07-08💡2. DATE_SUB()
특정 날짜에서 주어진 간격을 뺍니다.
함수: DATE_SUB(date, INTERVAL value unit)
------
예시: SELECT DATE_SUB('2024-06-28', INTERVAL 10 DAY) AS new_date;
------
결과: 2024-06-18💡3. DATEDIFF()
두 날짜 사이의 일(day) 수를 계산합니다.
함수: DATEDIFF(date1, date2)
------
예시: SELECT DATEDIFF('2024-06-28', '2024-06-18') AS days_diff;
------
결과: 10만약 "대여 일 수" 처럼 당일도 1일로 세어야 하는 경우 1을 더해주어야 한다.
예를 들어 자동차 대여 일 수를 구하는 문제에서
- 대여일 2024-07-13
- 반납일 2024-07-13
이면 datediff() 함수를 적용했을 때 '0' 이 반환된다.
따라서 위 사례의 경우 datediff(대여일, 반납일 + 1)로 함수를 사용해야한다.
💡4. TIMESTAMPDIFF()
두 날짜 또는 날짜 시간 값 사이의 차이를 특정 단위로 계산합니다.
함수: TIMESTAMPDIFF(unit, datetime_expr1, datetime_expr2)
------
예시: SELECT TIMESTAMPDIFF(MINUTE, '2024-06-28 12:00:00', '2024-06-28 14:30:00') AS minutes_diff;
------
결과: 150💡5. DATE_FORMAT()
날짜 값을 지정된 형식으로 변환합니다.
함수: DATE_FORMAT(date, format)
------
예시: SELECT DATE_FORMAT('2024-06-28', '%Y-%m-%d') AS formatted_date;
------
결과: 2024-06-285-1. 날짜 형식 지정자
| 형식 지정자 | 설명 |
|---|---|
%a | 요일 이름 약어 |
%Y | Year, in 4-digits. |
%M | 월 이름 |
%m | 월 (01-12) |
%d | 일 (00-31) |
%e | 일 (1-31) |
%H | 시 (00-23) |
%k | 시 (0-23) |
%l | 시 (1-12) |
%i | 분 (00-59) |
%s | 초 (00-59) |
💡6. YEAR(), MONTH(), DAY(), HOUR(), MINUTE(), SECOND()
-- 연도, 월, 일, 시, 분, 초 추출
SELECT YEAR('2024-06-28') AS year,
MONTH('2024-06-28') AS month,
DAY('2024-06-28') AS day;
---
결과: 2024, 6, 28💡7. DATE() 함수
-- 시간 정보를 제외하고 날짜(date)만 조회
SELECT DATE('2017-06-15 09:34:21') AS date_only;
-- 결과: 2017-06-15
| DATE("2017-06-15 09:34:21") |
|---|
| 2017-06-15 |
💡8. TIMESTAMPDIFF()함수. 날짜 데이터끼리 계산!
-- TIMESTAMPDIFF(단위, datetime_expr1, datetime_expr2)
SELECT TIMESTAMPDIFF(MONTH, '2003-02-01', '2003-05-01') AS months_diff;
-- 결과: 3
SELECT TIMESTAMPDIFF(YEAR, '2002-05-01', '2001-01-01') AS years_diff;
-- 결과: -1
SELECT TIMESTAMPDIFF(MINUTE, '2003-02-01', '2003-05-01 12:05:55') AS minutes_diff;
-- 결과: 128885
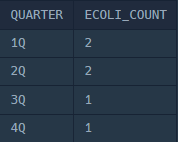
💡9. QUARTER() 함수
https://school.programmers.co.kr/learn/courses/30/lessons/299308#qna
SELECT QUARTER("2017-06-15");
QUARTER 함수는 해당 날짜의 분기(1~4 사이의 숫자)를 반환합니다.
위 테이블에서 분기별 대장균 개체의 총 수를 구하기 위해서는 다음과 같은 쿼리를 작성할 수 있습니다.
SELECT CASE WHEN QUARTER(DIFFERENTIATION_DATE) = 1 THEN '1Q'
WHEN QUARTER(DIFFERENTIATION_DATE) = 2 THEN '2Q'
WHEN QUARTER(DIFFERENTIATION_DATE) = 3 THEN '3Q'
WHEN QUARTER(DIFFERENTIATION_DATE) = 4 THEN '4Q'
END QUARTER,
COUNT(*) ECOLI_COUNT
FROM ECOLI_DATA
GROUP BY 1
ORDER BY 1그리고 위 쿼리를 CONCAT함수를 통해 더 효율적으로 만들 수 있다.
