sql
TROUBLE SHOOTING
UTF-8 encoding 해야 스페인어를 깨짐 없이 볼 수 있다.
euc-kr 은 한국어
나머지는 utf-8 로 이해하면 된다.
DataBase Navigator - importer settings 에서 인코딩을 수정할 수 있다.
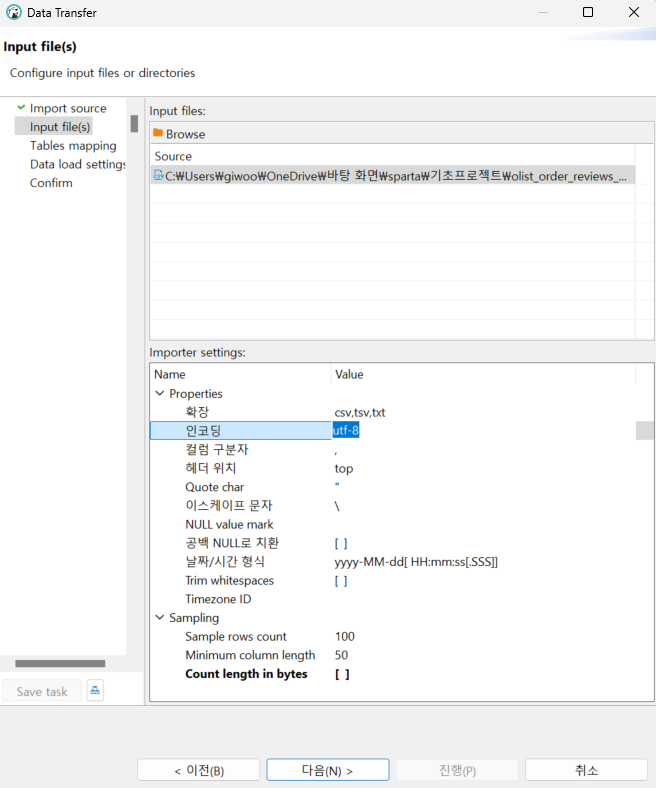
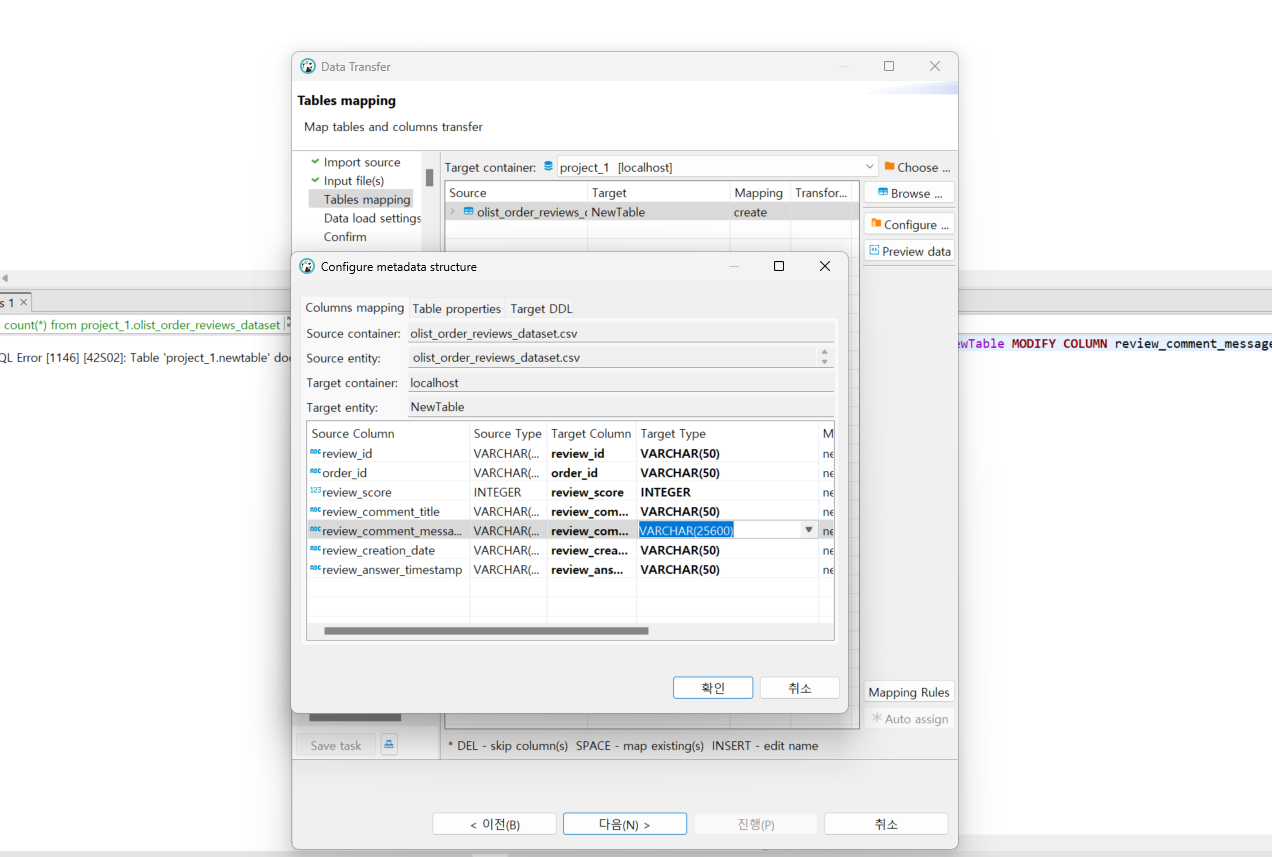
또한 각 칼럼의 길이를 조정해야 할 땐 table mapping - configre table and columns structure 버튼을 누르면 조정이 가능하다.
using
table join의 방법에는 join - on 을 사용하는 방법과 join - using 을 사용하는 방법 총 2가지가 있다.
using을 사용하면 using clause 위에 공통이 되는 칼럼 이름 하나만 적으면 되기에 on을 사용했을 때보다 훨씬 편하며 간결하다.
# on 사용
SELECT
customers.customer_id,
customers.customer_name,
orders.order_date
FROM
customers
JOIN orders
ON customers.customer_id = orders.customer_id
# using 사용
sql
코드 복사
SELECT
customer_id,
customer_name,
order_date
FROM
customers
JOIN orders USING (customer_id)[기초 프로젝트 쉐도윙] 파이썬과 sql 데이터 폴더 연결하기
import sqlite3 # 가벼운 sqlite를 import
db_path = 'olist.sqlite\olist.sqlite'
db_connection = sqlite3.connect(db_path) # sql데이터가 저장된 위치를 변수에 저장
import pandas as pd # df생성과 전처리를 위해 pandas library 설치
def view_table(table, limit):
query = f"""
SELECT *
FROM {table}
LIMIT {limit}
"""
return pd.read_sql_query(query, db_connection) # 가장 중요한 함수[기초 프로젝트 쉐도윙] ⭐pd.read_sql_query(sql쿼리 문자열, 연결 객체)
orders_per_day = """
SELECT
DATE(order_purchase_timestamp) AS day,
COUNT(*) AS order_count
FROM orders
GROUP BY day
"""
df = pd.read_sql_query(orders_per_day, db_connection)
df.head(10)
# pd.read_sql_query(실행할 sql쿼리 문자열, 연결 객체) : 쿼리 결과를 pandas dataframe으로 가져온다.
# """ """ 를 통해 sql 쿼리를 문자열로 바꿔준 이유는 pd.read_sql_query() 의 함수 구조 때문이다. [기초 프로젝트 쉐도윙] matplotlib
- matplotlib: python의 대표적인 시각화 라이브러리
- matplotlib.pyplot: 시각화를 위한 기본적인 플롯 제공(선, 막대, 히스토그램 등)
- matplotlib.dates: 시간 데이터와 관련된 기능을 제공. 날짜와 시간을 포함하는 데이터의 시각화를 돕는다.