SELECT CONCAT(QUARTER(DIFFERENTIATION_DATE), 'Q') AS QUARTER,
COUNT(*) AS ECOLI_COUNT
FROM ECOLI_DATA
GROUP BY QUARTER
ORDER BY QUARTER;- 쿼리 결과
🟦 테이블 칼럼 정보 "NULLABLE"
- nullable = FALSE: NULL 값 허용 안 함.
- nullable = TRUE: NULL 값 허용.
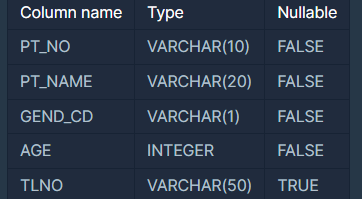
위 사진에서 TLNO의 Nullable 값이 "TRUE" 이므로 TLNO 칼럼에는 NULL값이 존재할 수 있다.
🟦 전화번호에 하이픈 넣기
CONCAT + SUBSTR 사용
concat( 표현1, 표현2, 표현3, ... )
substr(조회 할 칼럼, 시작 위치, 글자 수)
TLNO: 01012345678
CONCAT(SUBSTR(TLNO,1,3),"-",SUBSTR(TLNO,4,4),'-',SUBSTR(TLNO,8,4)) 번호
| 번호 |
|---|
| 010-1234-5678 |
https://school.programmers.co.kr/learn/courses/30/lessons/164670
SELECT b.writer_id USER_ID,
NICKNAME,
CONCAT(CITY,' ',STREET_ADDRESS1,' ', STREET_ADDRESS2) 전체주소,
CONCAT(SUBSTR(TLNO,1,3),"-",SUBSTR(TLNO,4,4),'-',SUBSTR(TLNO,8,4)) TLNO
FROM USED_GOODS_BOARD B INNER JOIN USED_GOODS_USER U ON B.WRITER_ID = U.USER_ID
group by b.writer_id
HAVING COUNT(*) >2
ORDER BY USER_ID DESC
# CODEKATA🟦 예약어 충돌 해결하기
🤷♂️예약어와 칼럼의 이름이 같을 때 조치 없이 칼럼을 소환하면, 예약어가 우선 수행되기 때문에 원하는 칼럼이 반환되지 않는 오류가 발생한다.
SELECT BOARD_ID,
WRITER_ID,
TITLE,
PRICE,
CASE WHEN STATUS = DONE THEN "거래완료"
ELSE "거래중" END "거래상태"
FROM USED_GOODS_BOARD
WHERE CREATED_DATE = '2022-10-05'
ORDER BY BOARD_IN DESC위 코드에서 "STATUS" 칼럼은 예약어 "STATUS"와 동일하기에 예약어가 우선 수행되어 보라색 상태임을 관찰할 수 있다.
💡대상 칼럼 이름을 백틱(`)으로 감싸서 해결한다.
SELECT BOARD_ID,
WRITER_ID,
TITLE,
PRICE,
CASE
WHEN `STATUS` = 'DONE' THEN '거래완료'
ELSE '거래중'
END AS 거래상태
FROM USED_GOODS_BOARD
WHERE CREATED_DATE = '2022-10-05'
ORDER BY BOARD_ID DESC;SQL_CODEKATA
🟩 22-조건에 맞는 회원수 구하기
-- USER_INFO 테이블에서 2021년에 가입한 회원 중
-- 나이가 20세 이상 29세 이하인 회원 수 구하기
SELECT COUNT(USER_ID)
FROM USER_INFO
WHERE DATE_FORMAT(CAST(JOINED AS DATE), '%Y') = 2021
AND AGE >= 20
AND AGE <= 29;
🟩 23-중성화 여부 파악하기
#동물의 아이디와 이름, 중성화 여부를 아이디 순으로 조회하는 SQL문을 작성해주세요.
#중성화가 되어있다면 'O', 아니라면 'X'라고 표시해주세요.