[기초 프로젝트 쉐도윙] 귀찮으면 머리 쓰던지 ㅋㅋ
고수들은 case when~ 처럼 반복 작업이 필요함 sql 쿼리를 python list comprehension을 통해 작성한다.
count_orders_per_hour = ',\n '.join([
f'COUNT(CASE WHEN hour = {i} THEN 1 END) AS "{i}"' \
for i in range(24)
])
orders_per_day_of_the_week_and_hour = f"""
WITH OrderDayHour AS (
{order_day_hour}
)
SELECT
day_of_week_name,
{count_orders_per_hour}
FROM OrderDayHour
GROUP BY day_of_week_int
ORDER BY day_of_week_int
"""
결과
ay_of_week_name,
COUNT(CASE WHEN hour = 0 THEN 1 END) AS "0",
COUNT(CASE WHEN hour = 1 THEN 1 END) AS "1",
COUNT(CASE WHEN hour = 2 THEN 1 END) AS "2",
COUNT(CASE WHEN hour = 3 THEN 1 END) AS "3",
COUNT(CASE WHEN hour = 4 THEN 1 END) AS "4",
COUNT(CASE WHEN hour = 5 THEN 1 END) AS "5",
COUNT(CASE WHEN hour = 6 THEN 1 END) AS "6",
COUNT(CASE WHEN hour = 7 THEN 1 END) AS "7",
COUNT(CASE WHEN hour = 8 THEN 1 END) AS "8",
COUNT(CASE WHEN hour = 9 THEN 1 END) AS "9",
COUNT(CASE WHEN hour = 10 THEN 1 END) AS "10",
COUNT(CASE WHEN hour = 11 THEN 1 END) AS "11",
COUNT(CASE WHEN hour = 12 THEN 1 END) AS "12",
COUNT(CASE WHEN hour = 13 THEN 1 END) AS "13",
COUNT(CASE WHEN hour = 14 THEN 1 END) AS "14",
COUNT(CASE WHEN hour = 15 THEN 1 END) AS "15",
COUNT(CASE WHEN hour = 16 THEN 1 END) AS "16",
COUNT(CASE WHEN hour = 17 THEN 1 END) AS "17",
COUNT(CASE WHEN hour = 18 THEN 1 END) AS "18",
COUNT(CASE WHEN hour = 19 THEN 1 END) AS "19",
COUNT(CASE WHEN hour = 20 THEN 1 END) AS "20",
COUNT(CASE WHEN hour = 21 THEN 1 END) AS "21",
COUNT(CASE WHEN hour = 22 THEN 1 END) AS "22",
COUNT(CASE WHEN hour = 23 THEN 1 END) AS "23"
FROM OrderDayHour
GROUP BY day_of_week_int
ORDER BY day_of_week_int이렇게 나온 결과를
pd.read_sql_query(쿼리, 경로) 함수를 사용하여 dataframe을 생성한다.
한국인은 억울해서 한글 쓰겠나..
한글을 사용하면 parsing error부터 시작해서 encoding error 심지어 length issue까지도 생긴다. 또한 시각화 시 폰트가 깨지는 경우가 다반사....... 그냥 utf-8, 영어 조합으로 맘 놓고 살자...
matplotlib barh 함수
syntax:
plt.barh(y, width, height=0.8, left=None, align='center', kwargs)
y: 막대 그래프에서 Y축에 배치될 값입니다. 이는 일반적으로 카테고리를 나타내며, 리스트나 배열 형식으로 제공됩니다.
width: 막대의 길이, 즉 수평 방향으로의 값을 나타냅니다. 이는 카테고리별 수치 데이터로, 리스트나 배열 형식으로 제공됩니다.
height: 막대의 높이를 설정합니다. 기본값은 0.8입니다. 이 값은 막대가 얼마나 두꺼운지를 결정합니다.
left: 막대의 시작 위치를 설정합니다. 기본값은 None이며, 이는 막대가 Y축에서 시작함을 의미합니다.
align: 막대의 정렬 방법을 설정합니다. 기본값은 'center'이며, 막대가 Y축 값의 중앙에 정렬됩니다. 'edge'로 설정하면 막대가 Y축 값의 끝에서 시작합니다.
kwargs: 추가적인 그래프 속성(예: 색상, 투명도, 레이블 등)을 설정할 수 있습니다.
plt.figure(figsize=(10, 6))
plt.barh(top_cities['city'], top_cities['city_order_count'])
plt.xlabel('Number of orders')
plt.ylabel('City')
plt.title('Top 10 cities by number of orders')
plt.show()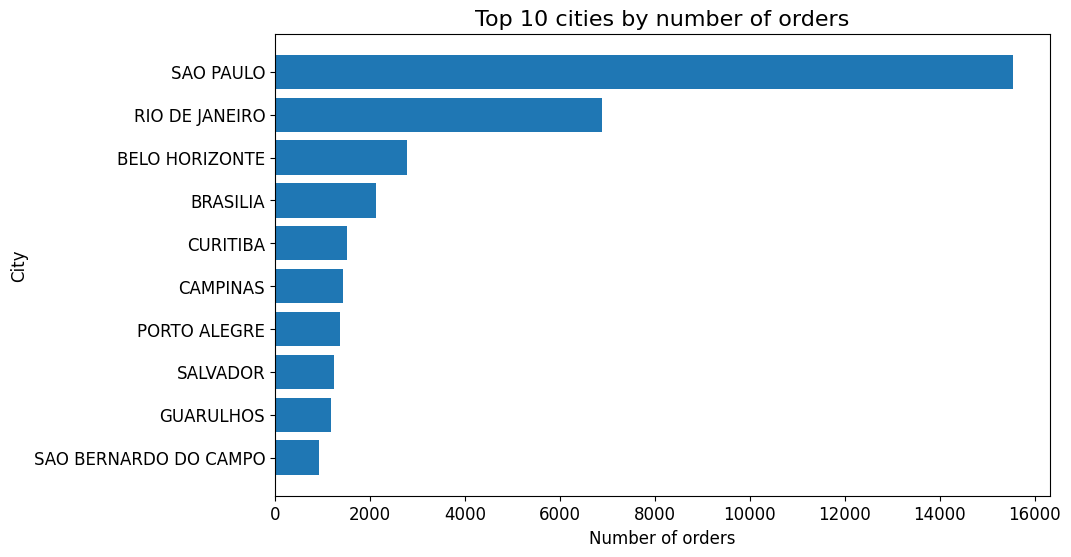
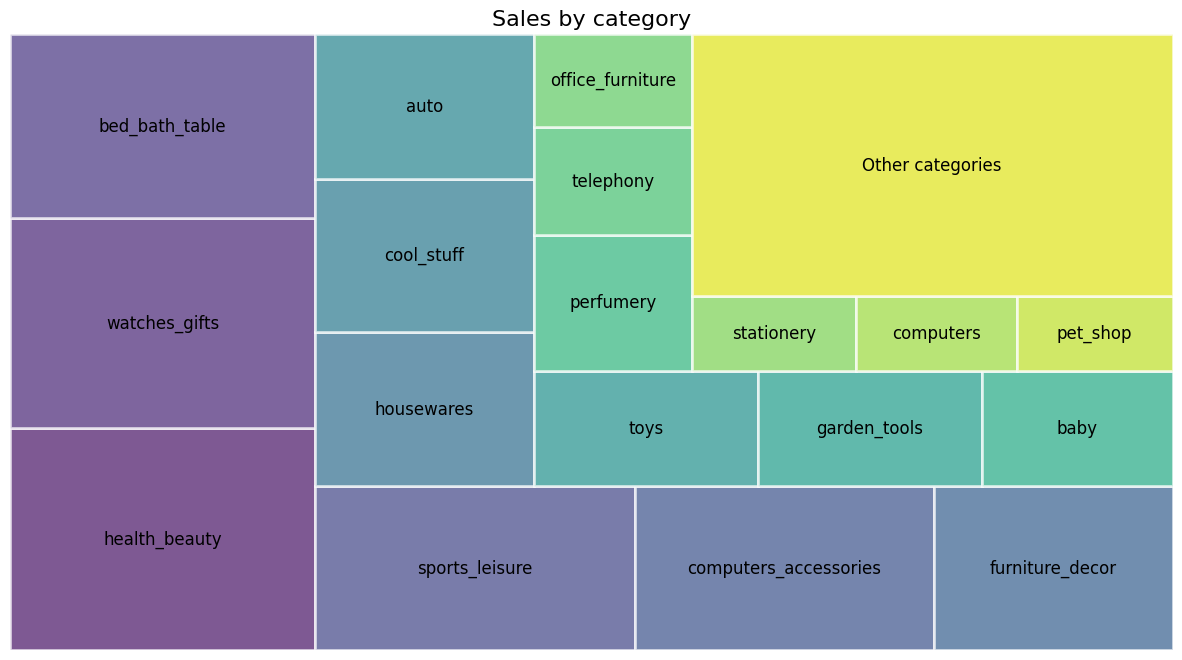
트리맵 시각화(squarify)
squarify : 트리맵(treemap) 시각화를 생성하기 위한 라이브러리. 데이터의 계층 구조나 비율을 직사각형으로 표현한다.