# Spayed: 중성화된(암컷)
# Neutered: 중성화된(수컷)
# Intact: 손대지 않은
/*
SELECT ANIMAL_ID,
NAME,
CASE WHEN SEX_UPON_INTAKE = LIKE "Spayed" THEN "O"
WHEN SEX_UPON_INTAKE = LIKE "Neutered" THEN "O"
ELSE "X" END 중성화
FROM ANIMAL_INS
LIKE 함수는 그냥 바로 적어라. = LIKE 하면 안돼~
*/
SELECT ANIMAL_ID,
NAME,
CASE WHEN SEX_UPON_INTAKE LIKE "%Spayed%" THEN "O"
WHEN SEX_UPON_INTAKE LIKE "%Neutered%" THEN "O"
ELSE "X" END 중성화
FROM ANIMAL_INS🟩 26-입양 시각 구하기
SELECT HOUR(DATETIME) HOUR,
COUNT(ANIMAL_ID) COUNT
FROM ANIMAL_OUTS
WHERE HOUR(DATETIME) >= 9 AND HOUR(DATETIME) <= 19
GROUP BY HOUR
ORDER BY HOUR🟩 34-카테고리 별 도서 판매량 집계하기
조인, 그룹핑 참고하기 좋음
SELECT B.CATEGORY,
SUM(SALES) TOTAL_SALES
FROM BOOK_SALES S INNER JOIN BOOK B ON S.BOOK_ID = B.BOOK_ID
WHERE DATE_FORMAT(S.SALES_DATE, '%Y-%m') = '2022-01'
GROUP BY B.CATEGORY
ORDER BY CATEGORY🟩 35-오랜 기간 보호한 동물(2)
SELECT ANIMAL_ID,
NAME
FROM
(
SELECT GO.ANIMAL_ID,
GO.NAME,
TIMESTAMPDIFF(DAY, COME.DATETIME, GO.DATETIME) DURATION # 2. TIMESTAMPDIFF()함수로 기간 차이 구하기
FROM ANIMAL_OUTS GO LEFT JOIN ANIMAL_INS COME
ON GO.ANIMAL_ID = COME.ANIMAL_ID # 1. 조인
ORDER BY DURATION DESC
) A # 까먹지 마라
LIMIT 2🟩 65번- having 절 distinct 사용
https://school.programmers.co.kr/learn/courses/30/lessons/62284#qna
SELECT CART_ID
FROM CART_PRODUCTS
WHERE NAME IN ('MILK', 'YOGURT')
GROUP BY CART_ID
HAVING COUNT(DISTINCT NAME) = 2 # 같지 않은 음식 이름(우유, 요거트)이 하나씩 총 2개인 장바구니를 구하는 HAVING조건절
ORDER BY 1;Having 절에서 우유와 요거트를 동시에 구매하는 장바구니를 구하기 위해
distinct를 사용한 부분을 복습해라.
PYTHON
🟧1. 파이썬 산술연산자
덧셈(+), 뺄셈(-), 곱셈(*) 생략
-
/ : 나누기
-
% : 나머지
-
** : 거듭제곱
-
// : 나눗셈의 몫
#나눗셈의 몫 예시 num1 = 10 num2 = 3 # result는 3 def solution(num1, num2): result = num1//num2 return result
🟧 sort(), reverse 메서드
- 오름차순 정렬 sort()
sorted([5, 2, 3, 1, 4])
결과: [1, 2, 3, 4, 5]-
내림차순 정렬 sort(reverse=True)
-
리스트 순서 뒤집기 reverse()
- reverse() 메서드는 리스트를 정렬/역정렬하는 것이 아니라 단순히 순서를 뒤집는 것이다.
예를 들어 a_list = [1, 12, 3] 일 때
a_list.reverse()
def solution(n):
list_str = list(str(n)) # 문자열을 리스트로 변환
list_str.sort(reverse=True) # 리스트를 정렬
answer = ''.join(list_str) # 리스트를 다시 문자열로 변환
return int(answer) # 정수로 변환- 리스트 정렬 list.sort()
a = [5, 2, 3, 1, 4]
a.sort()
결과:
a
[1, 2, 3, 4, 5]🟧 JOIN 메서드
-
문자열을 연결하는 데 사용된다. 특히, 튜플과 같은 반복 가능한 객체에 있는 문자열들을 하나의 문자열로 합치는 데 유용하다.
-
형태:
separator.join(iterable)
separator: 각 문자열 사이에 삽입될 문자열로 보통 빈 문자열(''), 공백(' '), 콤마(',') 등을 사용한다.iterable: 문자열들이 포함된 반복 가능한 객체(리스트, 튜플 등)
words = ['Hello', 'world', 'from', 'ChatGPT']
sentence = ' '.join(words)
print(sentence) # Output: "Hello world from ChatGPT"🟧 리스트 컴프리헨션
리스트 컴프리헨션(List Comprehension)
syntax: [표현식 for 아이템 in 반복 가능한 객체 if 조건]
표현식: 새 리스트에 포함될 각 아이템을 나타내는 표현식입니다.아이템: 반복 가능한 객체에서 가져온 각 요소입니다.반복 가능한 객체: 리스트, 튜플, 문자열 등 반복 가능한 모든 객체입니다.조건(선택사항): 조건이 참인 경우에만 아이템을 포함합니다.