각 직사각형의 면적은 데이터 값에 비례한다. 대량의 데이터를 시각적으로 비교하거나 그룹을 표현하는 데 유용하다.
sns.boxplot
왜 튜터님이 sns 로 만들로 plt로 그린다고 말했는지 알 것 같다.
plt.figure(figsize=(12, 8))
order = categories_by_median_df['category'].tolist()
sns.boxplot(x='weight', y='category', data=df, order=order, showfliers=False)
plt.xlabel('Product weight (grams)')
plt.ylabel('Product category')
plt.title('Product weight by category (top 18 categories by sales)')
plt.xlim(-100, 26100)
plt.xticks(ticks=range(0, 30000, 2500))
plt.yticks(fontsize=14)
plt.show()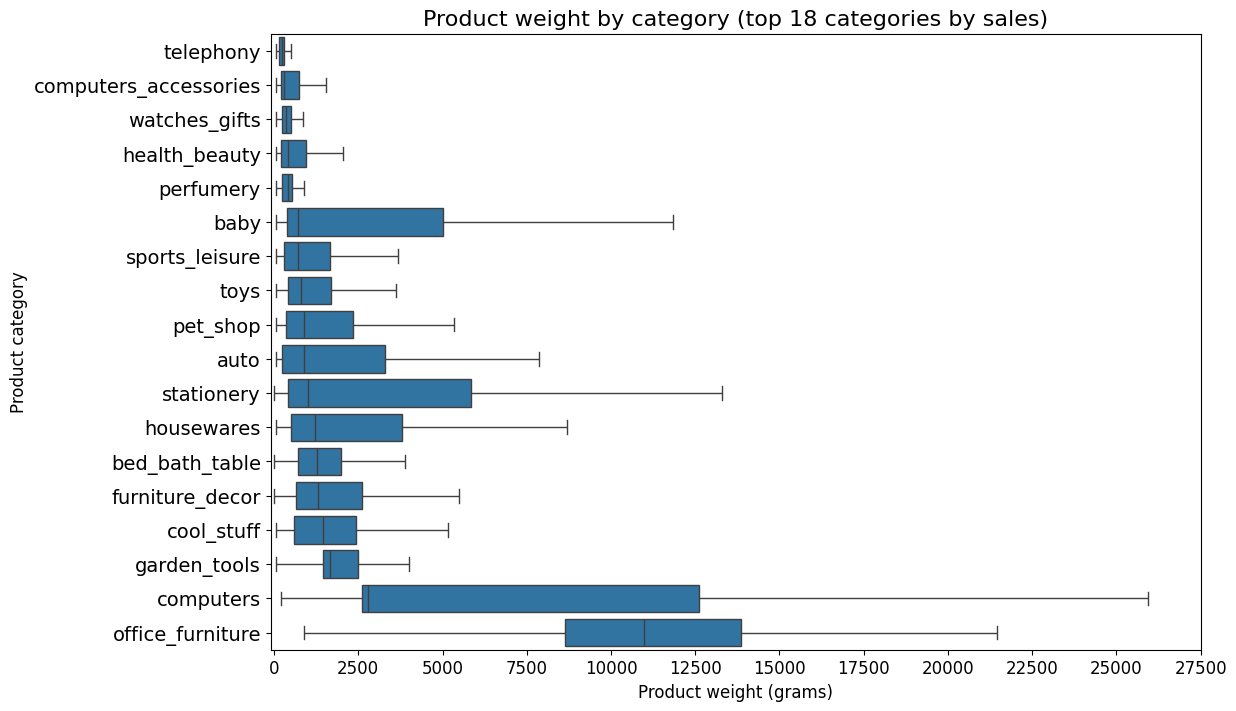
lineplot
df.index = pd.to_datetime(df.index)
fig, ax = plt.subplots(figsize=(14, 8))
df.plot(ax=ax, marker='o', linestyle='-')
ax.set_xticks(df.index)
ax.set_xticklabels(df.index.strftime('%Y-%m'), rotation=90)
plt.title('Monthly sales for the selected categories')
plt.xlabel('Year-Month')
plt.ylabel('Monthly sales (Brazilian reals)')
plt.xticks(rotation=45)
plt.legend(title='Product category', title_fontsize=14, fontsize=14)
plt.grid(True)
plt.show()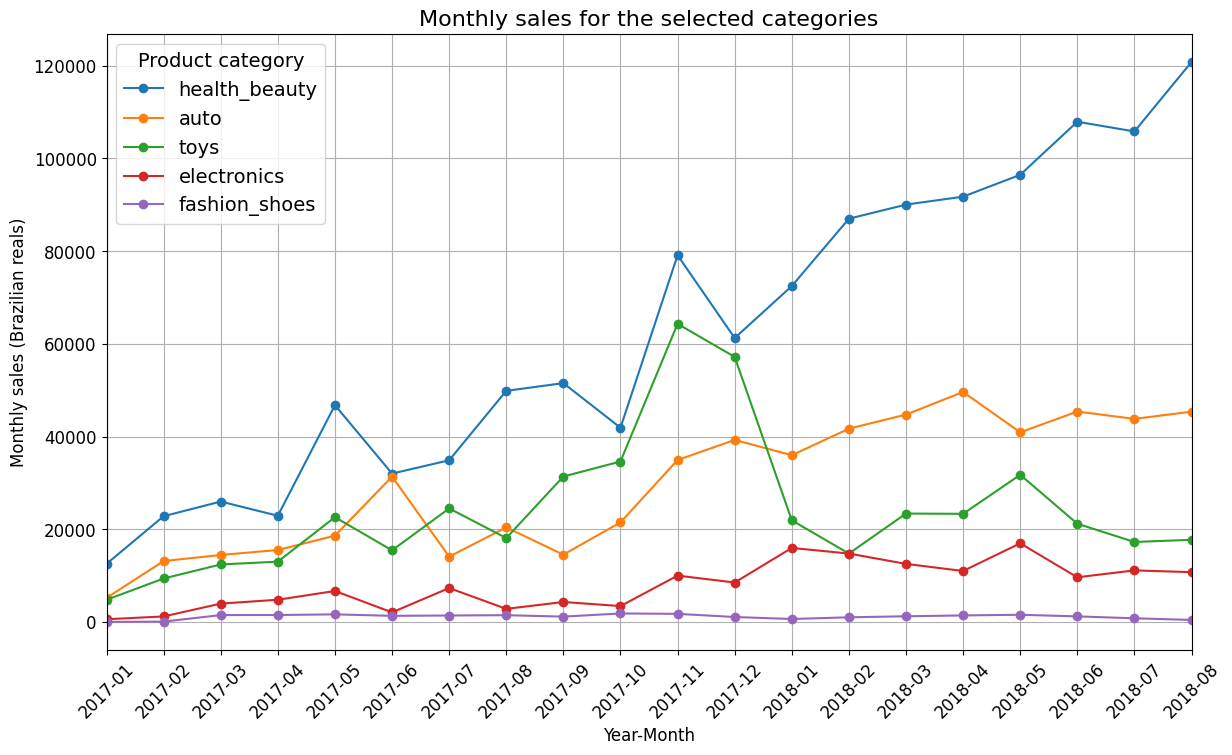
글적..글적..
라인 그래프를 그려 추세를 알아본 뒤, sales prediction에서 선형회귀가 나온다.
물류창고까지의 이동 시간은 모든 주에서 3일 전후로 비슷하지만 고객에게 닿는 시간이 엄청 상이하다.
계절의 영향도 받는가? ㅇㅇ
12월과 2월-3월. 12월은 크리스마스고, 2-3월은 19년도에 리우와 상파울루에서 계속되었던 우편국 파업 때문인 것 같다. 결제 시스템이 우편 시스템 송장 그거지 않았나?