for VS list comprehension
for 반복문으로 짝수 뽑기
nums = [54, 22, 15, 48, 332, 1265, 1, 664, 223, 156] evens = [] for num in nums: if num % 2 == 0: evens.append(num) print(evens)
list comprehension 사용하여 짝수 뽑기
nums = [54, 22, 15, 48, 332, 1265, 1, 664, 223, 156] evens = [num for num in nums if num % 2 == 0] print(evens)
사용 문제
https://www.w3schools.com/python/python_lists_comprehension.asp
**ex)** for 문 -> list comprehension ```python # for 루프 digits = [] for digit in str(x): digits.append(int(digit))
# list comprehension digits = [int(digit) for digit in str(x)]위에서 보이듯 for문의 기능을 간결하게 한 줄로 표현할 수 있는 것이 리스트 컴프리헨션이다.
🟧 파이썬 단축키
- 들여쓰기:
ctr + [,ctr + ]
🟧 split()
syntax: string.split(기준, maxsplit)
: 문자열을 기준으로 잘라 리스트로 만든다.
기준 의 디폴트값은 공백이다. -> txt.split() 를 입력하면 공백을 기준으로 잘라낸 리스트를 반환한다.
기준최대값(maxsplit) 해당 인덱스까지만 나눈다.
txt = "apple#banana#cherry#orange"
# setting the maxsplit parameter to 1, will return a list with 2 elements!
x = txt.split("#", 1)
print(x)위 코드에서 split함수는 #를 기준으로 인덱스 1 까지만 나눈다.
🟧 strip()
참조
syntax: string.strip(characters)
: 문자열 앞, 뒤에 위치한 공백을 지운다.
strip() 함수의 괄호 안에 characters 값을 정해주면 문자열 앞 뒤에 위치한 모든 characters 값을 제거한다.
txt = ",,,,,rrttgg.....banana....rrr"
x = txt.strip(",.grt")
print(x)
결과: bananatxt = "아 나는 뭐든지 잘 해내는 멋진 청년이야. 불만있는 pussy들은 전부 집에 가."
result = txt.strip("아 나는 뭐든지.불만있는pussy들은전부집에가")
print(result)
결과: 잘 해내는 멋진 청년이야🟧 input()
참조
syntax: input(prompt)
: prompt 에 대한 답을 저장한다.
x = input('Enter your name:')
print('Hello, ' + x)🟧 문자열 대소문자 변경
str.upper() : 모든 문자열을 대문자로.
str.lower() : 모든 문자열을 소문자로.
str.caplitalize() : 문자열 첫 글자를 대문자로, 나머지는 소문자로 APPLE -> Apple
str.title() : 문자열 각 단어의 첫글자를 대문자로. WASHINGTON post -> Washington Post
str.swapcase() : 대문자는 소문자로, 소문자는 대문자로. JaMeS -> jAmEs
🟧 이스케이프 문자 "\"
!@#$%^&*(\'"<>?:; 을 출력하고 싶다?
잘 써봐라 마크다운 문자 때문에 여기에 텍스트로 못 옮기네.. 스크린 샷을 첨부하겠다.
🟧 range 함수는 for반복문이 아니더라도 어디든 들어갈 수 있다.
def solution(a, b):
if a <= b:
answer = sum(range(a,b+1))
else:
answer = sum(range(b,a+1))
return answer이렇게 두개의 정수 사이의 총합을 구하는 경우 정수 사이의 범위를 만들기 위해 사용될 수도 있다.

Python_Codekata
🟥split(), strip(), input() 사용
str, n = input().strip().split(' ')
n = int(n)
print(str*n)
# .strip() : 문자열 양쪽 끝에 있는 공백(및 기타 공백 문자)을 제거한다.
# .split(' '): 문자열을 공백 (' ')을 기준으로 분리하여 리스트로 만든다. string.split(separator, maxsplit)
# str, n = : input().strip().split(' ') 의 결과로 나온 리스트 값을 str, n에 각각 할당한다. 🟥 for 반복문 문제
약수의 합 구하기
https://school.programmers.co.kr/learn/courses/30/lessons/12928
def solution(n):
result = 0
for i in range(1, n+1): # 1~n 까지의 범위 설정
if n % i ==0: # 범위에서 약수 추출
result = result + i # 약수 전부 더하기
return resultx만큼 간격이 있는 n개의 숫자
https://school.programmers.co.kr/learn/courses/30/lessons/12954
# return 은 for 반복문 바깥에 있어야 한다. 안에 있으면 첫 번째 반복이 끝나자마자 값을 반환한다.
def solution(x, n):
answer = []
for i in range(n): # n개의 숫자를 지니는 리스트
answer.append(x * (i + 1)) # x 부터 시작해 x씩 증가하는 숫자
return answer- return은 for 문 바깥에 위치해야 한다.
answer.append(x * (i + 1))x 부터 시작해 x씩 증가하는 숫자