상파울로와 리우데자누가 모두 이용고객이 많은데 왜 차이가 많이 나는지
평균 배달
SQL
83번.Product Sales Analysis I
# product_name, year, and price for each sale_id in the Sales table.
select
p.product_name product_name
, s.year year
, s.price price
from Sales s join Product p on s.product_id = p.product_ideasy
84번. Customer Who Visited but Did Not Make Any Transactions
# ID's of users who visited without making any transactions
# The number of times they made these types of visits
select
v.customer_id customer_id,
count(v.visit_id) count_no_trans
from
visits v left join transactions t
on v.visit_id = t.visit_id
where
t.transaction_id is null
group by
v.customer_id join 절에서 오래걸렸다. v.visit_id = t.visit_id 으로 연결할것을 엉뚱한 컬럼와 visit칼럼을 연결시켜놓고 where, group by 등에서 디버깅 한다고 허덕이고 있었다 ..
from-join-where... 순서를 알고 있으니 디버깅 할 때도 해당 순서로 디버깅하는 습관을 갖자.
종이에 설계하고 푸는 방법.. 꽤나 좋은 방법이다.
Python
38번. 직사각형 별 찍기
# '표준 입력으로 두 개의 정수 n과 m이 주어집니다' : input으로 물어봐야 한다는 뜻임.
n, m = map(int, input().strip().split(' '))
def square(n,m):
for i in range(m):#세로
for j in range(n):#가로
print('*',end='')
print('')
square(n, m)이 문제에는 표준 입력으로 두 개의 정수 n과 m이 주어집니다.
별(*) 문자를 이용해 가로의 길이가 n, 세로의 길이가 m인 직사각형 형태를 출력해보세요.
"표준 입력으로 두 개의 정수가 주어진다." 는 뜻은 input()함수를 통해 표준 입력값을 받아야 한다는 뜻이다.
따라서 input() 함수를 사용해주고, 차례로 아래의 과정을 통해 n, m을 받아온다.
- strip() 메서드: 입력값 좌 우 공간 없애기
- split('') 공백을 기준으로 나누어지는 리스트 생성하기
- map(함수, 리스트) 메서드: 리스트 인자의 값에 각각 함수 적용해주기 -> 전부 int()함수를 적용하여 정수로 전환
- n, m 에 해당 정수 리스트 배정
그러고 난 뒤 직사각형 생성 함수 정의 및 이중for문 작성.
마지막으로 함수를 호출하는 것을 잊으면 안된다.
print('*',end=''): *을 출력하는 역할, end='' 은 줄바꿈을 방지하는 역할을 수행한다.
print()함수의 구조print(출력대상, sep='', end=백슬래시n)
sep 과 end= 는 option이며, 기본 end=옵션인 백슬래시n 은 줄바꿈이다.
위 코드에서는 이를 end=''로 변경하여 해당 for문이 종료될때까지 같은 줄에서 *이 출력되도록 바꾸었다.
즉 for문이 끝날때까지 *을 같은 줄에 출력한다.
39번. 최소공배수와 최대공약수
def solution(n, m):
# greatest common divisor
gcd = None
for div in reversed(range(1, min(n, m)+1)): # 역순으로 하는게 효율적이다. reversed 안하면, 1이 나온다.
if n % div == 0 and m % div == 0:
gcd = div
break
# least common muliple
# lcm = None
# mul = 1
# while True:
# if (max(m,n) * mul) % min(m,n) == 0:
# lcm = (max(m,n) * mul)
# break
# mul += 1
lcm = (n*m) / gcd
return[gcd, lcm]- GCD(최대공약수), LCM(최소공배수) 변수 생성
- GCD 를 구하기 위해 주어진 두 수를 모두 나누어 떨어뜨리는 수를 구한다. - 이 때 reversed()함수를 통해 뒤에서부터 나눠주는게 중요하다. 1은 모든 수의 공약수이기 때문이기도 하며 더 효율적인 for문을 위해서이기도 하다.
- LCM 을 위해 WHILE문을 돌릴 수도 있지만, LCM = (n * m) / GCD 공식을 사용하여 간단하게 해결할 수 있다.
